
梦晨西风发自凹非寺
量子位 | 公众号 QbitAI
新国产 AI 视频生成模型横空出世,一夜间全网刷屏。
- Magi-1,首个实现顶级画质输出的自回归视频生成模型模型权重、代码 100% 开源
整整 61 页的技术报告中还详细介绍了创新的注意力改进和推理基础设施设计,给人一种视频版 DeepSeek 的感觉。
Magi-1 将视频生成卷到了新高度,大片级品质直接锁住大家的眼球。
其主打能力,一是无限长度扩展,实现跨时间的无缝连贯叙事:

二是能将生成时长控制精确到每一“秒”:

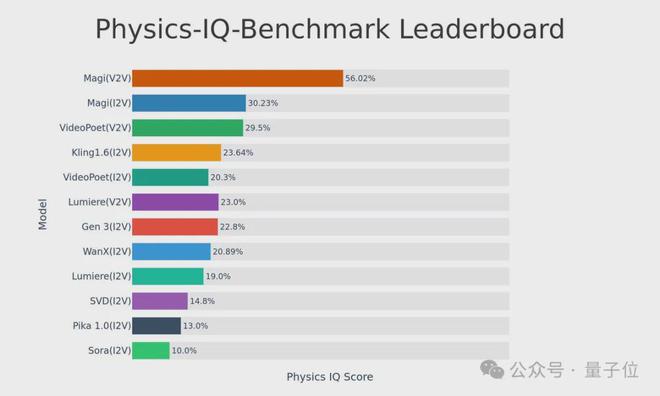
另外,Magi-1 对物理规律也有更深度的理解,Physics-IQ 基准测试 56.02%,大幅领先一众顶流。
现在看这张图,Sora 的时代是真的过去了。
这匹“黑马”来自中国团队Sand.ai,中文名听着有点萌叫三呆科技,实力却不容小觑。
创始人曹越,清华特奖得主、光年之外联合创始人。

目前大伙儿可在官网免费试玩 Magi-1。GitHub 更是一晚过后狂揽 500+Star。
此次开源了从 24B 到 4.5B 参数的一系列模型,最低配置一块 4090 就能跑。

网友们激动转发测试,评价也是相当高,看一下这个 feel:

- 这绝对是令人惊叹的工作。将自回归扩散应用于视频领域不仅是研究上的一大步,更是为现实世界的创意领域开辟了新可能。Magi-1 在生成质量和精度上树立了新标杆。
- 开源特性+令人瞩目的基准测试表现=游戏规则改变者。
无限长度扩展,控制精确到每“秒”
还有更多官方效果展示,先来欣赏一波~
比如漂在水面上的猫,水面自然晃动,波光粼粼:

抽着雪茄的海盗船长,颇有大
片的感 jio:

光影等细节满满:

网友们也都陆陆续续晒出了自己的实测效果:
- 画质超清晰,VR 头显上的细微反光以及狗的胡须和毛发细节都栩栩如生。
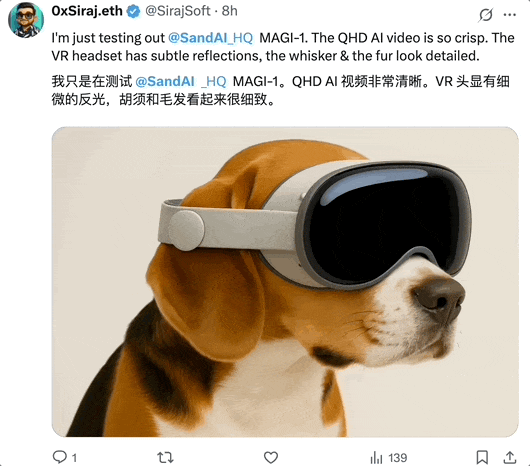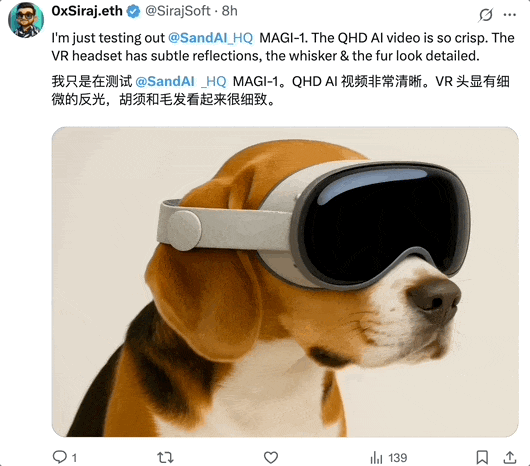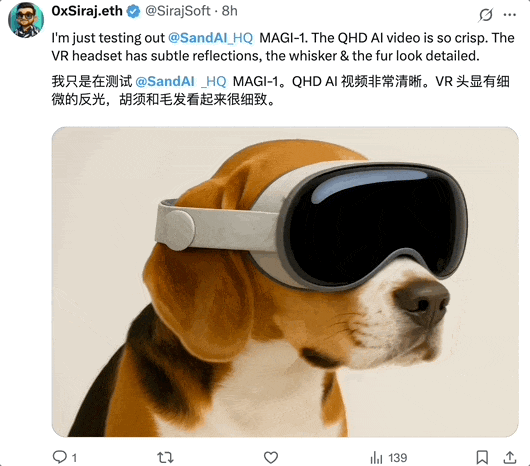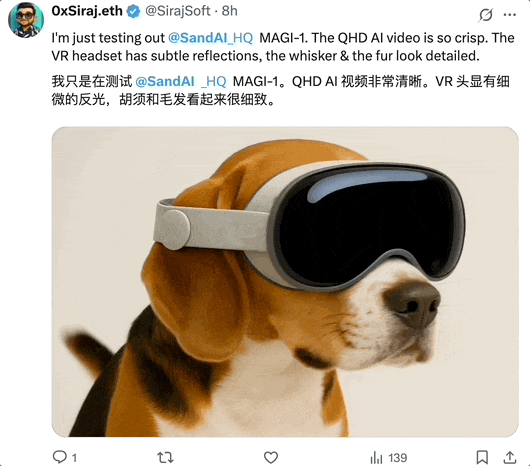
还有网友生成了正在跳舞的小动物,belike:

量子位自然不能错过,第一时间上手实测了一波。
玩法上,打开 Magi-1,主打图生成视频,且是以一个“项目”为单位:
上传好图片之后,Magi-1 像一张画布一样,呈现节点式的交互界面,点击图片侧边加号按钮就能创建一个“视频块”。
开始设置 prompt,支持精确调整时长,一次最长 10s,也可设置 Variations 一次性生成多个视频:

稍等片刻,一只活蹦乱跳的吉卜力小狗就生成好了。
我们第一次尝试就得到了下面酱婶儿的效果,小狗的动作姿态整体比较符合物理规律,没有离谱的扭曲以及突然出现的第五条腿(doge)。
视频左边还有自动改写增强后的 prompt。
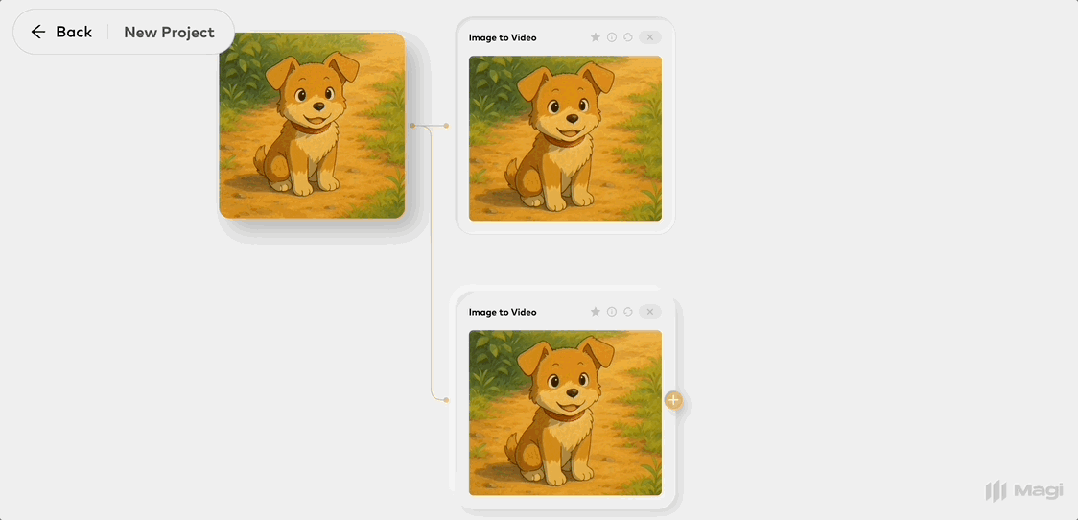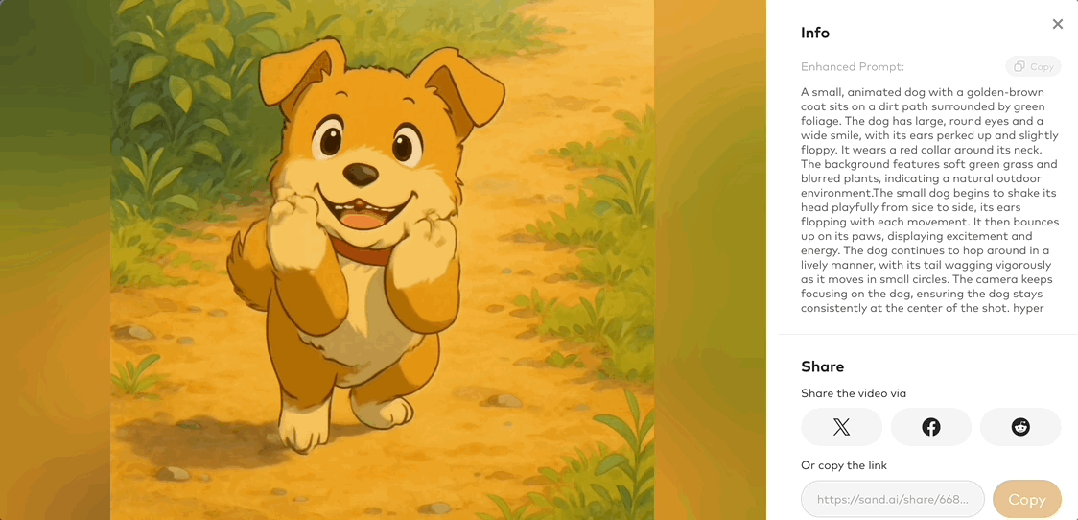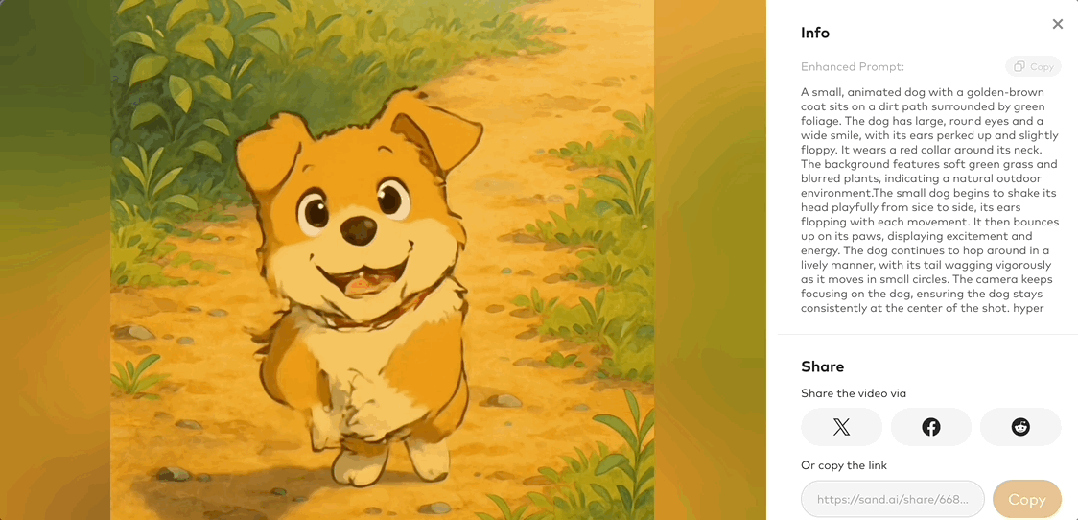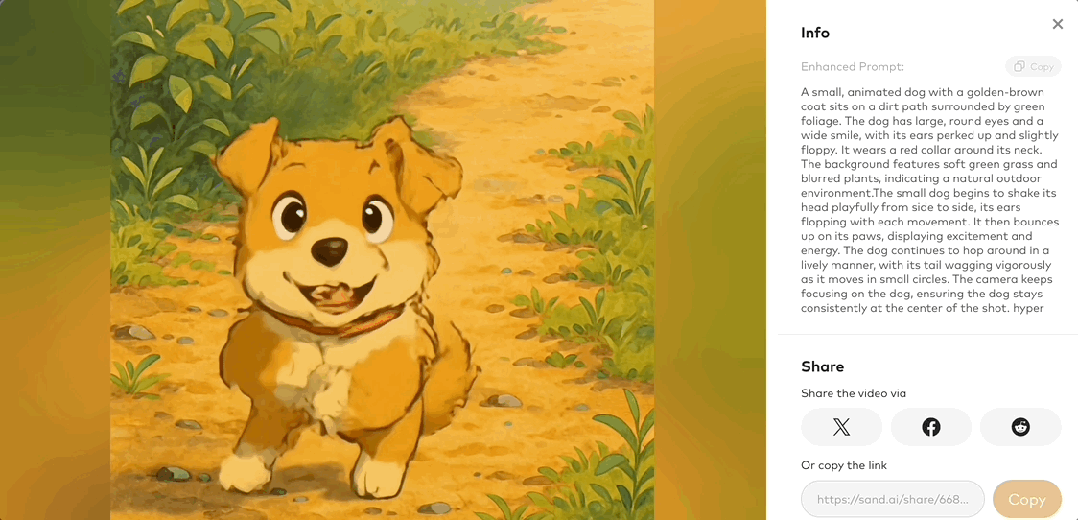
接着,对这段视频进行扩展,小狗摇头晃脑活蹦乱跳在表达什么呢?

原来是在讲述它今天在河里游泳玩耍的事情。

把这一个个镜头“组装”起来,分分钟就能打造出一部连贯的叙事短片。
另外 Magi-1 中还有“资产管理”板块,可基于生成的视频再创建一个新项目,进行二次加工创作。

完整模型架构、推理基础设施公开
Magi-1 公布的技术论文足足有 61 页之多。
Magi-1 整体架构基于 Diffusion Transformer,采用 Flow-Matching 作为训练目标。
训练分为多阶段,第一阶段固定分辨率(256×256,16 帧),第二阶段引入可变分辨率和图像-视频联合训练,并在推理时使用滑动窗口方法来支持任意分辨率。
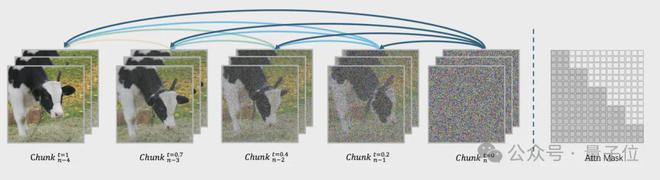
其最大的特点是不把视频当成一个整体去生成,而是通过自回归去噪方式预测固定长度的视频片段(chunk),每个片段固定为 24 帧。
当前一个片段达到一定去噪水平后,便开始生成下一个片段。这种流水线设计最多可同时处理四个片段,提高视频生成的效率。
同时,这种约束早期片段噪声水平低于后期片段的设计,确保了视频前后的因果性,避免片段的信息影响过去,导致时间一致性差(如物体突然消失或运动轨迹断裂)
配合这种分片段自回归设计,Magi-1 在 Diffusion Transformer 的基础上融入了多项改进。
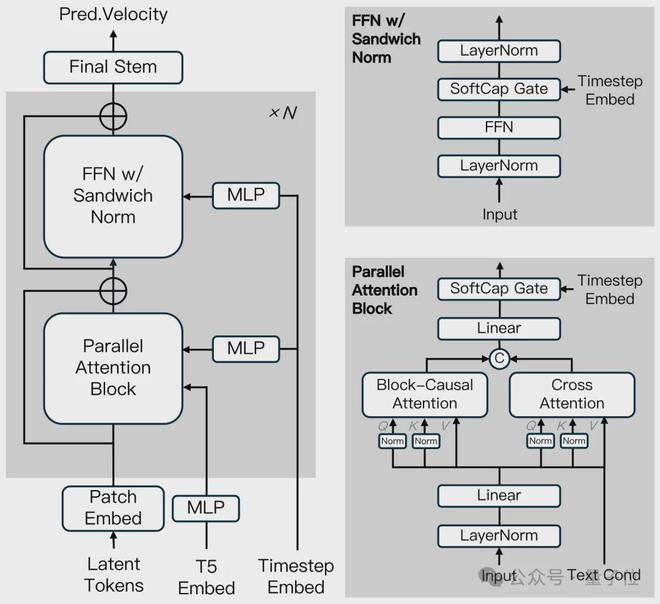
光是在注意力机制上就有多项创新。
Block-Causal Attention
- 片段内全注意力:每个视频片段内的所有帧间进行全注意力计算,捕捉片段内短时序依赖(如单片段内物体的快速运动)。
- 片段间因果注意力:仅允许当前片段关注之前已生成的片段,禁止未来片段信息反向流入,确保因果性。
- 3D RoPE 位置编码:结合空间和时间位置信息,学习可训练的基频参数,提升长时序建模能力。
Parallel Attention Block
传统 DiT 架构中自注意力(处理视觉特征)和交叉注意力(处理文本条件)串行执行,需两次 TP 通信(Tensor Parallel);并行块将两者的查询投影Q共享,仅需一次通信,减少 GPU 间同步开销
QK-NormGQA
QK-Norm 是源自视觉 Transformer 的技术,通过归一化查询(Q)和键(K)的范数,稳定注意力权重计算,避免梯度爆炸/消失。Magi-1 将其扩展到时空注意力和交叉注意力模块,提升训练稳定性,尤其在 240 亿参数规模下效果显著。
接下来的 GQA、FFN 中的三明治归一化、SwiGLU 大家就很熟悉了。
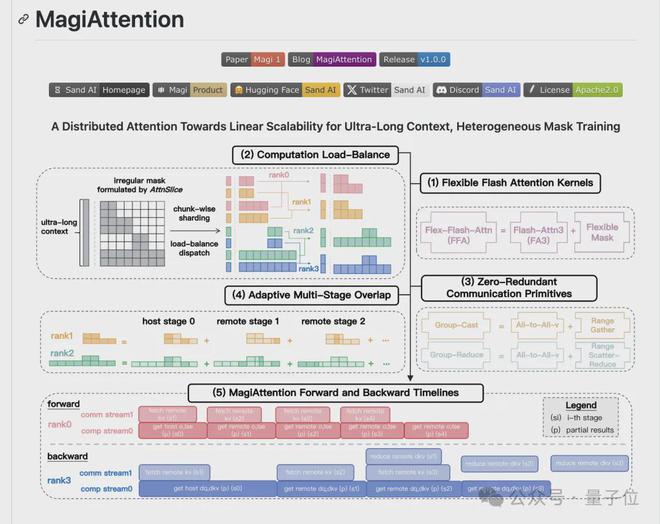
到了具体软硬协同层面,论文还提出了可扩展分布式注意力机制 MagiAttention。
Flex-Flash-Attention
基于 FlashAttention-3,将不规则注意力掩码分解为多个 AttnSlice,使各种常用注意力掩码可表示为多个 AttnSlice 的组合,从而支持灵活的注意力掩码类型。利用英伟达 Hopper 架构的 TMA 特征,引入 Slice 级并行和原子操作,在支持灵活掩码的同时,保持与 FlashAttention-3 相当的计算性能。
计算负载均衡
将整个掩码沿查询维度均匀划分为多个 dispatch chunks,并分配到不同的上下文并行(CP)对应的 bucket 中,使每个 bucket 包含相同数量的 dispatch chunks,避免因负载不均衡导致的计算资源闲置。
零冗余通信原语
针对现有环形点对点通信原语存在冗余通信的问题,引入 group-cast 和 group-reduce 原语。根据注意力掩码的需求,精准地发送和收集关键值(KV)及梯度(dKV)信息,避免不必要的通信,实现零冗余通信。通过使用 all-to-all-v 原语进行原型实现,并借助内核融合减少预处理和后处理开销。
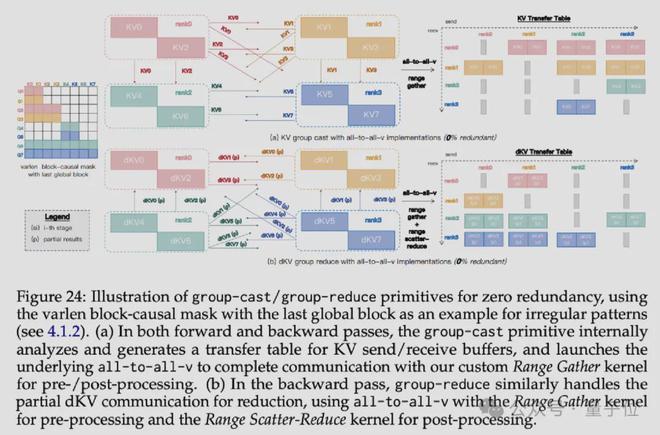
自适应多阶段重叠
为实现真正的线性扩展,引入多阶段计算-通信重叠策略,将每个 rank 的远程 KV/dKV 通信划分为多个阶段。
在正向传递中,先启动 group-cast 内核预取下一阶段的远程 KV,然后异步执行 Flex-Flash-Attention(FFA)内核进行部分注意力计算;
在反向传递中,除了预取 KV,还在启动 FFA 内核前,通过 group-reduce 内核减少上一阶段的 dKV。通过引入可调节超参数 num_stages,根据不同训练设置、微批次以及正向和反向传递的计算-通信比率,自适应地控制重叠粒度。
所有这些改动作为一个完整的 MagiAttention 项目,代码也在 GitHub 上开源。
推理基础设施方面,主要针对两种场景进行设计:实时流式视频生成和在 RTX 4090 GPU 上的经济高效部署,以满足不同应用需求。
在实时流式视频生成上采用异构服务架构,将 T5(提取文本 Embedding,为视频生成提供语义信息)和 Magi-1 部署在高性能 GPU 上,VAE 部分部署在经济高效的硬件上,实现 Magi-1 推理和 VAE 解码并发执行,并通过分析性能数据来分配资源,提升整体吞吐量。
针对 RTX4090 部署场景,借鉴语言模型将 KV 缓存存储在 CPU 内存中,根据需要动态加载回 GPU。针对 RTX4090 的 PCIe 总线带宽限制,提出 Context Shuffle Overlap(CSO)技术,优化通信与计算的重叠,提升计算资源利用率,使 4.5B 参数模型在单块 RTX 4090 GPU 上部署时,峰值内存占用控制在 21.94GB;24B 模型在 8 块 RTX4090 GPU 上部署时,峰值内存占用控制在 19.29GB,且最大 MFU(浮点运算数利用率)达到 58% 。
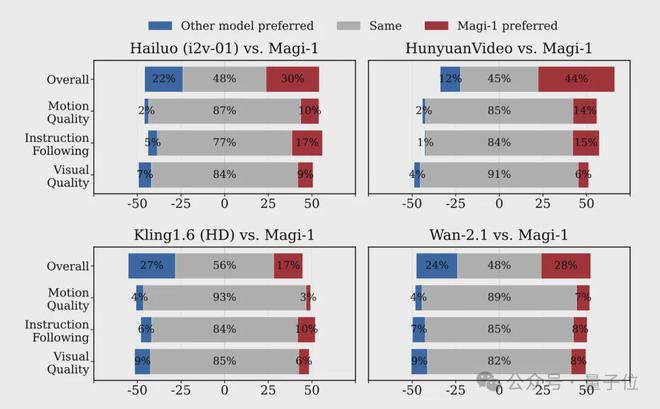
最后,评估结果分为内部人工评估、自动评估(VBench-I2V 基准)、物理理解能力评估三部分。
人类评估中 Magi-1 与海螺、腾讯混元、通义万相 Wan2.1 相比,尤其是在指令跟随和运动质量方面有优势,与闭源模型可灵 1.6 在视觉质量上还有一些差距。
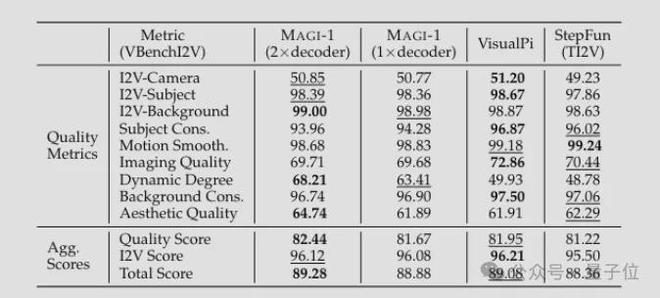
在 VBench-I2V 基准上:MAGI-1(2×解码器)以总分 89.28 排名第一,尤其在动态程度(Dynamic Degree)上有优势,平衡运动幅度与图像质量。
曹越执掌的团队,已完成三轮融资
Sand.AI 创始人曹越,博士毕业于清华大学软件学院,2018 年获清华大学特等奖学金。

读博期间在微软 MSRA 实习,2021 年以 Swin Transformer 共同一作身份获 ICCV 最佳论文“马尔奖”。
2022 年,曹越与王慧文等共同创办光年之外,后加入智源研究院领导多模态与视觉研究中心。
2023 年曹越创办 Sand.ai,在很长一段时间保持隐身模式。
2024 年 7 月,其投资方今日资本“风投女王”徐新的一条传闻把 Sand.ai 炸出水面。
当时有人发帖称“今日资本撤离一级市场”,徐新发朋友圈辟谣时透露,2024 年 5 月今日资本领投了 Sand.AI 的早期融资。
到现在据了解,Sand.AI 已完成三轮融资,主要参与方包括今日资本、经纬创投等。
创新工场创始人李开复刚刚也发帖推荐了 Sand.AI 与 Magi-1,称“很高兴看到继 DeepSeek 之后,又有一家 AI 公司开发出世界一流的开源模型”。

目前 Sand.ai 具体融资金额,团队规模等尚未可知,不过从 MAGI-1 论文附带的贡献者名单看,核心技术团队至少有 36 人。

其中很多成员与曹越在工作经历上有交集。
如创始成员方羽新,有微软 MSRA、智源研究院实习经历,也是光年之外创始成员之一。

两人在智源研究院期间在大规模视觉表征预训练模型 EVA 系列上多次合作。

核心贡献者李凌志,也有 MSRA 实习经历,曾担任小红书算法主管和阿里巴巴集团达摩院算法专家。

多位团队成员在个人主页等处介绍自己现在为一家隐形初创公司工作。
现在答案已经明了,他们在 Sand AI,做 AI 视频生成界的 DeepSeek。
在线试玩:
[1] https://github.com/SandAI-org/MAGI-1






