
在这项工作中,清华大学教授、上海 AI Lab 实验室主任兼首席科学家周伯文团队,针对大语言模型(LLM)中的推理任务,研究了无明确标签的强化学习(RL)。该问题的核心挑战是在推理过程中,在无法获得 ground-truth 信息的情况下进行奖励估算。虽然这种设置似乎难以实现,但我们发现,测试时扩展(TTS)中的常见做法(如多数投票)能够产生适合用于推动 RL 训练的有效奖励。
为此,他们提出了一种在无 token 数据上使用 RL 训练 LLM 的新方法——测试时强化学习(TTRL),其利用预训练模型中的先验,实现了 LLM 的自我进化。
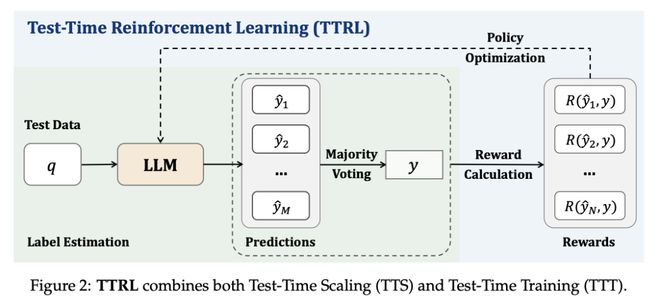
实验证明,TTRL 可以持续提高各种任务和模型的性能。值得注意的是,TTRL 将 Qwen-2.5-Math-7B 在 AIME 2024(仅使用未标记测试数据)上的 pass@1 性能提高了约 159%。此外,尽管 TTRL 只受 Maj@N 指标的监督,但表现出的性能一直超过初始模型的上限,并接近直接在带有 ground-truth 标签的测试数据上训练的模型的性能。实验结果验证了 TTRL 在各种任务中的普遍有效性,并凸显了 TTRL 在更广泛的任务和领域中的潜力。






