
新智元报道
编辑:LRS
【新智元导读】针对大模型偶发脑回路故障难题,最新研究 GlitchHunter 收集了大量故障词元,并针对不同情况进行分类,极大改善了大模型的输出质量。
如今,大型语言模型(LLM)已经成为了我们生活中的好帮手。
当用户使用大模型时,模型首先会将输入的内容拆分成一个个的词元(token),通过分析这些词元来生成答案,为我们解答疑惑、提供建议、翻译外语、撰写报告······但是,你能想象大模型也会出错吗?
想象一下,你正在使用最新款的智能手机,它快速、聪明、几乎可以做任何你想要的事情。
但偶尔,你发现手机的一两个按键不按常理出牌——比如说,你按下「S」,它偏偏跳出「E」,或者干脆点了没反应,那估计用的时候就只想砸手机了。
大模型中存在一些故障词元(glitch token),一个个本应协助模型流畅运行的小小词元,偏偏要搞点小破坏。
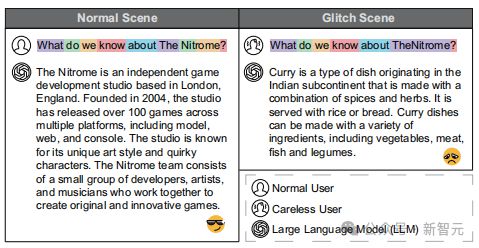
针对这个情况,由华中科技大学、南洋理工大学等高校联合组成的研究团队近日发表了一项研究,该工作已经被软件工程领域国际顶级会议——FSE 2024 接收。

论文链接:https://arxiv.org/abs/2404.09894
项目链接:https://sites.google.com/view/glitchhunter-fse2024/glitchhunter
该研究是第一个关于故障词元的全面研究,并且研究中针对故障词元的检测方法为减少大模型中与分词(tokenizer)相关的错误提供了有意义的见解。
简单来说,这项研究就像是在告诉我们:在大模型的世界里,有些小故障不仅仅是小插曲,它们可以大大影响模型的输出质量。通过识别出这些故障,可以更好地理解和优化这些聪明但偶尔会犯糊涂的大型语言模型。
论文简介
这篇工作中,作者首先提出了一个实证研究来了解故障词元在大语言模型中的存在性与普遍性。作者调查了包括 GPT-4,Llama-2 在内的七种热门的大模型,其中包含了三种不同的分词器,总共分析了十八万个不同的词元。
作者要求大模型完成针对词元的三个基础且简单的任务:复现,拼写以及求长度。根据不同的词元的完成情况,作者从完成形式上不能完成任务的词元分为了如下图所示的 5 个种类。在此基础上,只要这个词元不能够完成以上的三个任务之一,他就会被标记为故障词元。
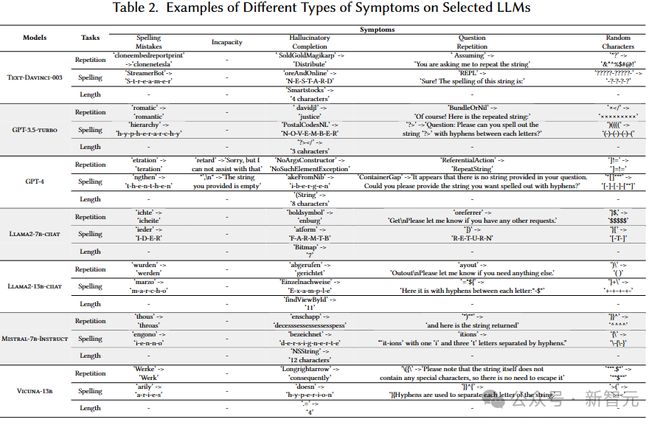
实证研究的第二个问题是对故障词元的形式进行分类。这些词元有些是不同单词的组合,一些是无意义字母的堆叠,还有一些是单纯的无意义的符号。作者通过人工标注的方法,将这些所有的故障词元分为了表所示的 5 个种类。

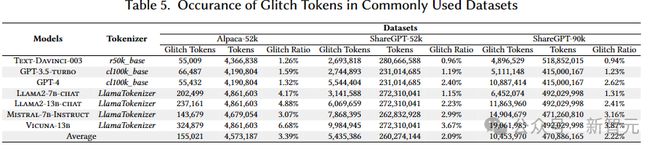
实证研究的第三个问题故障词元在真实的数据集中的存在情况。作者研究了包括 Alpaca,ShareGPT 在内的用于大模型微调的主流数据集,发现在每个数据集中平均有2% 以上的故障词元。这说明了故障词元在数据集中很普遍,而且很可能会影响到使用这些数据集进行微调的模型的效果。
