
新智元报道
编辑:KingHZ 英智
只用 6GB 显存的笔记本 GPU,就能生成流畅的高质量视频!斯坦福研究团队重磅推出 FramePack,大幅改善了视频生成中的遗忘和漂移难题。
昨天,视频生成进入了超低显存时代!
这次出手的是 AI 界的「赛博佛祖」、ControlNet 的作者、斯坦福大学博士生张吕敏。
他提出了以渐进式生成视频的新方法——FramePack,才过去一天对应的开源项目已有 2600 多 star。
新方法采用独特的压缩结构和抗漂移采样方法,有效缓解了遗忘和漂移难题,提升了视频质量和连贯性。

论文链接:https://arxiv.org/abs/2504.12626
项目链接:https://lllyasviel.github.io/frame_pack_gitpage/
现在只要一台 RTX 3060 6GB 笔记本,就能用单图生成5 秒、30FPS 共 150 帧的视频。



从古代仕女图到卡通形象,通通一键动起来!


相同的配置,还可以生成单图生成60s 的共 1800 帧视频。
不仅如此,作者还开源了功能完备的桌面级软件,提供 GUI,使用非常简单。
在左侧上传图片,并在下方输入提示词,右侧就开始显示生成的视频及预览。
由于采用逐段落帧预测模型,视频会持续延长生成:
-
每个段落会显示独立进度条。
-
系统会实时预演下一段落的潜在空间效果。

a jellyfish dances in the sea(一只水母在海中起舞)
网友惊呼:这下视频生成要进入超超超低显存时代了,迈入大众 GPU 了!马上就去实测!

简单总结一下,FramePack 的特点有:
-
使用 13B 模型和 6GB 显存的笔记本 GPU,能够以完整的 30 FPS 速率扩散(生成)数千帧。
-
在单个 8xA100/H100 节点上,能够以 64 的批大小微调 13B 视频模型,适用于个人或实验室。
-
RTX 4090 生成速度可达 2.5 秒/帧(未优化)或 1.5 秒/帧(使用 teacache)。
-
没有时间步长蒸馏。
-
技术上是视频扩散,但使用体验上更接近图像扩散。
FramePack
FramePack 是一种全新的神经网络结构:下一帧预测(next-frame prediction model 或 next-frame-selection prediction model )。
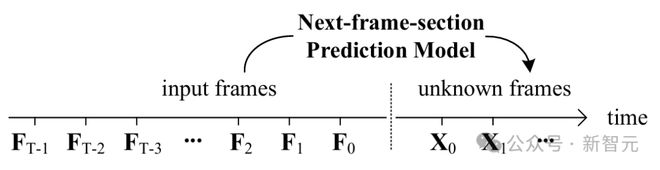
新方法旨在攻克视频生成中的遗忘和漂移问题。
FramePack 的设计理念十分巧妙,它根据输入帧的重要性进行压缩。
预测下一帧时,输入帧的重要性并不相同。
比如在人物跑步的视频里,离预测时刻越近的帧,对预测人物下一帧的动作和位置就越关键。
FramePack 通过定义长度函数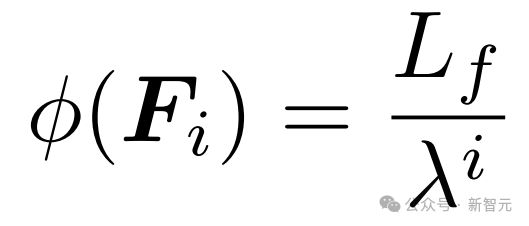
来确定每个帧的上下文长度,其中λ>1 是压缩参数,L_f是每帧的基础上下文长度。
通过这个函数,越不重要的帧,上下文长度被压缩得越厉害。
经过压缩处理,总上下文长度会遵循几何级数变化:
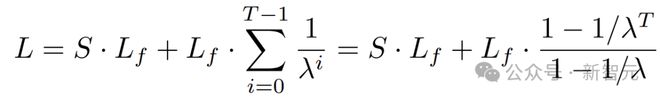
当视频帧数T趋向于无穷大时,总上下文长度会收敛到固定值:
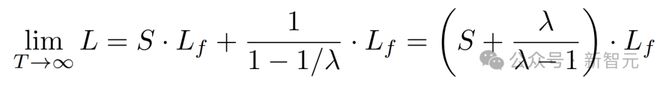
这意味着,无论输入视频多长,FramePack 都能将总上下文长度控制在固定上限内,避免因输入帧过多导致计算量爆炸,有效解决了模型处理大量帧时的计算难题。
考虑到硬件对计算的优化偏好,论文中主要讨论λ=2 的情况。
在实际应用中,FramePack 还有一些细节要处理。比如针对不同压缩率的输入投影,使用独立的神经网络层参数能让学习过程更稳定。
当输入帧长度非常大时,FramePack 提供了三种处理尾部帧的方式:
-
可以直接删除尾部帧。
-
也可以让每个尾部帧增加一个潜在像素来扩展上下文长度。
-
或者对所有尾部帧进行全局平均池化,然后用最大的内核处理。
在实际测试中发现,这几种方式对视觉效果的影响相对较小。
另外,由于不同压缩内核编码的输入上下文长度不同,FramePack 还需要进行 RoPE 对齐。
FramePack 变体
为满足不同应用场景需求,提升视频生成质量,FramePack 还有多种变体。

一种变体是重复和组合压缩级别,提高压缩率。
比如在图1-(b)中,采用 4 的幂次方序列,每个级别重复 3 次,这样能让帧宽度和高度的内核大小保持一致,使压缩更紧凑。
压缩也可以在时间维度上进行,如图1-(c)所示,使用 2 的幂次序列,在同一张量中编码多个帧,这种方式与 DiT 架构天然契合。
FramePack 还创新了帧重要性的建模方式。
除了基于时间接近度判断重要性,在图1(d)中,给最旧的帧分配全长上下文,在需要强调初始信息的应用场景中,能更好地保留关键信息。
图1(e)将起始帧和结束帧视为同等重要,同时对中间帧应用更高的压缩。
在图像到视频生成任务中,这种方式很有效,因为用户提供的初始帧往往承载关键信息,赋予它们更高重要性可以提升最终生成视频的质量。
抗漂移采样
漂移一直是视频生成中的顽疾,FramePack 提出的抗漂移采样方法为这一问题提供了新思路。
研究发现,漂移通常发生在模型仅依赖过去帧进行预测的因果采样过程中。
如果模型能获取未来帧的信息,哪怕只有一帧,就能有效避免漂移。基于这一发现,FramePack 提出了双向上下文的抗漂移采样方法。
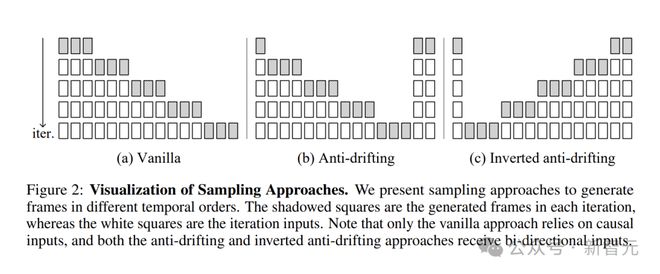
传统采样方法,如图2-(a)是按时间顺序迭代预测未来帧,而抗漂移采样则不同。
改进后的方法,如图2-(b),在第一次迭代时,同时生成起始和结束部分,后续迭代再填充中间的间隙。
这样一来,结束帧在一开始就被确定下来,后续生成的帧都朝着这个目标靠近,有效防止了漂移。
还有一种反向抗漂移采样方法,如图2-(c),这种方法在图像到视频生成任务中表现出色。
它将用户输入图像作为高质量的第一帧,然后按反向时间顺序生成后续帧,不断优化生成的帧以接近用户输入的第一帧,从而生成高质量的视频。
FramePack 实力如何?
为了验证 FramePack 的性能,研究人员进行了大量消融实验。
FramePack 基于 Wan 和 HunyuanVideo 两种基础模型,涵盖了文本到视频和图像到视频的生成结构。
数据集方面,遵循 LTXVideo 的数据集收集流程,收集了多种分辨率和质量水平的数据。
为全面评估 FramePack 的性能,实验采用了多种评估指标,包括多维度指标、漂移测量指标和人工评估。
多维度指标评估涵盖清晰度、美学、运动、动态、语义、解剖结构和身份等多个方面。
当视频发生漂移时,视频开头和结尾部分在各种质量指标上会出现明显差异。
作者提出了起止对比度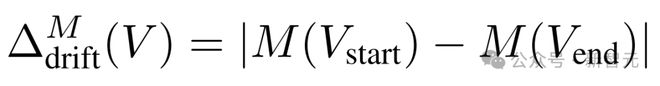
,其中V是测试视频,V_start 代表前 15% 的帧,V_end 代表最后 15% 的帧,M可以是运动分数、图像质量等任意质量指标。
该指标通过计算起始和结束部分质量指标的绝对差值,直观反映出漂移的严重程度,并且由于使用绝对差值,不受视频帧生成顺序的影响。
研究人员通过A/B测试收集用户偏好,每个消融架构会生成 100 个结果,A/B测试在不同的消融架构中随机分配,确保每个消融架构至少有 100 次评估。
最终,通过 ELO-K32 分数和相对排名反映用户对视频的喜好程度。
消融实验结果
在采样方法对比中,反向抗漂移采样表现最为突出。
它在 7 个评估指标中的 5 个上取得最佳成绩,并且在所有漂移指标上都表现优异。这充分证明了反向抗漂移采样方法在减少误差累积、提升视频质量方面的有效性。
从生成帧数的角度来看,人工评估显示,每段生成 9 帧的配置在 ELO 分数上,明显高于生成 1 帧或 4 帧的配置,说明生成 9 帧能给用户带来更好的视觉感知。
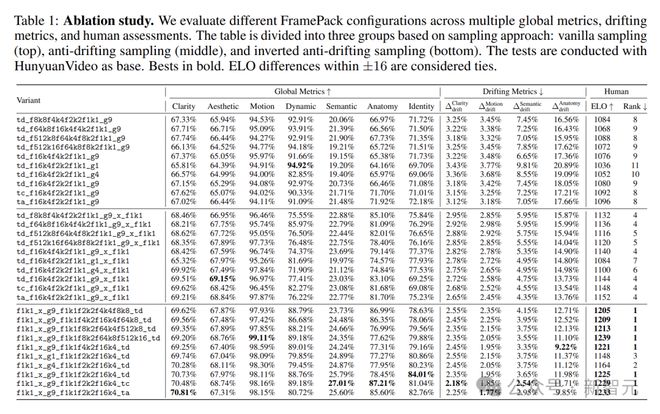
普通采样虽然在动态指标上获得最高分数,但这很可能是漂移效应导致的,并非真正的质量提升。
研究人员还发现,同一采样方法下,不同配置选项之间的差异相对较小且具有随机性。
这意味着采样方法的选择对整体性能差异的影响更为关键,而具体配置选项的微调对性能的影响相对有限。
与替代架构的比较
为全面评估 FramePack 的性能,研究人员将其与替代架构做了对比。
这些替代架构包括重复图像到视频、锚帧、因果注意力、噪声历史和历史引导等方法,它们分别从不同角度尝试解决视频生成中的长视频生成、计算瓶颈和漂移等问题。
FramePack 在多个方面表现出色。
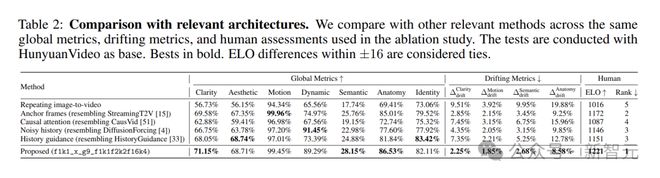
FramePack 在 3 个全局指标上取得最佳结果。漂移指标方面,更是全面领先,证明其解决漂移问题的有效性。
从人工评估的 ELO 分数来看,FramePack 得分最高,表明在主观感受上,生成的视频质量更受认可。
FramePack 为视频生成技术带来新突破。它通过独特的压缩结构和抗漂移采样方法,有效缓解了遗忘和漂移问题,提升了视频生成的质量和效率。
作者介绍
Lvmin Zhang

Lvmin Zhang 是斯坦福大学计算机系的博士生,主要研究领域为计算机图形学和生成模型。
在今年的 ICLR 投稿中,经过 rebuttal,他成功拿下最近几年的首个满分论文!

在 ICLR 2025 满分论文中,作者介绍了一种扩散式光照编辑模型的训练方法
Lvmin Zhang 还是 ControlNet 的作者,这是一种创新的神经网络架构,显著增强了预训练扩散模型的条件控制能力。
参考资料:






