
新智元报道
编辑:编辑部 NXs
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR 被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
最近,以推理能力为核心的大语言模型已然成为了主流,比如 OpenAI o 系列模型、DeepSeek-R1 等等。
推理模型在处理数学和编程等复杂逻辑问题方面取得了显著突破。
相比于之前依赖人工标注进行指令微调的方法,这一突破的关键在于可验证奖励强化学习(RLVR)。
RLVR 从预训练模型或经过长思维链(CoT)微调的模型出发,利用简单、自动的奖励信号通过强化学习进行优化。
在数学问题中,如果模型给出的答案和正确答案一致,或者编程任务里,代码能通过单元测试,模型就能得到奖励。这摆脱了对大量人工标注数据的依赖,具备很好的可扩展性。
RLVR 被认为能激发模型进行自主推理,比如枚举、反思和优化,这些能力恰恰是基础模型所欠缺的。
因此,RLVR 被视为是打造自我进化大模型的路径,可持续提升模型推理能力,甚至接近 AGI。
然而,尽管 RLVR 在经验上取得了成功,但在追求不断自我进化的推理能力过程中,一个关键问题仍然存在:RLVR 真的带来了全新的推理能力吗?如果有,模型到底从 RLVR 训练中学到了什么?
为了严谨地回答这个问题,来自清华大学和上海交通大学的团队对此进行了深入的研究。

论文地址:https://arxiv.org/pdf/2504.13837
他们采用了简单的 pass@k指标,即只要k次采样中任意一次正确,问题就算解决。
核心思想是:如果我们为基础模型投入大量采样(超大k值),它的表现能否匹敌 RLVR 训练的模型?
通过给予模型大量尝试机会,能够评估基础模型和 RL 训练模型的推理能力边界。
这为检验 RLVR 训练是否能带来根本性的超越能力提供了关键且严谨的测试,即是否让模型能解决基础模型无法解决的问题。
结果,研究团队发现了一些可能颠覆传统认知的意外结果:
1. 在超大k值下,RLVR 训练模型的表现不如基础模型
虽然小k值下 RL 训练模型通常优于基础模型,但当k值变大时,基础模型在所有测试中都表现更好。令人惊讶的是,在足够大的k值下,基础模型的 pass@k分数甚至超过 RL 训练模型。这表明,未经 RL 训练的基础模型通过多样化采样,就能生成原本以为只有 RL 模型才能解决的正确答案。
2. RLVR 提升采样效率,但缩小推理能力范围
RLVR 训练模型生成的推理路径在基础模型的输出分布中已有相当的概率密度,表明这些推理模式和 CoT 对基础模型而言并非完全陌生或不可实现。RLVR 训练提升了采样效率,但同时降低了模型的探索能力,导致在大k值下可解决问题的覆盖范围变小(见图 1 右)。这挑战了 RLVR 能激发推理能力的普遍看法。相反,RLVR 训练模型的推理能力边界可能受限于基础模型的能力。RLVR 对 LLM 推理能力的影响如图 1 左所示。
3. 不同 RLVR算法表现相似,且远未达到最优
尽管不同 RL 算法(如 PPO、GRPO、Reinforce++)在性能上略有差异,但并无本质区别。这表明,当前主要通过提升采样效率的 RL 方法仍远未达到最优。
4. RLVR 与蒸馏有根本区别
RL 提升的是采样效率,而蒸馏能真正为模型引入新知识。因此,蒸馏模型通常通过学习蒸馏数据,展现出超越基础模型的推理能力范围,而 RLVR 训练模型的能力始终受限于基础模型。
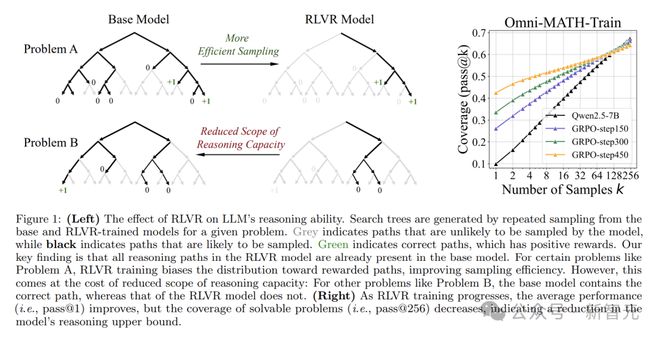
图1:(左)灰色表示模型不太可能采样的路径,黑色表示大概率采样的路径,绿色表示正确的路径(带有正向奖励)。(右)随着 RLVR 训练的进行,模型的平均性能(即 pass@1)有所提升,但可解决问题的覆盖率(即 pass@256)下降,表明模型推理能力的上限在降低
大佬纷纷入局讨论
大模型的「推理能力」究竟来自于哪里?概率机器真的能「涌现」推理能力吗?
强化学习,特别是可验证奖励的强化学习(RLVR)是否真正从基础模型中「引导」或「发掘」出推理能力?
关于模型中「涌现」出推理能力这个话题还得说回 DeepSeek-R1 开源他们的论文而引发那波热潮。
虽然 OpenAI-o1 是第一个发布的推理模型,但是他们「犹抱琵琶半遮面」的遮掩态度,让 DeepSeek 摘了推理模型的桃子。
在 DeepSeek-R1 的训练过程中,第一步就是通过基于 GRPO 的纯强化学习,训练出了 DeepSeek-R1-Zero,后续的训练过程都涉及到强化学习。
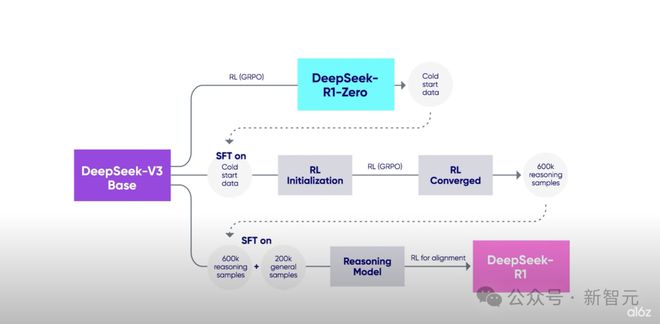
低成本的训练方式得到媲美千万资金的训练结果,这让基于强化学习的训练范式与 Scaling Law 正面相撞。
这个论文发布后,大佬们纷纷表示对这个话题有话要说。
Nathan Lambert 是一名电气工程与计算机科学博士,毕业于加利福尼亚大学伯克利分校,他率先转发了这篇论文,并表示
「也许关于强化学习是否激励了推理能力并不是一个直觉,而是一组有依据的新成果」。

本文作者 Yang Yue 也表示实验结果表明,RLVR 除此之外并没有做太多其他的事情。

如果基础模型无法解决问题,经过强化学习后的模型依然无法解决。
这似乎说明强化学习并不是万能的,有它的局限性。
也有网友表示,RL 本质是改变了概率分布,增加了原本不太常见的,很可能是正确答案轨迹的概率。
也就是说,能力依然来自于基础模型,RL 只是让正确答案更好的「涌现」出来。

当然,从另外一方面 Nathan Lambert 也表示,这些结果都是来自类似 R1-Zero 的训练风格,即仅仅通过了单纯的强化学习。
在 R1 的训练过程中,还有很多「热身」的过程,比如对冷启动数据后的 SFT,这些在强化学习训练开始前的「热身」过程可以给模型带来更强大的能力。

这从另一个方面说明,强化学习依然有效,只不过 RL 和蒸馏有本质的区别。
正如上述论文中所描述,强化学习提升了模型涌现「正确」的概率,而蒸馏则是为模型引入了全新的能力。
论文的作者 Yang Yue 也表示「热身」是一个不错的提升性能的方式。
以蒸馏为例,一些开源的基础模型,比如 Qwen 或者 Llama,通过蒸馏后,可以从教师模型引入基础模型之外的新推理模式。
Autodesk 首席 AI 研究科学家 Mehdi Ataei 同样表示,以他的经验来看,如果没有一个很好的基础模型,RL 根本无法工作。
大佬的讨论很精彩,其实也和几个月前 DeepSeek-R1 爆火后,经过大佬们讨论后的结论一样,「厉害的不是 DeepSeek-R1,而是 DeepSeek-V3」。
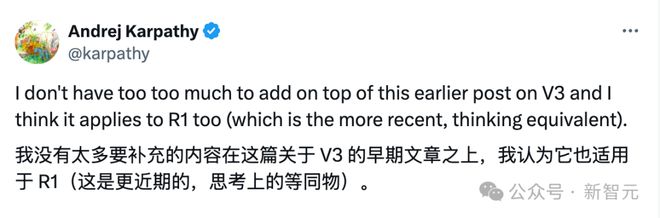
找到 Karpathy 在 V3 发布时的态度就能看出来,结合这篇论文,决定模型推理能力上限的大概率就是基础模型本身。
正如这篇论文的结论,RLVR 缩小了模型的探索范围,倾向于选择已知的高回报路径,而不是发现新的推理策略。
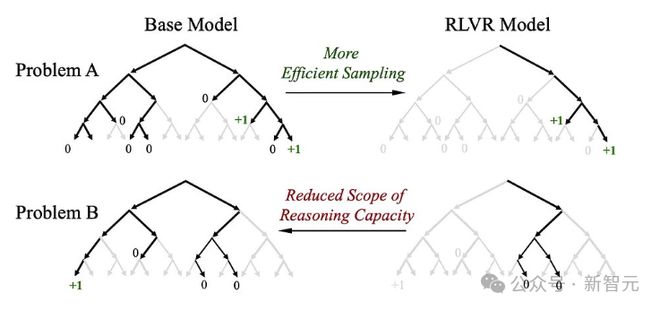
关键的是,所有来自 RL 训练模型的正确解其实早就已经存在于基础模型的分布中。
RLVR 只是提高了采样效率,而不是「推理能力」,但同时无意中也缩小了解空间。
所以,似乎 Scaling Law 并没有失效,一个足够好的基础模型,它的解空间包含正确答案的概率依然要高于那些不够好的模型。
只不过,可能需要多给大模型一些机会。
实验发现惊人
研究人员在数学、编程、视觉推理等领域展开了大量实验,涵盖了不同模型(像 Qwen-2.5 系列、LLaMA-3.1-8B)和多种 RL 算法。
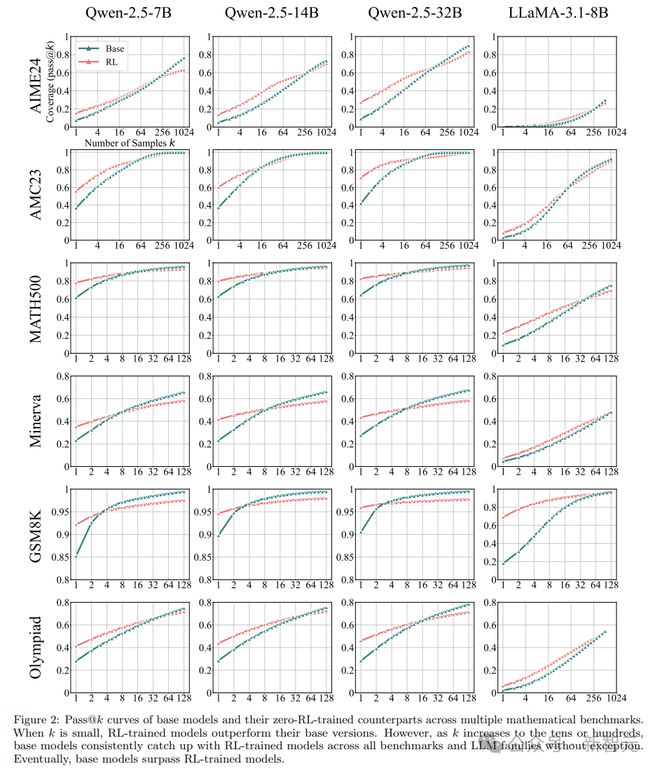
研究人员在多个数学基准测试中比较了基础模型和 RLVR 训练后的模型。
结果发现,当k值较小时(比如k=1),经过 RL 训练的模型确实表现更优,说明 RLVR 能让模型在单次尝试时更有可能得出正确答案。
但随着k值不断增大,情况发生了反转,基础模型逐渐赶上并超过了经过 RL 训练的模型。
就拿 Minerva 基准测试来说,用 32B 大小的模型时,当k=128,基础模型的表现比 RL 训练的模型高出近9%。
在 AIME24 这种极具挑战性的测试中,一开始,基于 Qwen-2.5-7B-Base 训练的 RL 模型 Oat-Zero-7B 表现很不错,比基础模型高出近 30%,可最后还是被基础模型超越了。
在此过程中,基础模型展现出强大的潜力,通过大量采样,能找到有效的推理路径。
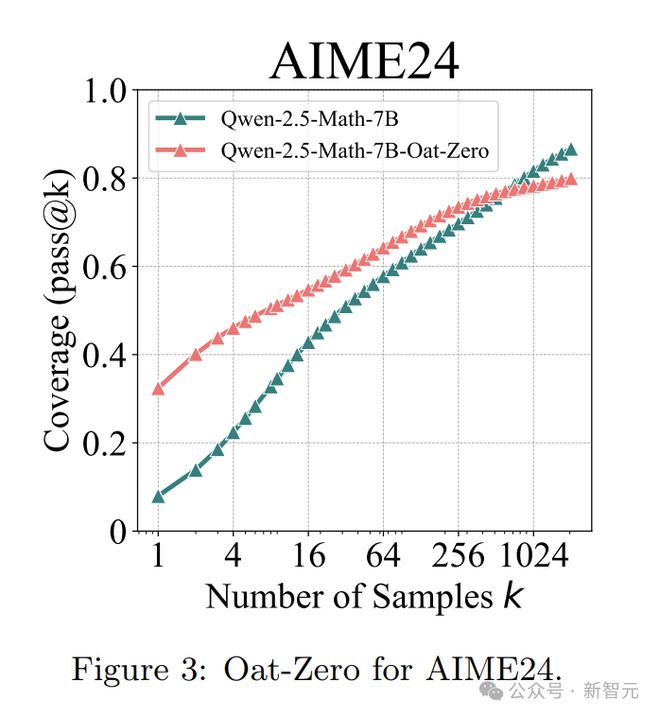
研究人员手动检查了最难问题的思维链(CoT),发现就算是最难的问题上,无论是原始模型还是 RL 模型,大多是通过有效的推理路径得出正确答案的,而不是运气。
为了避免模型作弊,也就是通过错误的推理过程偶然得出正确答案,研究人员还专门过滤掉了容易被猜中的问题,再次验证后发现,基础模型依旧能凭借有效的推理路径解决难题。
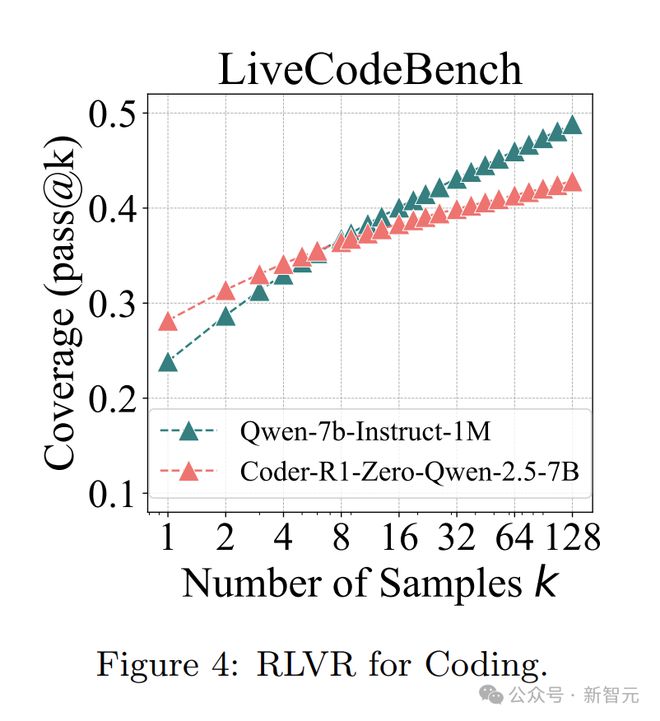
代码生成实验也呈现出类似的趋势。
研究人员选用了开源的 Code-R1 模型及其经过 RLVR 训练的版本 CodeR1-Zero-Qwen2.5-7B,在 LiveCodeBench v5、HumanEval+ 和 MBPP+ 这些基准测试中评估。
当k值较小时,RLVR 训练的模型单样本性能更好,但随着k值增大,基础模型可解决问题的覆盖范围更广。
例如,在 LiveCodeBench 上,原始模型 pass@1 得分是 23.8%,RLVR 训练的模型为 28.1%,可当采样 128 次时,原始模型能解决约 50% 的编程问题,而 RLVR 模型只能解决 42.8%。
视觉推理实验中,研究人员选择视觉背景下的数学推理任务,用 EasyR1 框架训练 Qwen-2.5-VL-7B,并在经过滤的 MathVista-TestMini 和 MathVision-TestMini 等基准测试中评估。
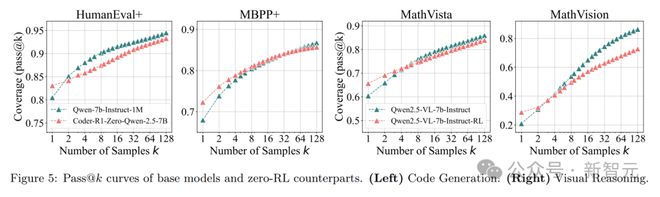
基础模型在可解决问题的覆盖范围上更具优势,RLVR 并没有让模型获得超越基础模型的推理能力。
基础模型已经包含推理模式
实验表明,基础模型能解决的问题范围竟然比经过 RLVR 训练的模型更大。
RL 训练模型解决的问题几乎是基础模型可解决问题的一个子集。在编程任务中也观察到类似趋势。
这引出了一个问题:RL 训练模型生成的所有推理路径,是不是早已存在于基础模型的输出分布中?
困惑度分析
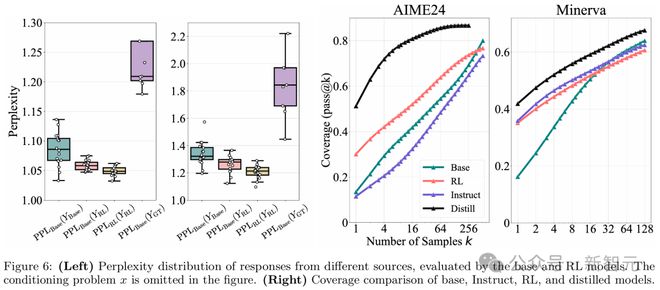
为了回答这个问题,研究人员使用了困惑度(Perplexity)指标。
困惑度反映了模型在给定问题x下预测某个回答Y的难易程度。困惑度越低,说明模型越可能生成这个回答。
他们从 AIME24 中随机抽取两个问题,用 Qwen-7B-Base 和 SimpleRL-Qwen-7B-Base 生成 16 个回答(分别记为 Ybase 和 YRL),并让 OpenAI-o1 生成 8 个回答(记为 YGT)。
结果显示(图 6 左),RL 训练模型的回答困惑度分布与基础模型生成回答的低困惑度部分高度重合,这说明 RL 训练模型的回答很可能是基础模型本身就能生成的。
由此得出以下结论:
-
RLVR 没有带来新的推理能力:通过 pass@k(k较大时)和困惑度分布分析,RL 模型的推理能力完全在基础模型的范围内,RL 模型利用的推理路径早已存在于基础模型中。
-
RLVR 提升了采样效率:尽管 RL 模型的推理路径存在于基础模型中,但 RL 训练提升了 pass@1 的表现。
-
RLVR 缩小了推理边界:RLVR 的效率提升以覆盖范围为代价,pass@k在k较大时低于基础模型。
蒸馏拓展了推理边界
除了直接进行 RL 训练,另一种提升小型基础模型推理能力的有效方法是从强大的推理模型(如 DeepSeek-R1)进行蒸馏。
这类似于后训练中的指令微调,将基础模型转化为指令模型。
但训练数据不是短指令-回答对,而是 DeepSeek-R1 生成的长思维链(CoT)轨迹。
研究团队以 DeepSeek-R1-Distill-Qwen-7B 为例,比较了它与基础模型 Qwen-2.5-Math-7B、RL 训练模型 Qwen-2.5-Math-7B-Oat-Zero 以及指令微调模型 Qwen-2.5-Math-7B-Instruct 的表现。
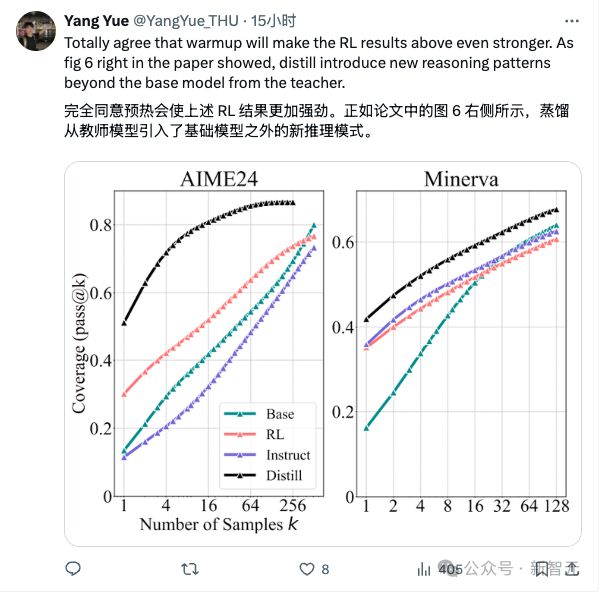
结果显示(图 6 右),蒸馏模型的 pass@k曲线始终显著高于基础模型,表明与 RL 不同,蒸馏通过学习更强教师模型的推理模式,突破了基础模型的推理边界。
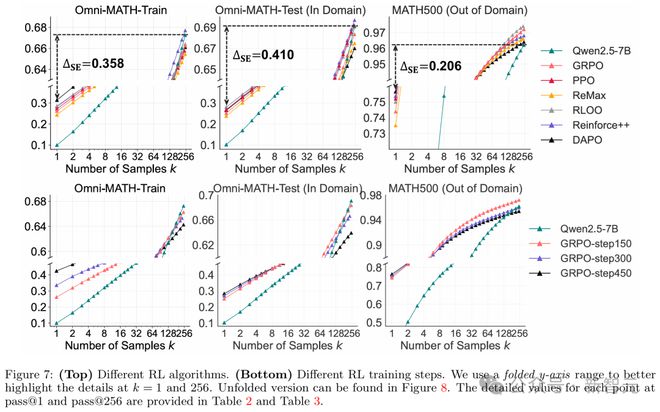
不同 RL 算法的效果
RL 的主要作用是提升采样效率,而非扩展推理能力。
为了量化这一点,研究团队提出了采样效率差距(∆SE),定义为 RL 训练模型的 pass@1 与基础模型的 pass@k(k=256)的差值,∆SE 越低越好。
结果显示(图 7 上),不同 RL 算法在 pass@1 和 pass@256 上的表现略有差异,但无根本性区别。
研究团队研究了训练步数对模型渐进性能的影响。结果显示(图 7 下),随着 RL 训练的进行,训练集上的 pass@1 稳步提升,但观察表明,延长训练可能收益有限。
作者介绍
乐洋

清华大学自动化系的三年级博士生,导师是黄高教授。
于 2022 年获得计算机科学学士学位,在本科期间还学习了电气工程。此前,在 Sea AI Lab 新加坡实习了一年多,在颜水成教授的指导下工作。还曾在字节跳动 Seed 实习。
参考资料:
https://x.com/natolambert/status/1914351774699512270
https://arxiv.org/abs/2504.13837






