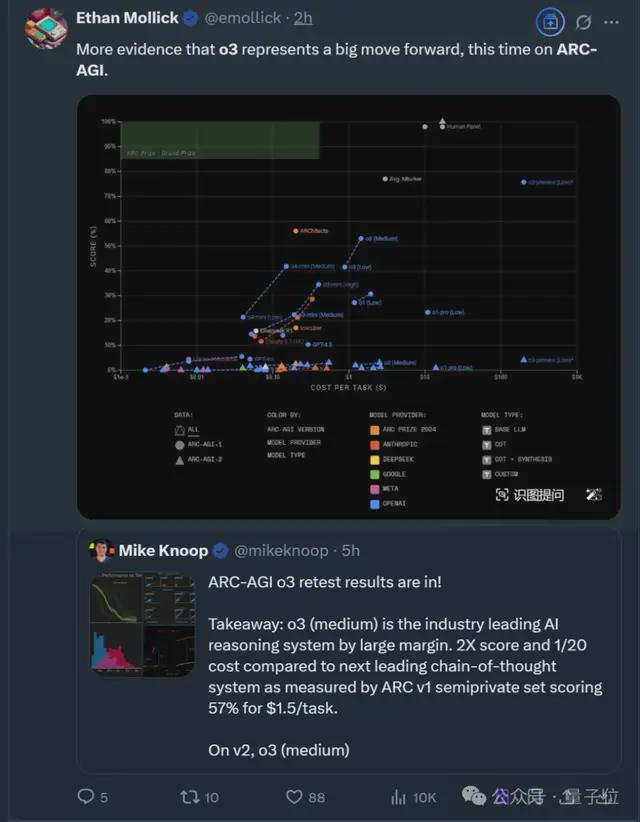
得分比第二名翻倍,成本却仅为1/20?!
o3 中杯在超难推理任务 ARC-AGI 上的新成绩,属实又给众人带来了亿点点震撼。
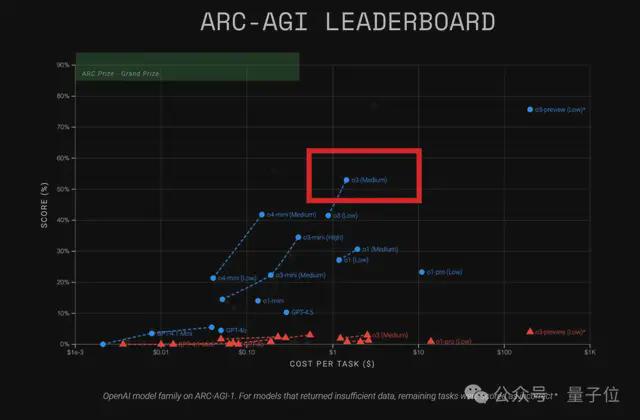
根据 ARC Prize 官方介绍,本轮测试得出的关键结论如下:
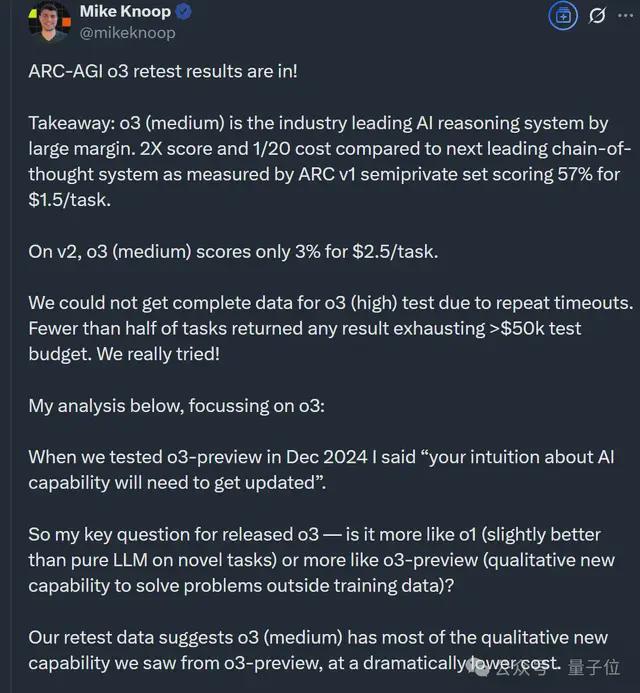
- o3 (Medium) 在 ARC-AGI-1 上得分为57%,成本为1. 5 美元/任务,优于目前所有已知 COT 推理模型;
- o4-mini(Medium)在 ARC-AGI-1 上得分为42%,成本为0. 23 美元/任务,准确率不足但成本优势明显;
- 在难度升级的 ARC-AGI-2 上,两种型号模型的准确率均未超过3%

按照最新 ARC 测试,中杯 o3 堪称目前 OpenAI 所有模型中的“性价比之王”。
不过值得注意的是,相比 2024 年 12 月 OpenAI 在“双十二”直播活动中发布的 o3 模型,最新成绩可谓“大幅缩水”。
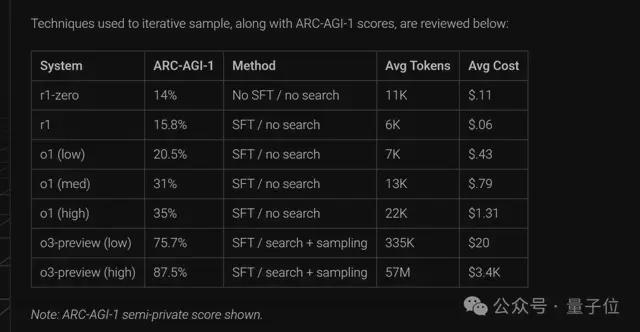
当时 o3 在低推理能力设置下(Low)得分高达 75.7%,并且让模型推理更长时间后,其得分更是首次超越人类(85%)飙升至 87.5%。
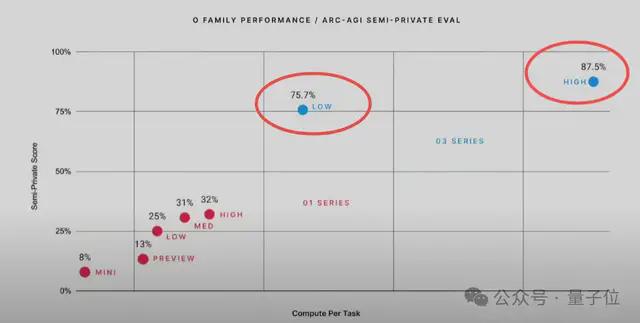
那么问题来了,为何短短几个月过去,o3 模型在 ARC 测试上的得分差异明显呢?
原来前后两个模型虽然名称一样,但实际并非相同的模型。
- OpenAI 当下最新的 o3,已针对聊天和产品应用进行了微调。
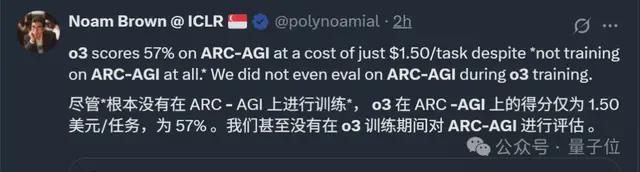
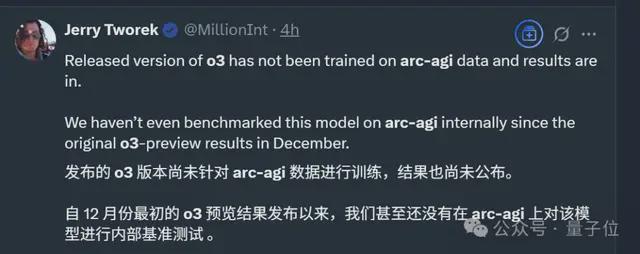
甚至,OpenAI 研究员们也强调,最新发布的 o3 并未专门针对 ARC-AGI 测试进行训练。
也就是说,中杯 o3 第一次挑战 ARC 难题就取得了好成绩。
宾大沃顿商学院教授 Ethan Mollick 更是直言:
- 现在有更多的证据表明, o3 代表着一次重大进步。
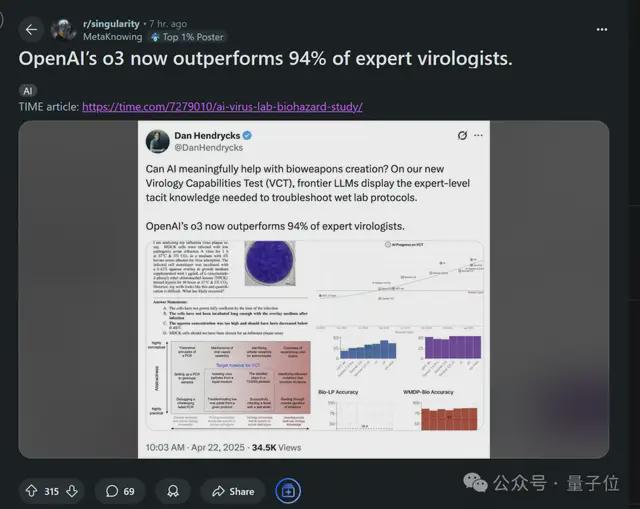
与此同时,时代杂志发表的一篇独家文章表示,o3 优于 94% 的专业病毒学家。其在这一专业领域的准确率达到了 43.8%,相比之下博士级人类专家的准确率仅为 22.1%。
中杯 o3 ARC-AGI 测试成绩出炉
ARC-AGI 是一项旨在评判大模型的“智力”,或者说“AGI 能力”的基准测试。
里面包含了一系列拼图问题,要求 AI 从不同颜色的方块中识别出视觉模式,并生成正确的 “答案” 网格。这些问题主要是为了迫使 AI 适应未曾见过的新问题。
正如开头所言,在 ARC-AGI-1 中,o3 模型曾以 75.7% 的得分“称王称霸”。而在看到这一成绩后,ARC 官方感受到了进一步更新的紧迫性。
于是在 2024 年 3 月,他们上新了ARC-AGI-2 版本,核心目标是测试模型能否高效地获取超出其训练数据的新技能。
具体而言,在 ARC-AGI-1 基础之上,官方引入了更多符号解释、多组合规则以及需要更深层次抽象的任务,难度再次大升级。
正是基于以上两个测试基准,在 OpenAI 最新上线了 o3 和 o4-mini 之后,ARC 又重新进行了测试。
除了中杯 o3 取得的好成绩,更多测试结果如下:
首先是 o3 (high),ARC 官方自称耗费超过 5 万美元,最终仍未获得 o3 (high)的完整测试结论。
理由是,在高推理能力设置下,模型在大多数情况下均无法响应或超时,最后只有不到一半的任务返回了结果。
不过参与审查的 Mike Knoop 表示,建议默认使用 o3 (high)设置,除非遇到超时才切换到 Medium 选项。
同时他认为,虽然中杯 o3 的准确率远低于 o3-preview(去年 12 月的版本),但毫无疑问 o3 整体在准确率和成本优化方面做得非常出色。
- 如今,你在其他任何地方都买不到 o3 级别的 AI 推理能力。
一言以蔽之,本轮测试结果表明,中杯 o3 在继承 o3-preview 大部分新功能的前提下,成本有了大幅下降。
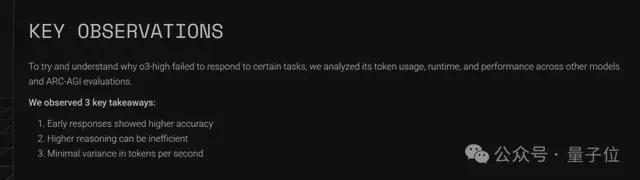
除此之外,ARC 官方还得出了三个关键发现:
1、早期响应准确率更高:模型越早返回的任务,准确率越高。而那些耗时更长(无论是运行时间还是 token 使用量)的任务,失败的可能性更大。
2、高级推理可能效率低下:在相同任务上比较中杯 o3 和 o3 (high)时,发现后者始终使用更多 token 来得出相同的答案。
3、每秒 token 数的最小变化:在o系列模型中,不同任务的每秒 token 数差异较小。特别是 o3-mini-low 和 o4-mini-low 的吞吐量(tok/s)高于中高版本。
One More Thing
顺带一提,ARC 官方早前还测试过 DeepSeek-R1。
最终结果是,在 ARC-AGI-1 基准上,DeepSeek-R1 得分为 15.8%,远低于 o3 模型。
你怎么看 o3 的新测试?