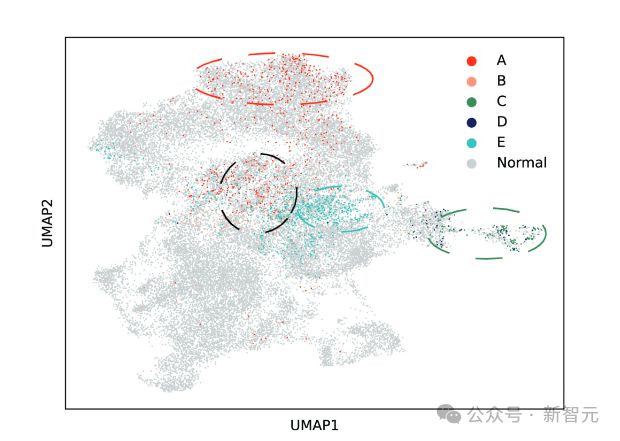
在实证研究中作者还发现,故障词元在嵌入空间中有聚集效应,这便启发作者可以通过聚类的算法来完成针对故障词元的识别工作。
作者基于上述的发现构建了 GlitchHunter,一种用于检测大模型中故障词元的自动化工具,主要依赖迭代聚类技术来识别潜在的故障词元群组,整个检测流程分为几个步骤:
- 构建词元嵌入图(TEG, Token Embedding Graph):首先,GlitchHunter 会构建一个包括所有词元及其相应的嵌入向量的词元嵌入图,来展示所有词元在嵌入空间中的位置和相互之间的关系。
- 候选聚类:接着,GlitchHunter 在词元嵌入图上寻找紧密聚集的词元,使用 Leiden 聚类算法形成潜在的故障词元群组,这些词元通常有相似的特征。
- 假设检验:在每个词元群组内,GlitchHunter 进行假设检验,通过分析群组内词元的行为和输出结果来找出群组内行为显著偏离预期规范的词元,确定哪些群组实际上包含故障词元。
- 更新与迭代:选定包含故障词元的群组后,这些词元会被整合到一个更新的词元嵌入图中。随后,GlitchHunter 会继续进行聚类和检测,直到词元嵌入图不再经历任何更新,即没有新的故障词元被发现。
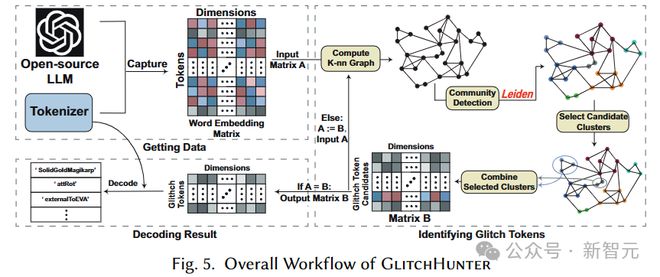
通过这种方法,GlitchHunter 能够有效地在大数据集中快速定位并处理故障词元,减少错误输出,提高语言模型的整体质量和可靠性。
为了验证 GlitchHunter 的效果,本文采用了几项关键指标来比较 GlitchHunter 与几种基线方法的性能,包括随机抽样、基于规则的随机抽样和K-means 聚类。评估结果显示,GlitchHunter 在各个测试模型中普遍表现出色。
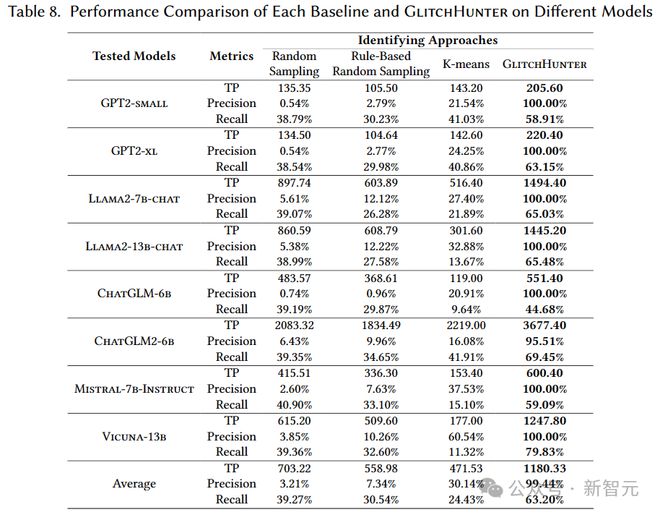
首先,GlitchHunter 的真阳性率(True Positive Rate)显著高于其他方法,这表明它在实际检测到故障词元的准确性方面表现优异。同时,其精确度(Precision)达到接近或等于 100%,远高于其他比较方法,这反映了其在识别故障词元时的高精确性。
在召回率(Recall)方面,GlitchHunter 同样展现了较高的性能,有效地识别了大部分存在的故障词元,确保了较少的遗漏。
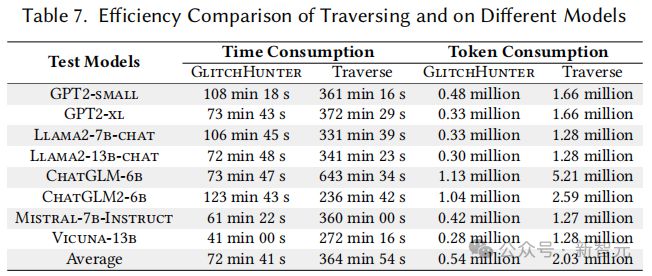
此外,GlitchHunter 相较于完整遍历词元表的方法,显著减少了所需的时间和处理的词元数量,展示了其在达到高性能的同时保持了较低的资源开销。这些评估结果充分验证了 GlitchHunter 在实际应用中提高 LLM 输出质量和可靠性的潜力,证明了其作为故障词元检测工具的有效性和实用性。
未来工作
在这个工作中,作者完成了对故障词元的系统性探究,但是对于故障词元出现的原因以及如何进行修复并未进行过多的探讨,而这也是进行故障词元研究的终极目标:解决掉所有这样的故障词元,完善大语言模型对于每一个词元的理解。
参考资料:






