
新智元报道
编辑:Aeneas KingHZ
OpenAI 首席财务官 Sarah Friar 探讨了通往 AGI 的发展路径,目前 OpenAI 已到达第三阶段:智能体(Agnent)。除 Opeator 和深度研究 Deep Research 智能体外,OpenAI 即将发布全球最强编程智能体。
OpenAI,正引领生成式 AI 的革命浪潮。
这家公司如何确立行业领先地位?又采取了哪些策略保持竞争优势?
2025 年 3 月 5 日,在伦敦举行的「高盛颠覆性科技峰会」中,OpenAI 首席财务官 Sarah Friar 探讨了通往 AGI 的发展路径,以及资本在 AI 竞赛中的关键作用。

Sarah Friar 曾任高盛科技股权研究主管,会议中与高盛全球银行与市场部联席主 Dan Dees 展开深度对话,时长 30 余分钟。
她表示:「我们可能已经接近了 AGI,但世界尚未学会如何最大化地利用它」。
OpenAI,正在全速前进,全面出击:从数据中心到应用层,各部分都在创新。
左:高盛全球银行与市场部联席主 Dan Dees 先生,右:OpenAI 首席财务官 Sarah Friar 女士
AI 涌起,适逢其会
AI 风起云涌,而 OpenAI 锐不可当,可以说是目前最具影响力的技术领域中最具影响力的公司。
在去年 OpenAI 向她抛出橄榄枝时,Sarah Friar 实在很难拒绝。

去年 6 月 10 日,Sarah Friar 加入 OpenAI 担任首席财务官
在她看来, AI 浪潮,确实比迄今为止看到的其他科技浪潮都要宏大,虽然她错过了个人电脑革命。
加入 OpenAI,投身 AI 科技浪潮,她觉得是个人难得的机遇和幸运。
但在互联网崛起时,Sarah Friar 在斯坦福商学院进修——2000 届毕业生都记得,那时互联网泡沫正膨胀。
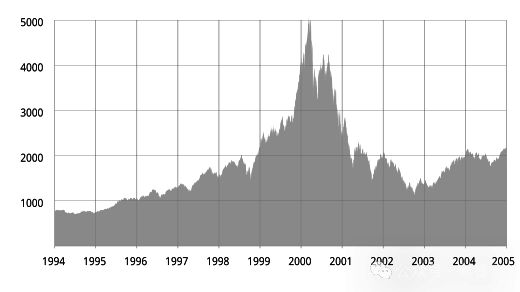
互联网泡沫,也称 dot-com 泡沫或 dot-com 热潮在上世纪 90 年代末期并最终于 2000 年 3 月 10 日达到顶峰的一次股市泡沫。从 1995 年至 2000 年 3 月的高峰期,投资于 NASDAQ 综合指数的资金增长了 800%,而在 2002 年 10 月之前,该指数又从其峰值下跌了 78%,回吐了泡沫期间的所有涨幅
随后她又目睹了持续几年的硅谷寒冬。
接着是移动互联网的兴起如何重塑企业,后来我在高盛的事业轨迹,坦白说也正是围绕着向云计算的转型展开。
而如今站在浪潮的另一端,从宏观世界格局到政府政策,再到企业级应用,全方位探讨 AI 的影响——这种角色转换令她无比振奋。
而最近,OpenAI 关注的焦点是 AI 基础设施。
这感觉就像是「云计算黎明」再次来临,尽管 AI 的架构和构建方式完全不同。
对亲身经历过「云计算黎明」的人来说,这波 AI 浪潮更加迷人。
OpenAI 如何用 ChatGPT 赋能工作
Sarah Friar 认为当今世界上没有哪位 CEO 或企业领袖会意识不到 AI 部署的紧迫性,甚至都担心自己已经落后了。
作为 OpenAI 的 CFO,她刚加入时最迫切的需求就是:「先要弄明白——我的团队,就拿财务部门来说,到底该如何运用 ChatGPT?」
但当时的情况是,由于 OpenAI 正在大规模招聘,许多员工来自尚未应用 AI 的传统企业。
这导致团队在 AI 应用方面出现了明显的认知断层——
大家对「谁来做什么、为什么做」缺乏统一理解,整体协作也缺乏组织性。
作为团队管理者,她采取的第一个举措就是亲自组织了一场黑客马拉松:召集销售团队和解决方案工程师,花了一下午进行讨论。
从最基础的环节开始, 用纸笔罗列出日常工作中那些高度重复性的任务。
随后将人员按职能分组——税务团队一组、采购团队一组、投资者关系团队一组,通过小组讨论,让初步的想法碰撞。
即便采用如此简单的方式,现场已经迸发出惊人的热情。
她记得,当时投资者关系团队正在筹备一轮大规模融资,深陷尽职调查「地狱」。
OpenAI 很快发现,那些源源不断的尽调问题虽然细节各异,但核心模式高度重复。

当时他们经常加班到深夜,反复经历这样的场景:「啊,这位投资人问过类似问题——快找出之前的回复,稍作修改再发出去。」
直到开发出能自动回答这些问题的定制 GPT 解决方案时,整个团队在会议室里简直高兴得手舞足蹈、欢呼雀跃。
这让她深刻意识到:必须让团队成员从第一性原理出发,真正理解 AI 带来的普适性效能提升。
而 ChatGPT 的深度研究,已经帮助 OpenAI 解决了关于 GPU 融资的分析问题。
她的团队使用了深度研究,获取了一份报告,得到了 OpenAI 内部员工的认可:「和两位 MD、三位 VP、六位助理和十位分析师的团队,DeepResearch 所做的事情要好得多。」
GPT-3 到 GPT-4
从 GPT-3 过渡到 GPT-4,OpenAI 花了大约一年半到两年的时间。
去年,他们首次部署了推理功能,也就是o系列模型。
这意味着从一个更倾向于预测、快速响应的实时回答模型,转变成了能够更像人类一样推理的模型。
有一种简单的描述方式是这样的:
如果想象一下你做填字游戏的时候,比如一个横向的单词有五个字母,你认为可能是三个不同的词之一。
你填写了一个单词,然后转向下一个竖向的线索,发现不对劲,第二个字母应该是A。
这就意味着之前的那个答案是错误的,你需要划掉并重新填入另一个词。
所以它会自我回溯。
这一点对于 AI 智能体非常重要。
但如今,OpenAI 远远不止这些。
AI 基础设施 2.0:AI 工厂
OpenAI 正深入数据中心,因为他们认为现在正处于 AI 基础设施的第二版本(V2),或者如黄仁勋所称的「AI 工厂」。
数据中心创造了很多知识产权(IP),对 OpenAI 来说拥有这些 IP 非常重要。
想象一下亚马逊在电子商务领域取得巨大成功时的情景。他们看到 AWS(亚马逊网络服务)开始成形。
就像在这个阶段,如果他们决定将这一部分外包给新兴的谷歌或其他公司,那会是怎样的情形呢?如果当初亚马逊将 AWS 的所有知识产权都拱手让人,那么今天这家公司将会是怎样的不同呢?
如今,AWS 在云计算市场中占据了 40% 的市场份额,并拥有 38% 的运营利润率。
因此,拥有基础设施能力非常惊人。
但现在 OpenAI 不仅停留在模型层面,还向上扩展到了 API 层,这使 OpenAI 将影响力扩展到企业和开发者。
然后再上一个层次进入应用层面,即如何推动功能特性的发展,让消费者在个人生活和工作中都喜欢得到的东西。
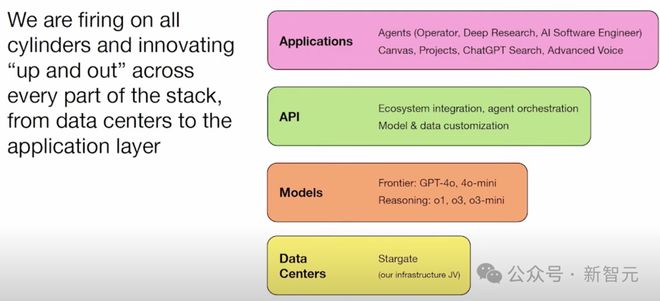
所以,现在在 ChatGPT 的前端页面,用户可以用 Sora 生成视频,可以进行深度研究报告,可以搜索,可以创建项目,可以编写代码,还可以创建写作画布。
OpenAI 的目标就是不断加载这些功能。
然后她意识到,「ChatGPT 已经有很强的用户粘性了。我不打算离开它。」
从商业角度来看,这是件好事。这就是 OpenAI 目前所处的位置。
接下来,她介绍了 OpenAI 实现通用人工智能(AGI)的五个步骤。
通向 AGI 的 5 个阶段
2023 年,是实时预测响应之年:聊天机器人 Chatbot 兴起。
2024 年,OpenAI 把推理带上了台面。
2025 年,将是 AI 智能体的一年。

OpenAI 实现通用人工智能(AGI)的五个步骤
大概从去年第三季度或第四季度,OpenAI 开始讨论这个话题。
现在,Agent 已经成为整个 AI 行业公认的术语。
但这里的 AI 指的是能够独立为你完成工作的智能体(agents)。
这不是虚无缥缈的概念。
实际上,OpenAI 已经有三项功能在运行:
-
深度研究(Deep Research):这是一个生成深入的研究报告的工具。
-
操作员(Operator):允许任务工作者在网络上执行一些可能需要后台处理时间的任务。
-
第三个即将推出的功能称之为A-SWE(Agentic Software Engineer)。
A-SWE 不仅仅是像 Copilot 那样,增强现有软件工程师的工作能力,而是一个真正能够构建应用程序的自主软件工程师。
它可以接受需求,并去实现它。但不仅仅是开发,它还做了所有软件工程师讨厌去做的事情。
它可以从你给任何其他工程师的 Pull Request(PR)开始,去构建应用程序。
不仅如此,它还会完成所有软件工程师讨厌去做的事情:
它自己做代码质量保证、错误测试和调试。
并且它还编写文档。
这些都是所有软件工程师不愿意去做的任务。
因此,它可以成倍地提高软件工程团队的效率。
之后是 AGI 的第四阶段:创新的世界。
在创新的世界,不再只是关于当今世界存在的知识,而是如何扩展这些知识。
实际上,从教授和学者那里听到的是,他们发现模型在专业领域中,提出了新的想法。
目前这些想法还需验证,但 OpenAI 千真万确地收到了这样的反馈。
长远来看,代理组织(agentic organizations)将是未来的发展方向。
AGI 近在咫尺
OpenAI 仍然有迄今为止最领先的模型:o3。
从软件工程领域中,o3 竞赛性编程的表现:在全球排名第 175 位的竞赛性程序员。
在数学竞赛中,它只错了一道题。
而在博士级别的科学领域,它在物理、化学、生物学等方面都达到了博士水平。
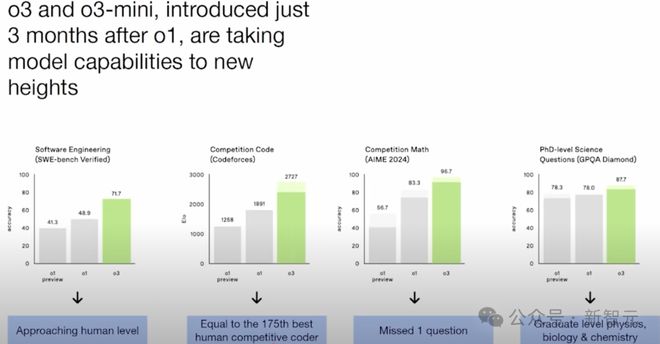
4 个被广泛认可的基准测试,用来衡量 AI 是否正在向 AGI(通用人工智能)迈进,即是否真正达到了人类智能甚至超越了人类智能的水平
OpenAI 的产品团队认为,o3 mini 已经成为了全球最具竞争力的程序员。
在 Sarah Fryer 看来,如今已经非常接近 AGI 了。
也就是说,AI 系统能够承担世界上大多数真正有价值的、人类的工作。
但可以肯定地说,作为一个世界共同体,我们还并未充分发挥它的潜力。
如今,有 3 个 scaling law 正在发生。
一个是预训练,也就是让通用模型变得更聪明。这就需要更多的数据和更先进的算法专业知识。在更多算力的支持下,研究人员可以发挥更大的作用。
这就意味着,要想成功,就必须投入大量的资金。
在 GPT-3、GPT-4、GPT-5 这样的大模型上,计算规模就在呈对数增长。
然后,就进入了后训练阶段。
比如我们想创建一个需要诊病的模型,就需要对它微调,让它专注于医学。
而第三个阶段——推理时计算,就是让这辆「汽车」能切换到运动模式的时刻。
此时,需要在真正的赛道上行驶,从四驱模式切换到运动模式。
以上,就是关于扩展性的三条定律。
OpenAI 的研究者,已经推出了「强化微调」技术。
他们发现,其实并不需要很多信息,就能让模型在一个特定领域展现出显著的性能提升。
但关键在于,我们能否达到那个具体的领域?如果你想研究神经疾病,比如退行性疾病的结果,你能在这个特定领域获得足够的信息吗?
即使是一点点的信息,也会极大提升模型的实用性。
星际之门,为什么需要 5000 亿
按照 OpenAI 的说法,星际之门需要投资 5000 亿美元在计算能力上,或者说,它需要 10 吉瓦的算力。
这个数字是怎么得出来的?

奥特曼在白宫参与 5000 亿美元的 Stargate 计划发布会
这是通过预训练扩展、后训练扩展和推理时扩展这三个 scaling law。
在模型开发的每个阶段,都会需要越来越多的算力。
可以说,OpenAI 没有推出某些模型,就是因为没有足够的计算资源。
Sarah Friar 表示,自己是个糟糕的 CFO。
Sora 差不多在前年 2 月或 3 月就准备好了,但直到差不多去年 12 月,OpenAI 才真正推出了它。
甚至到现在,Sora 也还没有完全上线。
OpenAI 选择的,是推出深度研究,因为他们知道商业界非常喜欢这个特性。
因为没有足够的算力投入业务,Sarah Friar 承认,自己每天做出最糟糕的决定,就是不给研究者提供最有价值的资源——研究所需的算力。
她甚至透露:很多时候,Sam Altman 来上班时就会生她的气,因为她没有提供足够的算力。
为什么她会陷入这种境地?
因为在两三年前,那些拍板决定算力决策的人,根本想象不到如今算力需求的增长会如此之快。
两年时间里,OpenAI 的周活用户就达到了 4 亿,收入每年都翻了三倍。
现在,整个爱尔兰的负载是 7 吉瓦,整个国家的使用量都比 OpenAI 需要的 10 吉瓦少。
而在她看来,在三年后当人们回过头来,会觉得这时的人们对 5000 亿这个数字神经紧张,简直是大惊小怪。
所以,该如何扩大规模?电力来源于哪里?是否需要培养人力?
事实证明,电工、暖通空调人员等,都是真正能够制约建设的资源。
因此,美国政府也会对星际之门特别感兴趣,因为它既是一种财政投资,也是有助于在经济上保持领先地位。
而 DeepSeek 也让人看到,AI 正处于激烈竞争中。
OpenAI 目前的关注点在于算力、研究人员、数据。
他们需要寻找地点和电力,他们需要平整地面,建设数据中心,填充设备,购买 GPU。
OpenAI 需要真正证明:它有能力成功应对挑战。
参考资料:






