
DP-Recon 团队投稿量子位 | 公众号 QbitAI
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的 3D 场景?
在传统方法中,这几乎是不可能完成的任务,稀少的拍摄视角往往导致模型无法还原被遮挡的区域,生成的场景要么残缺不全,要么细节模糊。更令人困扰的是,传统的重建算法无法解耦场景中的独立物体,重建结果无法交互,严重限制了在具身智能、元宇宙和影视游戏等领域的应用前景。
近期,北京通用人工智能研究院联合清华大学、北京大学的研究团队提出了名为 DP-Recon 的创新方法。该方法通过在组合式 3D 场景重建中,引入生成式扩散模型作为先验,即便只有寥寥数张图像输入,也能智能“脑补”出隐藏在视野之外的场景细节,分别重建出场景中的每个物体和背景。
值得一提的是,该方法还创新性地提出了一套可见性建模技术,通过动态调节扩散先验和输入图片约束的损失权重,巧妙地解决了生成内容与真实场景不一致的难题。在应用层面,DP-Recon 不仅支持从稀疏图像中恢复场景,还能实现基于文本的场景编辑,并导出带纹理的高质量模型,为具身智能、影视游戏制作、AR/VR 内容创作等领域,带来了全新的可能性。

研究概述

图 1. 重建结果、基于文本编辑和影视特效展示
3D 场景重建一直是计算机视觉和图形学领域的核心挑战,其目标是从多视角图像中恢复场景的完整几何和逼真纹理。近年来,NeRF 和 3DGS 等神经隐式表示方法在多视角充足时表现出色,但在稀疏视角下却捉襟见肘。更重要的是,这些方法将整个场景作为一个整体重建,无法解耦独立物体,这严重制约了下游应用的发展。
现有的组合式场景重建方法同样面临稀疏视角带来的的严峻挑战。视角稀少会导致大面积区域缺乏观测数据,模型在这些区域容易崩塌;同时,物体间的相互遮挡使得某些部分在所有输入图像中都不可见,最终导致重建结果出现畸形或遗漏。
那么,如何为这些“看不见”的区域补充合理信息,让重建模型既忠实于输入图像,又能在空白处有所依据?DP-Recon 给出了令人振奋的解决方案,该方法巧妙地将生成式扩散模型作为先验引入组合式场景重建,通过 Score Distillation Sampling(SDS)技术,将扩散模型对物体概念的“理解”蒸馏到 3D 重建过程中。例如,当输入照片只拍到桌子的一面时,扩散模型可以基于对“桌子”这一概念的认知,智能推断出桌子背面的可能形状和纹理。这种方式为重建提供了宝贵的信息补充,极大提升了在稀疏视角和遮挡场景下的重建效果。
需要注意的是,直接将扩散先验硬套用到重建上并非易事。如果处理不当,生成模型可能会“过度想象”,产生与输入图像矛盾的内容,反而干扰基于真实照片的重建过程。为此,DP-Recon 精心设计了一套基于可见性的平衡机制,巧妙协调重建信号(来自输入图像的监督)和生成引导(来自扩散模型的先验),通过动态调整扩散先验的作用范围,确保模型在已有照片信息处保持忠实,在空白区域合理发挥想象力。
下面将深入解析 DP-Recon 的核心技术细节。
关键技术
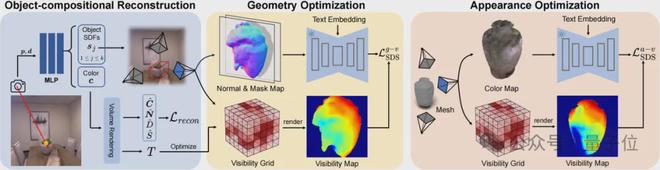
图 2. DP-Recon 的算法框架
DP-Recon 的技术创新主要体现在以下三个关键方面:
1. 组合式场景重建:
与传统整体式重建不同,DP-Recon 采用组合式重建策略。具体来说,模型会利用多种模态的重建损失(包括:RGB 图像、深度图、法向量图和实例分割图),为每个对象分别建立隐式场(SDF),初步构建几何轮廓和外观表征,便于后续对每个物体加入基于文本的先验信息。
2. 几何和外观的分阶段优化:
DP-Recon 将重建过程分为了几何和外观两个阶段,分别针对物体的形状和纹理进行优化。
在几何优化阶段,基于初步重建的基础,通过对法向量图引入 Stable Diffusion 的 SDS 损失,进一步优化物体在欠缺观察区域的细节,显著提升几何完整度。此阶段结束后,将输出每个物体和背景的 Mesh 结构。
在外观优化阶段,使用 Nvdiffrast 渲染生成的 Mesh,巧妙融合输入图像的颜色信息和扩散先验,对物体表面纹理进行优化。为便于后续渲染和编辑,DP-Recon 在此阶段还会为每个对象生成精细的 UV 贴图。
经过以上两个阶段的处理,最终,场景中每个对象的高质量网格模型及其纹理贴图,均具有精准几何和逼真外观。
3. 可见性引导的 SDS 权重机制:
针对扩散先验可能带来的不一致问题,DP-Recon 提出了创新的可见性引导解决方案。该方法在计算 SDS 损失时引入可见性权重,根据每个像素在输入视角中的可见程度,动态调节扩散模型的引导强度。
具体而言,DP-Recon 在重建过程中构建了一个可见性网格,通过输入视角体渲染过程中积累的透射率,来优化这个网格。当需要计算参与 SDS 视角的可见性图时,直接查询该网格即可。对于输入照片中高度可见的区域,系统会自动降低 SDS 损失权重,避免扩散模型“喧宾夺主”;而对于未被拍摄到或被遮挡的区域,则赋予更高的 SDS 权重,鼓励网络借助扩散先验补全细节。这种精细的可见性引导机制,完美平衡了重建的真实性与完整性。
实验结果
在 Replica 和 ScanNet++ 等权威数据集上的系统性评估表明,DP-Recon 在稀疏视角下的整体场景重建和分解式物体重建两方面都实现了显著突破。
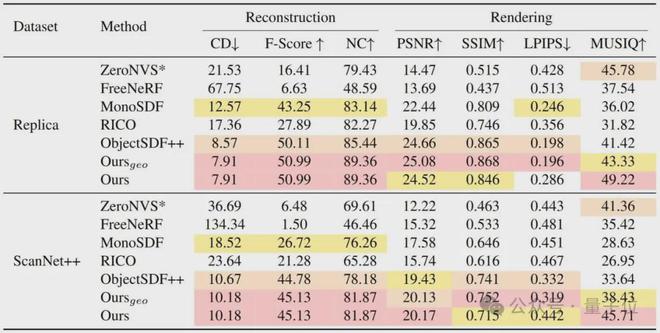
表 1. 整场景重建定量结果对比
1. 整体场景重建:
量化结果(见表1)清晰显示,DP-Recon 方法在重建指标和渲染指标上与所有基线模型相比,均展现出明显优势。

△图 3. 场景重建结果对比
如图 3 所示,通过将生成式先验融入重建流程,DP-Recon 在拍摄不足的区域,实现了更精准的几何重建和颜色还原,以及更平滑的背景重建和更少的伪影漂浮物。如图 4 所示,在相同条件下,DP-Recon 的渲染结果质量明显更高,而基线方法则出现明显伪影。

图 4. 新视角合成结果对比
2. 分解式物体重建:
如表 2 和图 3 所示,生成式先验的引入极大改善了遮挡区域的重建效果,被遮挡物体的结构和背景都能更加精确地还原,DP-Recon 显著减少遮挡区域的伪影漂浮物。在遮挡严重的复杂大场景测试中(见图1),DP-Recon 仅用 10 个视角就超越了基线方法使用 100 个视角的重建效果,这一突破性成果充分证明了该方法在真实场景中的实用价值。
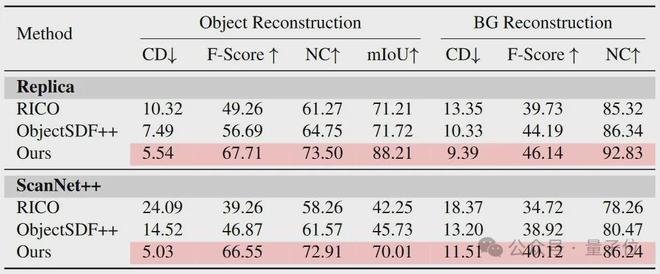
表 2. 物体和背景重建结果对比
应用价值
1. 智能家居重建:
DP-Recon 对室内场景展现出了卓越的鲁棒性。实验表明,仅需从 YouTube 看房视频中提取 15 张图像,配合 Colmap 标注相机位姿和 SAM2 物体分割,就能重建出高质量的带纹理场景模型,如图 5 所示。

△图 5. YouTube 看房视频重建结果
2. 赋能 3D AIGC:
借助 DP-Recon 的生成式先验,用户可以轻松实现基于文本的场景编辑,如图 6 所示。就像为 3D 世界接入了 AI 想象力,用一句“将花瓶变成泰迪熊”或是“换成太空风格”,就能实现传统方法需要数日才能完成的修改。这种无缝融合重建与创作的能力,将大幅提升 AIGC 生产效率。

图 6. 基于文本的场景几何和外观编辑
3. 影视游戏工业化:
DP-Recon 输出的每个对象都是带有精细 UV 贴图的独立网格模型,如图 7 所示,这为影视特效(VFX)和游戏开发带来了极大便利。创作者可以轻松将模型导入 Blender 等 3D 软件,进行光照、动画和特效制作,或将场景直接接入游戏引擎开发交互内容。

图 7. 影视特效展示
团队介绍
研究团队由来自北京通用人工智能研究院(BIGAI)、清华大学和北京大学的跨学科研究者组成,致力于通用人工智能领域的前沿研究。团队成员在三维场景理解、重建和生成等方面,拥有丰富的研究经验。一作为清华大学博士生倪俊锋,其它作者为清华大学博士生刘宇、北京大学博士生陆睿杰、清华大学本科生周子睿;通讯作者为北京通用人工智能研究院研究员陈以新、北京通用人工智能研究院研究员黄思远。
论文链接: https://arxiv.org/abs/2503.14830






