
大语言模型(LLM)的近期进展证明了(输入序列)长度 scaling 在后训练中的有效性,但其在预训练中的潜力仍未得到充分挖掘。
在这项工作中,字节跳动团队提出了并行隐藏解码 Transformer(PHD-Transformer)框架,其可以在保持推理效率的同时,在预训练期间实现高效的长度 scaling。PHD-Transformer 通过 KV 缓存管理策略实现了这一目标,该策略可以区分原始 token 和隐藏解码 token。这一方法只保留原始 token 的 KV 缓存,用于长程依赖关系,同时在使用后立即丢弃隐藏的解码 token,从而保持了与 vanilla Transformer 相同的 KV 缓存大小,同时实现了有效的长度 scaling。
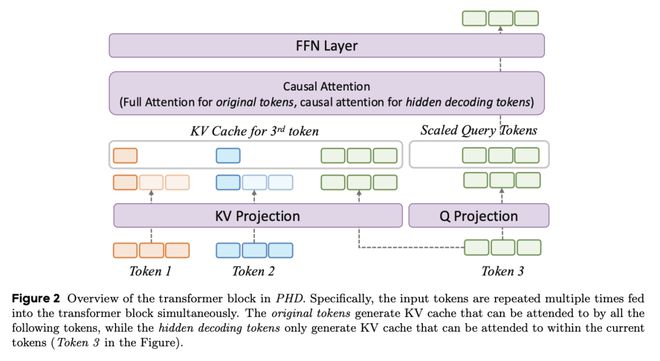
为了进一步提高性能,他们提出了两个优化变体:PHD-SWA 采用滑动窗口注意力来保留局部依赖性,而 PHD-CSWA 则采用分块滑动窗口注意力来消除预填充时间的线性增长。实验证明,在多个基准测试中,PHD-Transformer 都取得了一致的改进。






