
衡宇发自凹非寺
量子位 | 公众号 QbitAI
全球 AI 大模型智能涌现,现在正在进入“多模态时间”。
一方面,全球业内各式各样的技术进展,都围绕多模态如火如荼展开。
另一方面,AI 应用和落地的需求中,多模态也是最重要的能力。没有多模态技术,何谈应用和落地?
实际上,多模态的先锋共识和趋势,把代表性玩家的进展连点成线,也能看出来……
看看行业公认的多模态卷王,阶跃星辰——
刚刚过去的一个月,陆续上新的 3 款模型,全是多模态,有图生视频开源模型,有多模态推理模型,还有图像编辑开源模型。
模态丰富,上新频繁,性能出色。
之所以把阶跃的这些发布连点成线解读,也是因为阶跃从一开始的强落地和强应用属性。
目前,阶跃已发布的模型里,七成都是多模态。鉴于多模态是 Agent 的必备要素,今年阶跃化身「落地型玩家」的态势愈发明显:发力智能终端 Agent。

过去一个月,卷王卷出了些啥?
据量子位整理回顾,过去一个月,阶跃星辰接连上新了 3 款模型:
- Step1X-Edit:图像编辑模型
- Step-R1-V-Mini:多模态推理模型
- Step-Video-TI2V:图生视频模型
它们覆盖了当前多模态模型的几大刚需方向,并且其中 Step1X-Edit 和 Step-Video-TI2V 已面向开发者开源。
怎么说呢,这很阶跃,也很符合技术流和行业玩家们对“多模态时间”的追逐趋势。
而这三款模型的具体情况,咱们掰开了来看——
Step1X-Edit 图像编辑模型,开源 SOTA
第一个,来看最新鲜的图像编辑模型,阶跃于昨日刚刚发布并开源。
名为 Step1X-Edit,总参数量 19B。
值得注意的是,此处的“19B”,由 7B MLLM 和 12B DiT 构成——没错,Step1X-Edit 首次在开源体系中实现 MLLM(多模态大模型)与 DiT 的解耦式架构。
其中,7B 参数 MLLM 负责语义解析,12B 参数 DiT 负责图像生成。
这一结构打破了传统 pipeline 模型中“理解”和“生成”各自为营的问题,使模型在执行复杂编辑指令时具备更高的准确性与控制力。
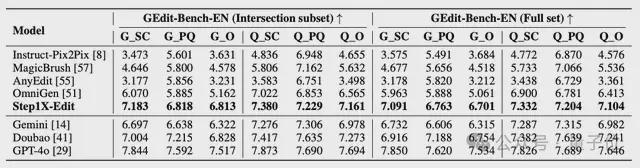
什么概念?直接让 Step1X-Edit 的性能达到开源 SOTA:
在最新发布的图像编辑基准 GEdit-Bench 中,Step1X-Edit 在语义一致性、图像质量与综合得分三项指标上全面领先现有开源模型,比肩 GPT-4o 与 Gemini 2.0 Flash 等闭源模型。
而阶跃对 Step1X-Edit 的能力定位很具体。
首先是能“改图”。
其次,也是这个模型更出色的一点,是不仅能“改图”,更能“听得懂、改得准、保得住”。
Be like:

但是,官方口径如此,上手实测真的有如此言出法随的效果吗?
我们设置了三道关卡,并分别在阶跃 AI 官网、阶跃 App 和抱抱脸上进行了测试。
第一关,考验其语义解析能力是否精准。
具体而言,我们想要考察的是 Step1X-Edit 是否能够灵活执行 prompt,是否需要复杂的 prompt 才能实现任务(毕竟一般玩家和咱一样,都不是专业 prompt 大师)。
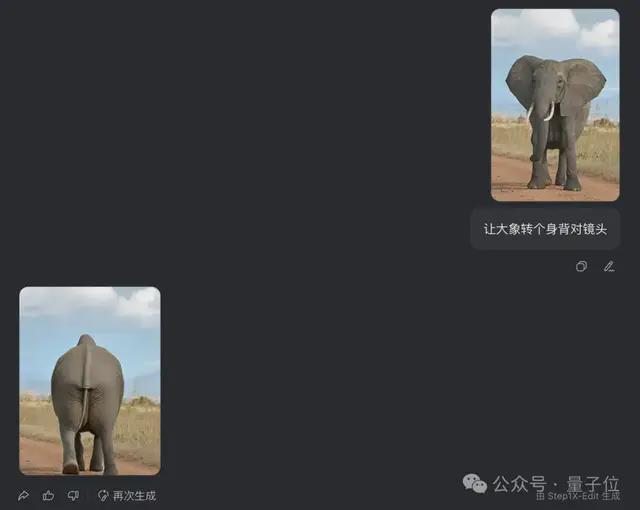
丢过去一张大象正面照和一句非常简单的提示词:让大象转个身背对镜头。
不到 30 秒,大象就已经转过身去不看镜头了(doge)。
而且大象掉头转身的同时,背景丝毫没变,也看不出啥p图痕迹。
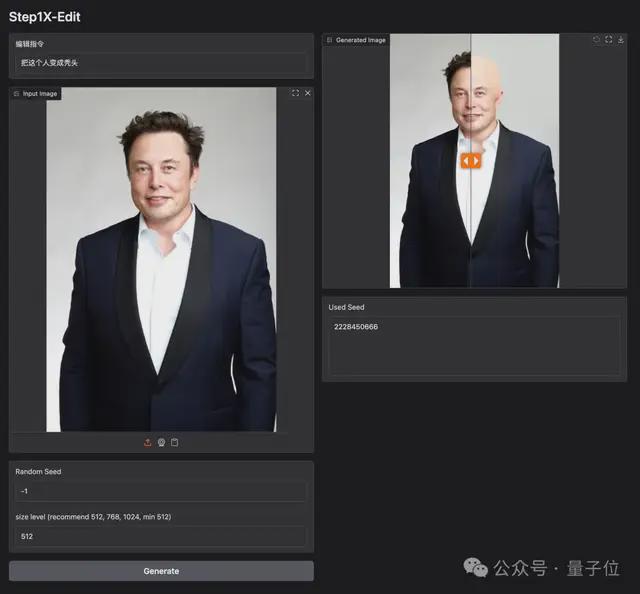
第二关,考验在面对人物 or 动物时,能否做到身份一致性保持。
此处随用随请的马斯克,并“施咒”让他变成秃头。
Step1X-Edit 不负众望——
第三关,考验 Step1X-Edit是否具备高精度区域级控制。
喂给它一张相册里的照片,prompt 为“把珠海的海水p蓝一点”,然后就得到如下效果图:
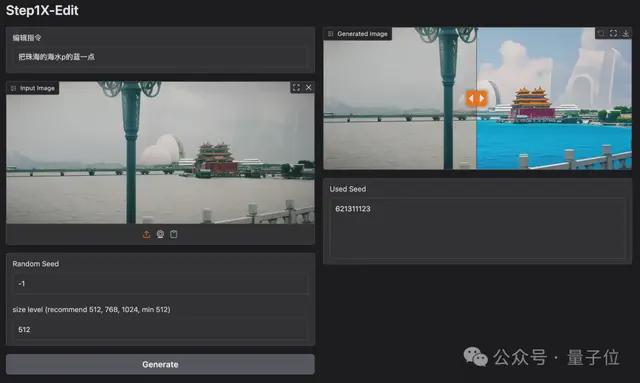
它展示了自己精准的控制能力,定向分辨出“海”在图片中占据哪些部分,也如提示词要求的那样让海水变蓝。
最后的附加题,感受一下 Step1X-Edit 修改图片上文字的能力。
输入一张有两行字的图片,并指定让其中的“GREEN”修改为“阶跃 AI”字样。
水灵灵的图片就出现了:

有意思的是,生成过程中,除了进度条实时更新,界面还会出现一些玩法推荐,用来启发用户开发更多姿势。

Step-R1-V-Mini 多模态推理模型,轻量亦强大
多模态推理被视为 AI 模型理解这个世界的下一步重要落子,通过整合文本、图像、音频、视频等多种模态数据,实现跨模态信息的深度融合与逻辑分析。
4 月,阶跃发布了Step-R1-V-Mini。它已上线阶跃 AI 网页端,并在阶跃星辰开放平台提供 API 接口。
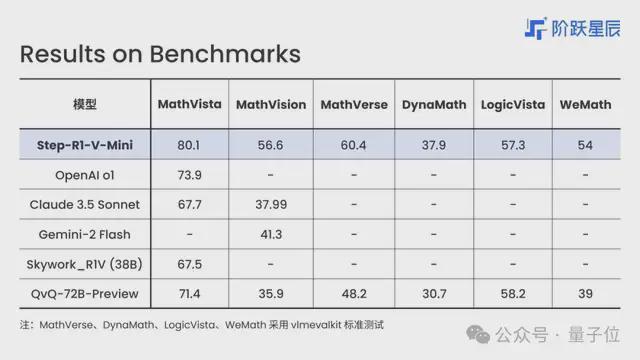
这款模型支持图文输入、文字输出,有良好的指令遵循和通用能力,能够高精度感知图像并完成复杂推理任务。在视觉推理榜单 MathVision 中,Step-R1-V-Mini 位列国内第一。
可以看到,视觉推理、数学逻辑和代码等方面,它的表现都十分优异。
整个模型的训练过程中,阶跃团队做了两项重要尝试:
一个是多模态联合强化学习。
Step-R1-V-Mini 的训练路径基于 PPO 强化学习策略,在图像空间引入 verifiable reward 来解决图片空间推理链路复杂、容易产生混淆的相关和因果推理错误的问题。
相较 DPO 等,这一训练方法在处理图像空间的复杂链路时更具泛化性与鲁棒性。
另一个是充分利用多模态合成数据。
目前的常用训练过程相对难以获得多模态数据的反馈信号。针对于此,阶跃团队设计了大量基于环境反馈的多模态数据合成链路,合成了可规模化训练的多模态推理数据,并通过基于 PPO 的强化学习训练同步提升模型文本和视觉的推理能力。
如此一来,有效避免了训练跷跷板问题。
我们尝试丢给它一张在北京道路上拍摄的图片,但没有告诉它地点,直接问:“这是哪儿?”

它头头是道,从建筑特征、道路与路灯、环境线索、交通标识等多个方面来分析。
推理分析过程中还注意到了拍摄者本人都没留意的路灯上悬挂的红灯笼……
最后得出了正确的结论:综上,照片拍摄于北京长安街西行方向,背景为 CBD 核心区,标志性建筑为中国尊。
甚至不只是定位到城市,还精确定位到了拍摄地点是哪条街,就说牛不牛吧。

除了看图识别地点,Step-R1-V-Mini 别的推理能力,我们也浅试了一番。
献上一份香喷喷、辣滋滋的川香藤椒鸡,询问烹饪方法。
它一上来就根据大量的辣椒和花椒,把菜系缩小到了“川菜或湘菜”之中。而后一眼就看出了主要食材是鸡肉,最后综合判断,锁定了整个流程的主要步骤:煮鸡→冷却→切块→拌入调料。

讲真,它说出这道菜“看起来是经典的青花椒鸡(或藤椒鸡)”,还在最后说“冰镇后更开胃”的时候,是有点惊到我的。
更惊喜的是阶跃在官方公众号里表示,Step-R1-V-Mini 是多模态推理方向的「阶段性成果」。
听起来,还有大招在后面~
Step-Video-TI2V 开源图生视频模型,动漫效果尤佳
从去年 Sora 出世至今,图生视频一直都很卷,是模型玩家们的兵家必争之地。不过主要玩家还是集中在闭源赛道上。
阶跃倒是一开始就抬脚迈入了开源领域,并且再接再厉——月前上新的 Step-Video-TI2V,正是一款开源图生视频模型。
它训练脱胎于 30B 参数的 Step-Video-T2V,经由“引入图像条件,提高一致性”和“引入运动幅度控制,赋予用户更高自由度”两大关键优化,目前支持生成 102 帧、5 秒、540P 分辨率的视频。
此外,它还具备运动幅度可控和镜头运动可控两大核心特点。
看看下图从其生成视频中截取的动图展示。从左至右,画面中的运动幅度依次为 2 / 5 / 10 / 20(数值越大,动态性越强)。

感兴趣的朋友们可以到阶跃 AI 网页端或者阶跃 AI app 体验
21 款模型,打开终端 Agent 想象力
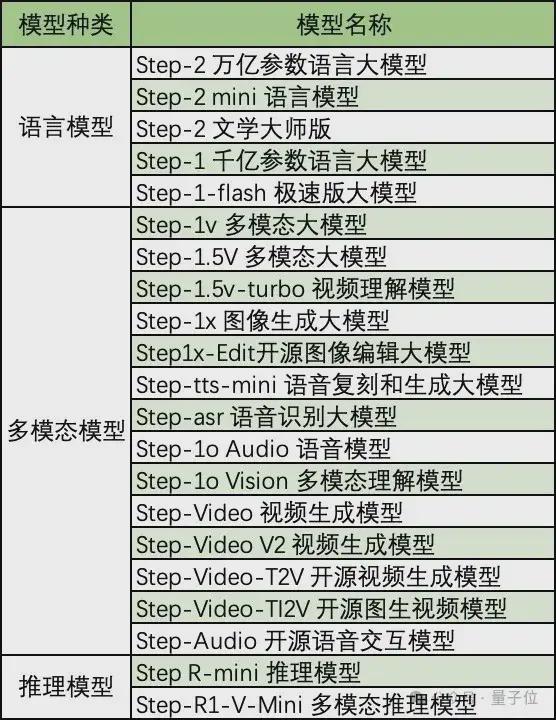
算上过去一个月里上新的上述 3 款模型,截至目前,阶跃 Step 系列基座模型共推出 21 款。
这些模型大致可分为语言模型、多模态模型、推理模型三大类,其中多模态模型占比超七成。
量子位整理了这 21 款模型,用一张表格呈现:
而完成这 21 款模型研发与上架对外,阶跃只用了 2 年时间,就成为了国内基座模型种类最全的公司之一,无论是数量还是模型性能都稳居第一梯队。
2025 年之前,阶跃各种模型“年纪虽轻”,但已经广受市场欢迎,陆续被大量一线品牌和 AI 开发者们接入。
今年 2 月,量子位曾对阶跃星辰的外部合作伙伴们进行过梳理。消费品牌,如茶饮品牌茶百道、咖啡品牌瑞幸;AI 应用如狸谱、胃之书、林间聊愈室、歌词爆改机等,都接入应用了阶跃多模态模型的能力。
2025 年开始,阶跃模型又开始在智能终端 Agent 上合作与发力。
并且是多点开花那种,覆盖车 、手机、具身智能、IoT 四大关键场景。自今年 2 月在生态日上官宣以来,时隔 2 个月已经有一系列业务进展,合作图谱已经初步形成——
智能汽车场景上,阶跃与吉利汽车集团、千里科技紧密合作,共同推动“AI+ 车”的深度融合。
今年的上海 2025 车展,吉利就展示了基于阶跃端到端语音模型打造的智能座舱。通过方言对话、拟人化交互、音乐生成等功能,展示了阶跃多模态技术的成熟度。
手机终端场景上,阶跃的多模态模型已经在 OPPO 多款年度旗舰机型中落地应用。
「一键问屏」和「一键全能搜」两大创新性 AI 手机功能均由阶跃提供多模态技术支持。用户使用小布助手 App,可以通过多模态视觉跟 AI 交互;唤醒小布助手后,可以根据用户指令自动完成一系列的搜索操作任务,跨 App 执行命令毫无障碍。
具身智能场景上,阶跃先与稚晖君创业的智元机器人牵手,后又与旷视三剑客创业的原力灵机合作。
据官方介绍,阶跃与前者的重点落在“围绕世界模型技术探索、具身智能领域数据合作、新零售等应用场景开展深度合作”,而同后者的合作重点则是“围绕多模态大模型技术、智能终端 Agent 与具身智能场景展开深度协同,共同推动 AGI 在物理世界的应用落地”。
IoT 终端场景上,阶跃通过生态开放的方式,与包括 TCL 在内的一系列 IoT 平台和设备厂商紧密协作,推动设备间的智能化升级和体验的无缝连接。

以上四大场景中,阶跃均采取了与行业第一梯队选手深度合作的方式,实现从技术研发到场景落地的全价值链闭环。
不可否认,与单一技术授权相比,这种深度绑定模式更具竞争壁垒,也更适合一个模型起家的创业公司在垂直领域扎根和深挖,进一步打开终端 Agent 的想象力。
AI 大模型已经进入多模态时间
如果说 1 个月内上新 3 款模型,彰显的是阶跃一贯的作风:在多模态领域的投入大、迭代快。
那么拉通细数阶跃所有模型矩阵——已形成覆盖语言、语音、图像、视频、推理五大方向的完整能力版图,纵观阶跃与各个垂直领域头部玩家的牵手——实现终端 Agent 在速度与广度的战略升维,从单点突破到系统作战的转变,一切都能看出这家公司的「布局广」和「落地先」。
值得回味的是,阶跃是国内大模型创业公司中,最后一名浮出水面的。但展现的是谋定而后动,以终为始的战略思考和执行。
作为大模型领域的超级新星,阶跃是大模型赛道不容忽视的重要组成力量,杀出了其多模态矩阵全面的口碑,技术也始终保持领先。
它仅用两年时间便后来居上,以「多模态技术奇袭+终端 Agent 破局」的双轮驱动模式,以「数据-场景-模型」的三角闭环,在智能终端领域,重构交互范式与产业价值链。
并且在已经锚定的领域,即智能终端相关商业世界,重构终端交互范式与产业价值链。
技术纵深决定天花板高度、开源开放加速生态裂变、场景深耕打通商业化命脉。
这恰恰印证了当前最大的行业趋势:
AI 大模型正在进入多模态时间,AI 从“文字处理器”进化为“世界解读者”。
从 OpenAI 的 GPT-4o 到谷歌的 Gemini 1.5 Pro,再到最新的阶跃 Step1X-Edit,全球科技巨头正以多模态能力突破为核心展开新一轮竞赛。
在这个新旧范式交替的临界点,拒绝多模态进化的 AI 模型与应用,或将就此成为数字达尔文主义淘汰赛中的失落者。






