
新智元报道
编辑:编辑部 XJZ
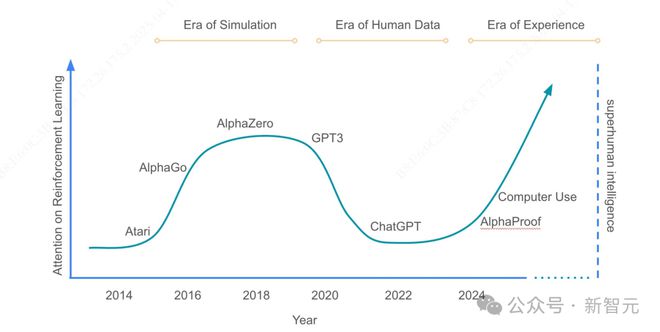
强化学习之父 Richard Sutton 和 DeepMind 强化学习副总裁 David Silver 对我们发出了当头棒喝:如今,人类已经由数据时代踏入经验时代。通往 ASI 之路要靠 RL,而非人类数据!
最近,图灵奖获得者、强化学习之父 Richard Sutton,联同 DeepMind 强化学习副总裁 David Silver 共同发布了一篇文章。

有人称,这篇文章就犹如《The Bitter Lesson》的续章,给了我们当头一棒——AI 范式,正在经历大转折!
文中表示,我们经历过模拟时代,享受过人类数据时代,如今正踏入经验时代。
以后想要再发展 AI,不靠模仿,不靠学习,而是靠「活过」!
太长不看版
一位中国网友的总结,得到了 RL 之父本人的转发和赞许。
以下是就是这位网友「xingxb」的总结。
我们正从「人类数据时代」跨入「经验时代」。这不是模型升级,不是 RL 算法迭代,而是一种更根本的范式转折:
· 从模仿人类到超越人类
· 从静态数据到动态经验
· 从监督学习到主动试错
他们喊话整个 AI 界:经验,才是通往真正智能的钥匙!
人类数据,正在见顶。今天的 AI(如 LLMs)依赖海量人类数据训练。它能写诗、做题、诊断,几乎无所不能。然而我们必须注意的是:
· 高质量数据正在枯竭
· AI 的模仿能力已经逼近人类上限
· 数学、编程、科研等领域再难靠「喂数据」进步
因此,模仿能让 AI 胜任,但不能让 AI 突破。
而经验,就是下一个超级数据源。真正能推动 AI 跃升的数据,必须随模型变强而自动增长。唯一的解法,就是经验本身。
· 经验是无限的
· 经验能突破人类知识边界
· 经验流才是智能体的本地语言
因此,RL 之父的主张就是:未来 AI 不是「提示词+知识库」,而是「行动+反馈」的循环体。
它们有几个关键特征。
· 它们生活在持续经验流中(非任务片段)
· 它们的行为扎根真实环境,不靠聊天框
· 奖励来自环境,而非人类打分
· 推理依赖行动轨迹,而非仅模仿文本逻辑
这些,都是对 LLM 范式的一次根本性挑战。
强化学习并不能解决所有事,如今,我们的经验智能还在早期,但技术条件和算力已经具备。AI 社区是否准备好,拥抱主动智能范式?
这,将是一次思想上、技术上和伦理上的深刻转折。
通往 ASI:经验时代新阶段
最近,DeepMind 强化学习副总裁 David Silver,掀起桌子,大声宣言——
大语言模型(LLM)并非 AI 的全部!
人类需要的是能自主推理、发现未知事物的 AI。
那么,如果剥离人类反馈的要素,最终得到的模型还能保持现实根基吗?
David Silver 提出了与主流相反的观点。

在近期博客中,他探讨了「经验时代」与当前「人类数据时代」的概念。
以 AlphaGo 和 AlphaZero 为例,他强调了强化学习可以超越人类能力,而不需要先前的知识。
这种做法与依赖人类数据和反馈的大语言模型形成鲜明对比。

Silver 强调探索强化学习对于推动 AI 进步和实现 ASI 的必要性。
在当前多模态模型的热议、兴奋和成就之后,David 有一个通往 ASI 的计划,他称之为「经验时代」的新阶段。
「经验时代」将与过去几年,完全不同。
过去,一直处于「人类数据时代」的阶段,也就是说,所有 AI 方法都有一个共同的想法:
提取人类拥有的所有条知识,然后输入到机器中。
这固然非常强大。
但还有另一种方法,它将引领人类进入「经验时代」,即机器与实际世界本身互动,并产生自己的经验。
如果将交互数据视为驱动机器的燃料,那么这将引领下一代 AI 的进入「经验时代」。
在某种程度上,David 是拍案而起,大声疾呼:「大语言模型并非唯一的AI。」
也就是说,AI 还有其他的选择,可以用不同的方式来实现 AGI。
构建大语言模型,AI 的确获益良多——
通过利用海量的人类自然语言数据,将所有人类书写过的知识都整合进机器之中。
但某种程度上,人类必须跨越这个阶段:突破认知的边界。
要实现这一点,就必须采用全新的方法——
这种方法要求 AI 能够自主推理,发现人类未知的领域。
这将开启一个全新的 AI 时代,它必将为社会带来前所未有的深刻变革与无限可能。
AlphaGo:与 LLM 完全不同
和 LLM 不同,其他的一些著名的 AI 采用了不同的方法,最值得一提的是 AlphaGo 和 AlphaZero。
大约十年前,它们击败了世界上最顶尖的围棋选手。

AlphaGo 击败当时围棋国际排名第一的柯洁
如何从头开始学习围棋?
特别是 AlphaZero,与最近的基于人类数据的方法非常不同,因为它完全不使用人类数据。

「Zero」(零)这个词就代表了这一点。所以,系统中预先编程的是字面意义上的零人类知识。
那么,LLM 的替代方案是什么呢?如果不复制人类,并且事先并不知道正确的下棋方式,如何学习围棋知识呢?
可以采用的方法是一种试错学习的形式。
AlphaZero 自我对弈了数百万盘围棋、国际象棋或者它想玩的其他棋类游戏。
一点一点地,它发现:「哦,如果在这种情况下下这种棋,那么我最终会赢得更多的比赛。」
然后,这成为它用来变得更强大的经验。
然后它会稍微多下一些类似的棋,下一次它会发现一些新的东西,它会说:「哦,当使用这种特定的模式时,我最终会赢得更多的比赛或者输掉更多的比赛。」
这会反过来促进下一代的学习,以此类推。
而这种从经验中学习,从智能体自身产生的经验中学习,就足够了。
虽然最初版本的 AlphaGo,确实使用了一些人类数据作为起点。
给它输入了一个人类职业棋手的棋谱数据库,它学习并吸收了这些人类的招法,这为它提供了一个起点。
然后,从那时起,它通过自己的经验进行学习。
然而,一年后发现,人类数据并不是必需的,可以完全抛弃人类的招法。
这证明了:程序不仅能够恢复到之前的性能水平,而且实际上表现得更好,并且能够比最初的 AlphaGo 更快地学习,从而达到更高的性能水平。
苦涩的教训:人类数据可有可无
AlphaZero 非常奇怪:抛弃了人类数据,结果发现人类数据不仅没什么用,而且在某种程度上还限制了性能。
这涉及到 AI 领域深刻的「苦涩的教训」。
大家都认为:人类积累的知识非常重要。
这导致设计的 AI 算法可能更适合人类数据,而不太擅长自主学习。
而结果是,如果抛弃了人类数据,实际上会花费更多的精力让系统自主学习。
而正是自主学习才能不断地学习和学习,永无止境。
这几乎就是承认 AI 可能比人类更擅长下围棋,而且在某种程度上突破了人类的上限。
人类数据对于 AI 起步非常有用,但人类所做的一切都有一个上限。
在 AlphaZero 中,AI 通过自我对弈进行学习,并且变得越来越好,最终突破了人类上限,并远远超越。
在「经验时代」,人类能找到足以在所有领域都突破上限的方法。
AI 神来之笔:第 37 手
AlphaGo 对阵李世石的第二盘棋中的第 37 手棋,出乎所有人的意料。
AlphaGo 下在了第五线上,以某种方式下出了这步棋,让棋盘上的一切都变得合理起来。
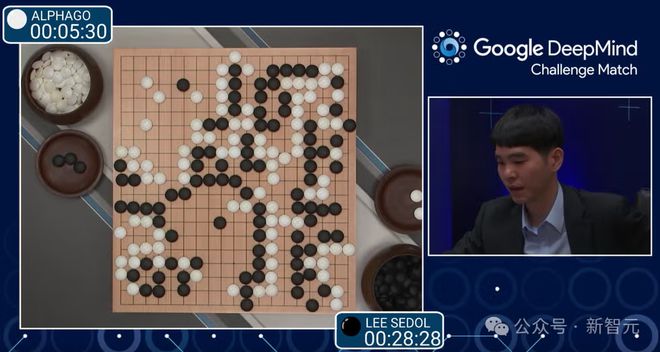
这对于人类来说是如此的陌生,人类想到下这步棋的概率估计只有万分之一。
人类对这步棋感到震惊,然而它却帮助 AlphaGo 赢了那盘棋。
在那一刻,人类意识到「看,这里发生了一些开天辟地的事,机器想出了一些与人类传统思维方式不同的下棋方式」。
这是历史性巨大的进步,远在人类知识的界限之外。
因为一直处于人类数据时代,投入了大量的精力来复制人类能力,而很少关注超越人类能力。
除非真正强调系统自主学习,超越人类数据,否则不会在现实世界中看到像第 37 手棋那样的巨大突破。
第 37 手棋不仅仅是一个单一的发现,还证明了从经验中不断地学习,涌现出无穷的发现。
刚刚完成国际象棋上的 AlphaZero,直接将它应用到将棋(日本象棋)的游戏,结果连世界冠军都认为远超人类的上限。
实际上,这是第一次在将棋上运行 AlphaZero。
开发者只是按下了「开始」键,一个超人的将棋选手就诞生了。
就像魔术一样。
强化学习和人类反馈
甚至机器可以自己设计强化学习算法,DeepMind 已研究多年。
他们构建了一个系统,通过试错,通过它自身的强化学习,找出哪种算法最适合强化学习。
它学会了如何构建自己的强化学习系统。

令人难以置信的是,它实际上超越了人类提出的强化学习算法。

论文链接:https://arxiv.org/abs/1805.09801
这又是一个反复出现的故事:投入的人类因素越多,它的表现就越差。把人类因素去掉,它反而表现得更好。
现在,强化学习几乎被用于所有 LLM 系统中,主要与人类数据结合使用。
与 AlphaZero 的方法不同,这意味着强化学习实际上是根据人类偏好进行训练的。
这被称为基于人类反馈的强化学习(RLHF),在 LLM 中非常重要,是巨大的进步。
然而,David Silver 认为 RLHF 缺点同样明显:
这是把洗澡水和孩子一起倒掉了。
基于人类反馈的强化学习系统(RLHF)非常强大,但它们没有超越人类知识的能力。
例如,如果人类不知道某种新想法,并且低估了某些行动,那么系统永远无法学会找到最佳行为。
这就像人类在预先判断系统的输出。
从这个意义上说,它是不可靠的。
而只有这种可靠的反馈,才使系统能够迭代并发现新的事物。
人类数据是基于人类经验的。
所以 LLM 继承了人类从实验中发现的所有信息。
但在一些领域,人类数据根本不存在。
系统需要通过它自己的实验,它自己的试错,以及它自己的可靠反馈来自己弄清楚,这是好主意还是坏主意。
合成数据有助于解决数据匮乏的问题。
但与从人类数据中获得的上限类似,无论这些合成数据有多好,它们都会达到阈值,即这些合成数据不能让系统变得更强大。
而自我学习系统,将始终生成能够解决它正在遇到的下一个问题的经验。
这就是使用自我生成的经验与合成数据之间的区别。
而在许多领域,是不可能自我生成大量的数据经验。
RLHF 只能让系统学会选择人类更喜欢的招数。
如果在 AlphaGo 中使用 RLHF,它最终不会下出第 37 手棋。
因为它只会像人类认为的那样下出好棋,而永远不会发现人类未知的下棋方式。
在其他领域中,这也有很大的意义,比如在数学领域。
AlphaProof:「17 岁的数学家」
数学,这个神秘的领域,经过几千年的探索,人类取得了令人难以置信的成就。
AI 能否达到人类经过多年努力所达到的相同水平?
AlphaProof,一个依靠经验系统,来证明数学问题的系统。
有趣的是,AlphaProof 与现在的 LLM 工作方式完全相反!
LLM 倾向于大量产生幻觉(hallucinate),它们会编造东西。
如果要求 LLM 证明一个数学问题,它们通常会输出一些非形式化的数学内容,然后还要告诉你「相信我,这是对的」。

但实际上,有可能是对的,也有可能是错的。
AlphaProof 的优势在哪里?
DeepMind 想出了一个新的数学语言「Lean」,将数学定理和问题进行形式化。
可以想象一下,普通的 LLM 使用的是自然语言,人类文本;但是 AlphaProof 里面说的一种新的数学语言。
本质上,AlphaProof 在定理证明正确与否,和 AlphaGo 在棋盘上输赢是一样的。
进一步 David Silver 举了一个例子,DeepMind 使用了相同的 AlphaZero 代码来提高围棋、国际象棋和其他游戏的水平。

同样,可以把代码用在数学问题上。
这也让作为数学教授的女主持人惊呼「你们怎么敢的」!
国际奥林匹克数学比赛,每年的挑战者都是全世界各地非常年轻的天才们。
AlphaProof 能够取得银牌成绩,全世界只有大约 10% 的人能取得这个成绩。
很好奇,如果完全没有人类的数据输入,AlphaProof 的证明看起来是什么样子?是遵循人类风格的论证方式吗?
David 承认,他根本无法理解那些证明过程。

所以,DeepMind 请来了一位大神,Timothy Gowers,菲尔兹奖得主,前 IMO 选手,IMO 的多枚金牌得主。被称为超级大脑(Mega brain),可以理解为天才中的天才。
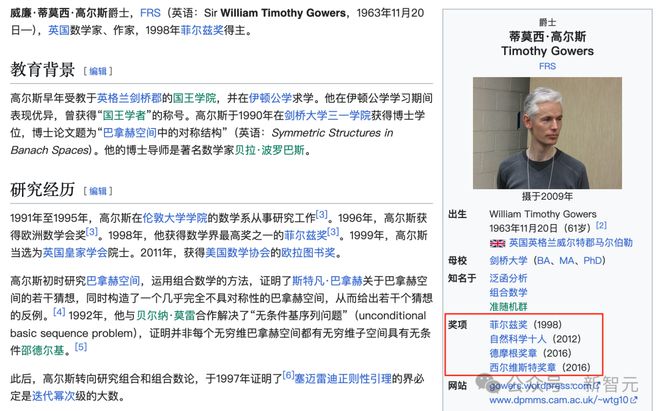
Timothy Gowers 实际上就是 AlphaProof 的裁判。
Timothy Gowers 认为 AlphaProof 在数学上的能力是一个巨大的飞跃。
David 将 AlphaProof 称为是一个「非常、非常、非常有才华的 17 岁数学家」,但最终我们想要的是一个「数学之神」。
当然,这条路在刚刚开始。
克莱数学研究所在 2000 年为七个不同的数学问题提供了百万美元的奖金。
人类数学家已经花费了四分之一个世纪的时间来尝试解决它们,目前而有一个被攻克了。
David 认为,下一个很有可能就会被 AI 解决。
因为如果有一个系统可以不断地学习、学习、学习,那么它的上限将是无限的,你可以想象这些系统在 5 年、10 年、甚至是 20 年后的样子。

而数学还有一个特点,数学可以形式化、符号化,是完全可以通过 AI 与 AI 交互而不断前进的领域之一。

经验如何泛化到混沌系统?
要么赢得一局围棋,要么没有。
数学证明要么是正确的,要么不是。
但是像 AlphaZero、AlphaGo 和 AlphaProof 这样的系统,经验如何泛化到一个没有明确的「获胜」指标,并且更加混乱的系统?
David 说这个问题其实就是为什么强化学习方法或者这类基于经验的方法,尚未打入所有主流 AI 系统中的原因。
但 David 也强调了也许人类指定他们想要什么,比如我想更健康,这种很「模糊」的目标转化为更量化的数字。
比如我想更健康可以「转化为」静息心率或者 BMI 等,这些指标的集合可以被用作强化学习的某种奖励。
并且只需要少量的数据就可以让系统为自己制定目标,因为这个目标可以是一个随着时间推移而自适应的数字组合。
指标暴政(tyranny of metrics)
将量化指标作为衡量成功的标准——强化学习的「奖励函数」——是否会导致一些无法预料的问题?
讨论中用一个词语,指标暴政来形容这种现象。
比如学生不断追求更高的考试分数,或者国家追求更高的 GDP,并且由于专注于目标,个体和集体很难再优化这个目标,往往就是为了这个目标而不择手段。
在人类世界中盲目追求一个指标时,它往往会导致不希望的后果。
奖励就够了吗?
在此前的采访中,David 曾经写过一篇文章表达了自己的立场,Rewar is Enough,这和目前的 LLM 技术路线的选择有很大的区别。

论文链接:https://www.sciencedirect.com/science/article/pii/S0004370221000862
强化学习就是走向 AGI(通用人工智能)所需要的一切,David 仍然是这样想的。
他举了个例子,目前依靠人类数据的 LLM 就像是地球上的化石能源,总有一天会被消耗掉的。
但是基于强化学习的系统,是可持续的能源——它可以持续生成、使用和学习,再生成更多并从中学习。
当然 David 说目前的 LLM 也很棒,目前的 AI 也是令人惊叹,令人难以置信的东西。
但是!当你停下来思考时,围绕 AI 讨论的思想多样性确实在收窄。
人们不断地讨论 LLM,LLM 也不断地超出人们的期待。
关于大模型的讨论已经吸走了我们在讨论 AI 时的过多的「氧气」。
而且现在也出现一种声音:我们已经达到了可用人类数据的极限。
但就像 David 所说的一样,如果我们想要追求一种可持续的「智能能源」。
如果我们真的想要超越人类智能,也许现在是时候摆脱人类(数据)了。
参考资料:






