
新智元报道
编辑:桃子
【新智元导读】视觉 AI 终极突破来了!英伟达等机构推出超强多模态模型 DAM,仅 3B 参数,就能精准描述图像和视频中的任何细节。
有了 AI,谁还愿意用手配「字幕」?
刚刚,英伟达联手 UC 伯克利、UCSF 团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅 3B 参数。

论文地址:https://arxiv.org/pdf/2504.16072
正如其名 Describe Anything,上传一张图,圈哪点哪,它即可生成一段丰富的文字描述。

即便是一段视频,DAM 也能精准捕捉到白色 SUV,给出详细的描述。

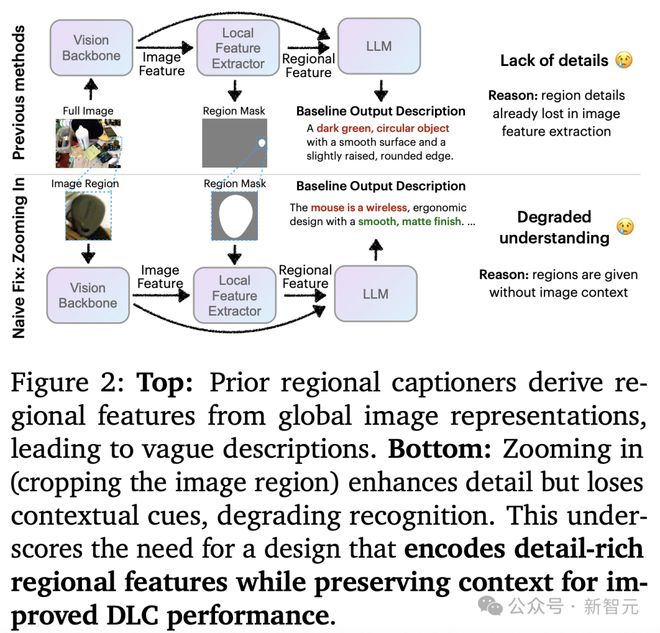
DAM 是一个专为详细局部标注(DLC)而设计的模型,即为特定区域生成详细且精确的描述。
通过两大创新,研究人员在细节与上下文之间找到平衡:
· 焦点提示:对目标区域进行高分辨率编码,就像给模型配备了一副「放大镜」,清晰捕捉到局部区域细微特征
· 局部视觉骨干网络:将精确定位的特定区域,与上下文无缝整合
换句话说,DAM 不仅能放大细节看,还能放眼全局看,无论是静态图,还是动态视频,都能做到游刃有余。
网友惊叹道,「终极视觉 AI 突破」!

AI 用「放大镜」看世界
在项目主页中,英伟达等研究团队放出了更多精彩 demo。任何人通过点、框、涂鸦或掩码的交互,即可一键生成描述。
上传一张柯基在草地上欢快奔跑的图,选中柯基,让 DAM 去描述:
一只中等体型的狗,拥有浓密的红棕色毛发,腹部和腿部为白色。这只狗尾巴蓬松,耳朵尖立,戴着带有银色吊牌的红色项圈。它张着嘴露出牙齿,舌头伸在外面。狗呈奔跑姿势,前腿向前伸展,后腿向后伸直。

一只被挤到犄角旮旯的猫星人,DAM 是这样配文的,「一只白猫,耳朵呈浅橙色,鼻子是粉色的。猫咪表情放松,眼睛微微闭着,全身覆盖着柔软的白毛」。

再比如,随手涂鸦一栋高楼,DAM 可以不断放大细节,给出这幢楼更细致的描述:
一座现代风格的摩天大楼,采用流线型矩形设计,外立面排列着间距均匀的竖向条形窗。建筑呈阶梯式结构,每一层段都比下层略微内缩,形成错落有致的退台造型。建筑幕墙主要由反光玻璃面板构成,整体呈现出极具现代感的抛光效果。

甚至,DAM 看着视频中的一头牛,就能直出一篇经典「小作文」:

一幅描绘棕褐色奶牛的动态序列图:这头毛色浓密的奶牛臀部带有浅色斑块,初始画面中它微微低头,透着安详的神态。随着动作展开,奶牛开始稳步前行,四肢舒展着节奏分明的步态,尾梢的簇毛随每一步轻摆,为行进增添流畅韵律。它始终保持挺拔的站姿,略微弓起的背部线条透出放松状态,肌肉结实的腿部稳健地向前迈进。整个运动过程中,奶牛保持着均匀从容的步调,每一个动作都流畅而不迫,展现出宁静自若的生命姿态。

DAM 如此厉害,是如何做到的?
DAM 技术架构,精准捕捉细节
与传统图像描述(概括整个场景)不同,DLC 聚焦于用户指定的局部区域,来生成细致入微的描述。
想象一张照片中一只猫,你不仅需要描述「一只猫在窗台上」,还要深入些几「猫的毛发呈现柔软和灰色条纹,耳朵微微倾斜,眼睛在阳光下闪着琥珀色的光芒」。

可以看出,DLC 的目标是捕捉区域的纹理、颜色、形状、显著部件等特征,同时也要保持与整体场景关联。
而在视频领域中,DLC 挑战更大。
模型需要追目标区域在多个帧中的变化,描述其外观、交互、和细微动态的演变。
为了应对 DLC 复杂需求,Describe Anything Model 引入了两大核心创新,让局部细节与全局上下文完美平衡。
焦点提示(Focal Prompt)
通过「焦点提示」机制,DAM 能够同时处理全图和目标区域的放大视图。
这确保它在捕捉细微特征同时,不丢失整体场景的背景信息。
局部视觉骨干网络(Localized Vision Backbone)
DAM 的视觉骨干网络通过空间对齐的图像和掩码,融合全局与局部特征。
利用门控交叉注意力层,模型将详细的局部线索与全局上下文无缝整合。
新参数初始化为0,保留了预训练能力,从而生成更丰富、更具上下文关联的描述。
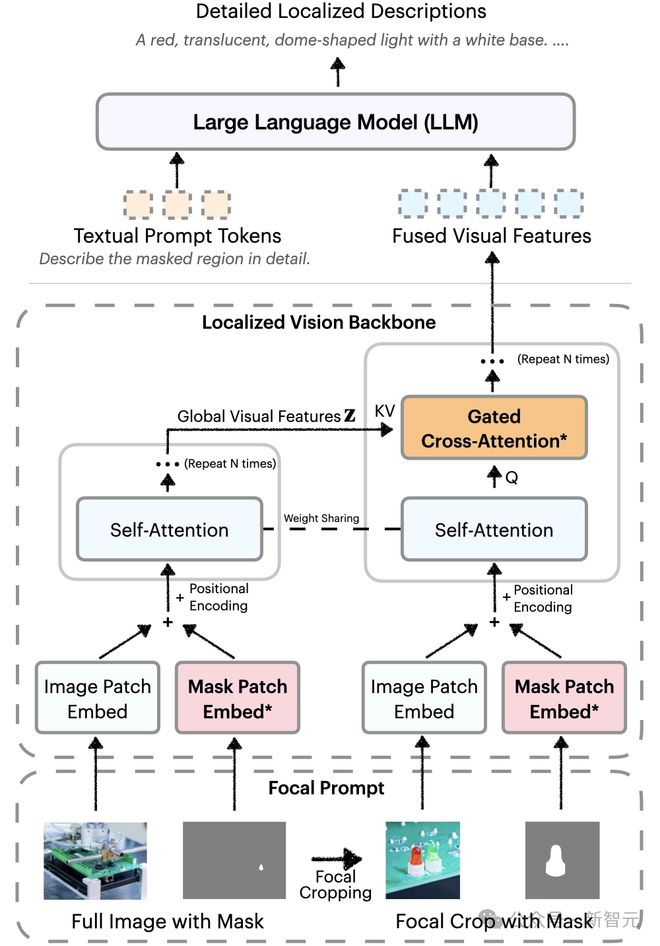
这种架构让 DAM 在生成关键词、短语,甚至是多句式的复杂描述时,都能保持高精度和连贯性。
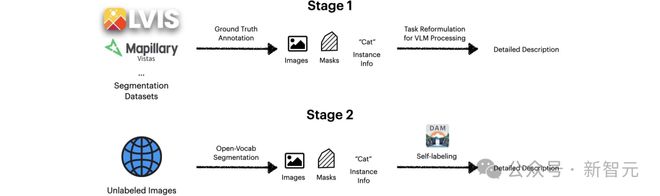
DLC-SDP:破解数据瓶颈
要知道,高质量的 DLC 数据集极为稀缺,限制了模型的训练。为此,研究团队设计了基于半监督学习的流水线(DLC-SDP),通过两阶段策略构建大规模训练数据。
阶段一,是从分割数据集扩展。利用现有分割数据集短标签(猫),通过视觉-语言模型生成丰富的描述(灰色短毛猫,耳朵直立。
阶段二,自训练未标记的图像,通过半监督学习,DAM 对未标记的网络图像生成初始描述,并迭代精炼,形成高质量的 DLC 数据。
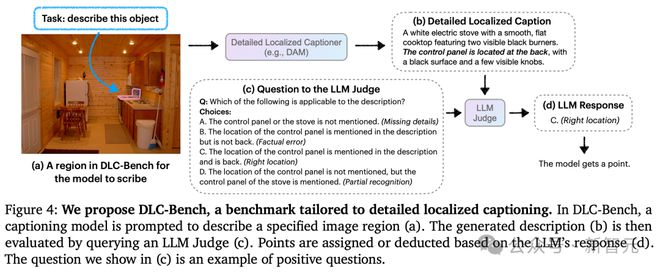
DLC-Bench:重定义评估标准
那么,如何公平地评估 DLC 模型。
传统方法主要依赖文本重叠,但这无法全面反映描述的准确性和细节。
为此,研究团队提出了全新基准 DLC-Bench。通过 LLM 判断,检查描述的正确细节和错误缺失,而非简单对比文本。
DAM 仅能生成详细描述,还具备强大的灵活性和交互性。
指令控制描述
你可以根据需求调整描述的详细程度和风格。
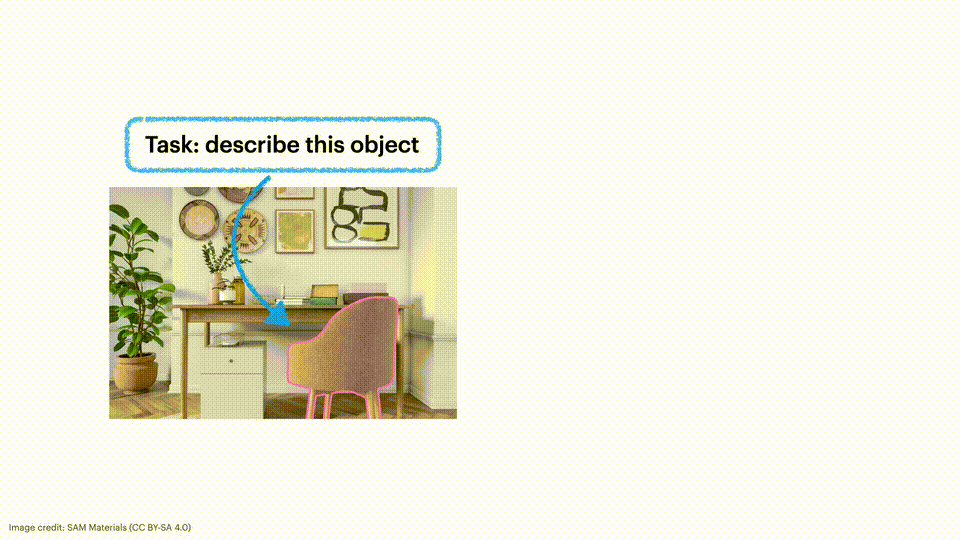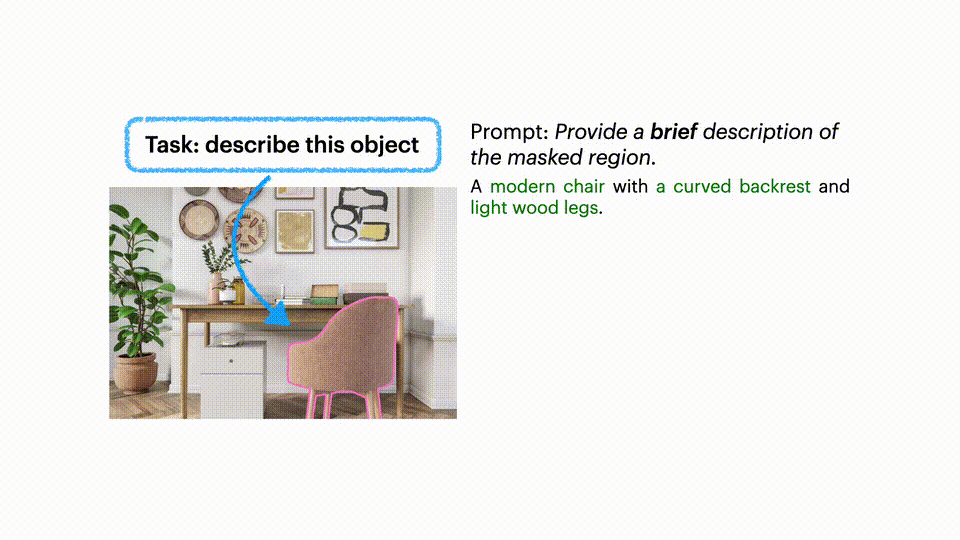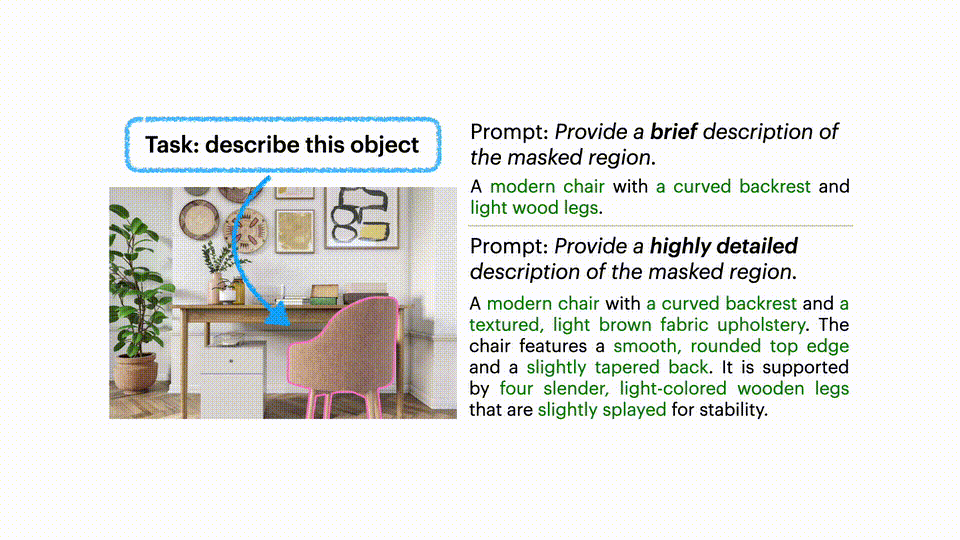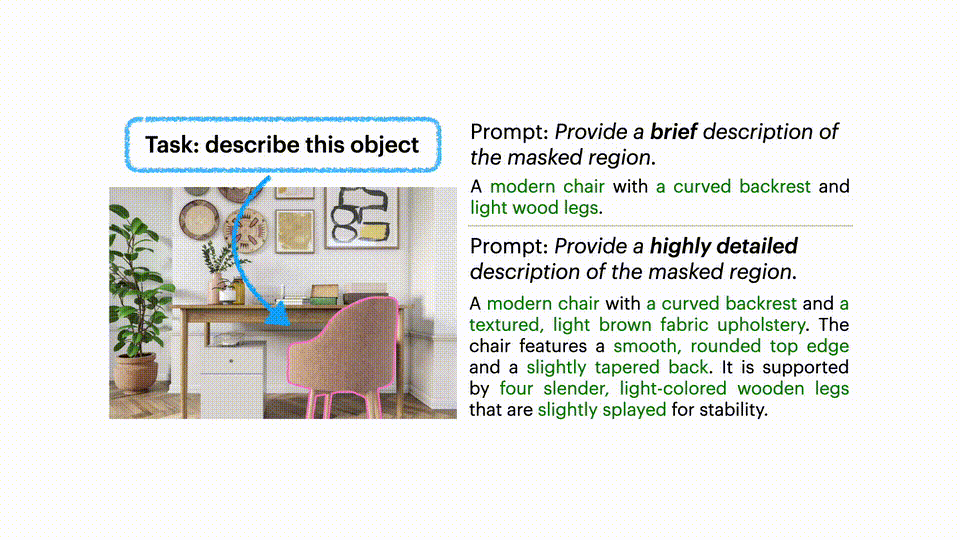
零样本区域问答
而且,无需额外训练,DAM 就能回答关于特定区域的问题。

碾压 GPT-4o,刷新 SOTA
在 DLC-Bench 和其他 7 个涵盖图像与视频的基准测试中,DAM 全面超越现有模型,树立了新的标杆。
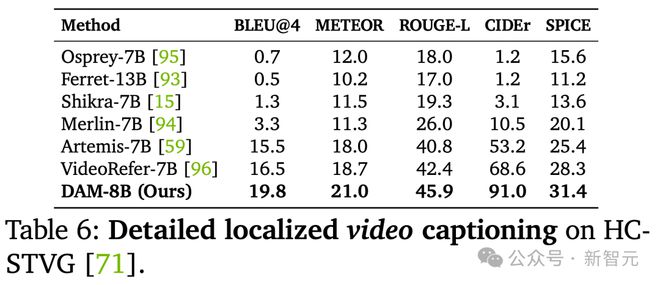
如下表 2 所示,DAM 在具有挑战性的 PACO 基准测试中表现出色,创下了 89 高分。
而在零样本评估在短语级数据集 Flickr30k Entities 上,新模型相比之前的最佳结果平均相对提升了 7.34%。
此外,零样本评估在详细描述数据 Ref-L4 上,DAM 在基于短/长语言的描述指标上分别实现了 39.5% 和 13.1% 的平均相对提升。
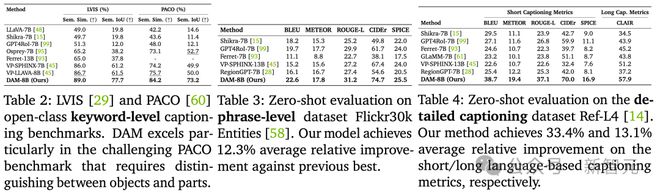
在研究人员提出的 DLC-Bench 测试中,DAM 在详细局部描述方面优于之前的仅 API 模型、开源模型和特定区域 VLM。
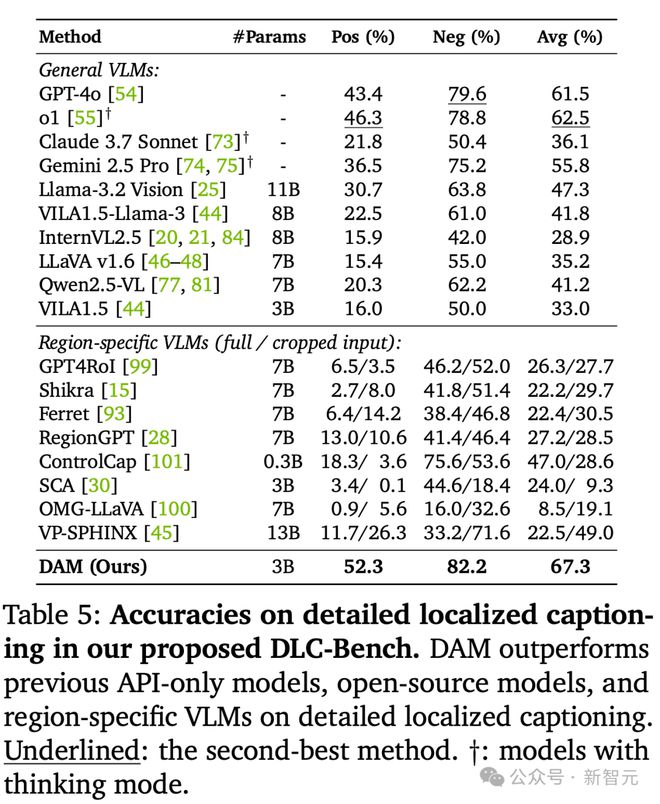
下表 6 所示,DAM 在详细局部视频字幕方面刷新 SOTA。
总而言之,DAM 的优势主要有三大点:更详细、更准确;更少幻觉;多场景适用。
它的强大能力为众多应用场景打开了大门,未来诸如数据标注、医疗影像、内容创作等领域,都可以加速落地。

作者介绍
Long (Tony) Lian

Long (Tony) Lian 目前是 UC 伯克利电子工程与计算机科学博士研究生,师从 Adam Yala 教授和 Trevor Darrell 教授。
他的研究主要聚焦于,通过强化学习(RL)开发具备推理能力的大模型(LLM)与视觉语言模型(VLM)。
此前,他曾在英伟达研究院 Deep Imagination Research 团队实习。
Long (Tony) Lian 本科毕业于 UC 伯克利计算机科学专业,师从 Stella Yu 教授。
参考资料:






