
允中发自凹非寺
量子位 | 公众号 QbitAI
抛弃替代损失函数,仅需优化原始目标, 强化学习新范式来了:
消除 critic 和 reference 模型,避免 KL 散度约束;解决优势函数和梯度估计两个偏差。
来自阿里-高德地图的团队提出了一种相当简单的强化学习训练新方法:组策略梯度优化 GPG(Group Policy Gradient)。
GPG 开创性地从底层重构强化学习训练框架,仅需优化原始目标,解决已有方法偏差,提高训练效率。革新强化学习训练流程,推动智能体性能突破。
在实验中,GPG 在单模态和多模态两类任务中表现遥遥领先,其极简架构与高性能表现,有望成为下一代基础模型训练的关键方法。

以下是更多 GPG 有关细节。
一、背景介绍
近年来,以 OpenAI 和 DeepSeek R1 为代表的 LLMs 模型表现亮眼,深究成功背后,是强化微调技术(RFT)联合现有强化学习方法(如 PPO、GPPO)在激励模型构建严谨的推理链上发挥了关键作用。
但在面对高昂的训练成本与性能平衡,主流方法 PPO 也陷入巨大瓶颈,与此同时,其他研究团队也在尝试使用ReMax、GRPO等简化训练流程,并在性能上取得了很大的突破,但他们都依然存在一些问题。
研究团队认为,当前针对 RL 算法的优化都在围绕替代损失函数展开,但两个核心问题始终悬而未决:
1. 能否绕过替代策略,直接优化原始目标函数?
2. 如何最大限度简化学习策略的设计?
由此,团队提出了 GPG,其核心创新包括:
- 直接目标优化:摒弃传统替代损失函数设计,直接优化原始强化学习目标,突破算法效率瓶颈。
- 极简训练架构:无需评论模型和参考模型支持,摆脱分布约束,为模型扩展性提供更大空间。
- 精准梯度估计技术(AGE):首次揭示现有方法的奖励偏差问题,提出轻量化且高精度的梯度估计方案,显著提升策略稳定性。
- 单模态多模态任务 SOTA 验证:在数学推理、视觉理解、跨模态推理等任务中,GPG 性能全面超越现有方法,验证其通用性与鲁棒性。
二、组策略梯度 GPG 方法
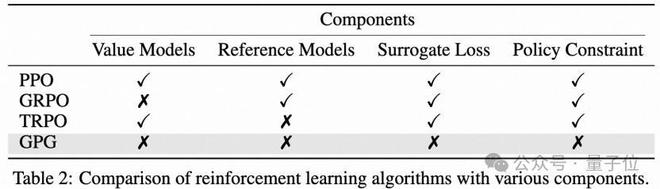
1)方法对比
各种强化学习方法的比较,作者以最简单的形式解释:

下面是 GPG 方法和已有 RL 方法各个模块的对比:
2)GPG 方法
GPG 旨在解决在没有价值模型的情况下,策略梯度估计中的高方差问题。通过利用 group-level 的奖励,GPG 稳定了训练过程并增强了强化学习训练的鲁棒性。
具体而言,GPG 利用每个 Group 内的平均奖励来归一化奖励,从而有效降低方差。这个方法可以移除传统的价值模型,从而简化了训练过程并提高了计算效率。 GPG 的名称反映了作者方法核心机制,即利用 group-level 的平均奖励来稳定和优化学习。
GPG 的核心优化目标定义为:
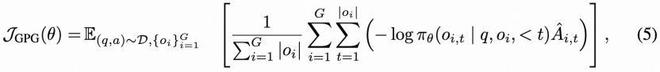
作者提出的 GPG 方法通过组内优势函数计算梯度校正机制实现了高效稳定的策略优化。在优势函数设计上,采用组内奖励均值归一化方法

3)现有 RL 方法中的两个 bias
优势函数中的 bias
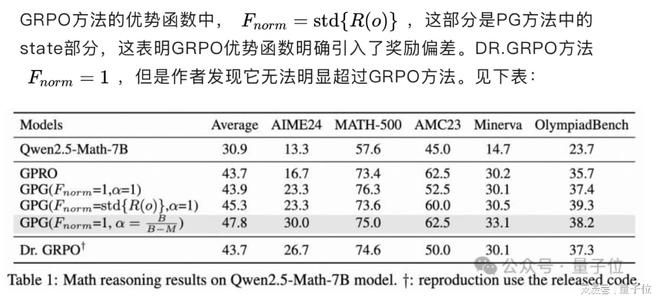
组内样本全对全错时,引入梯度估计的 bias
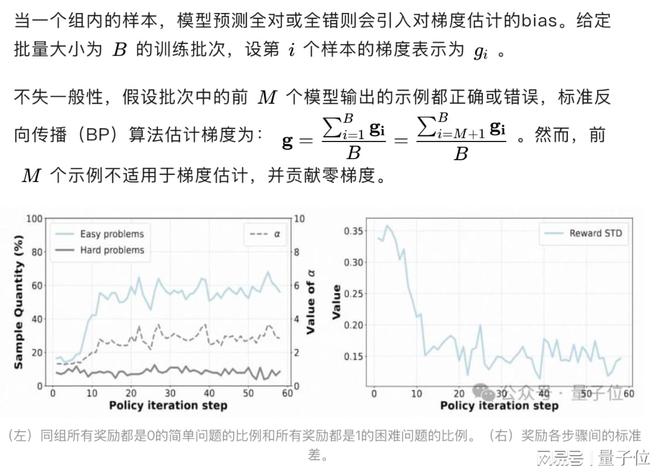
针对组内全对/全错样本的梯度估计 bias 问题,GPG 创新性地引入动态梯度校正因子。

实验表明该机制可使模型准确率从 43.9% 提升至 47.8%,显著改善训练稳定性。
三、实验
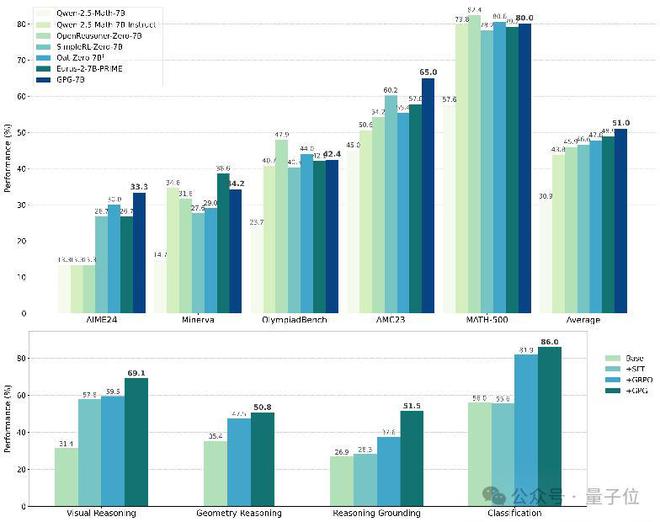
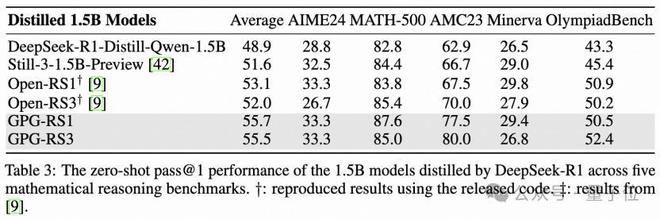
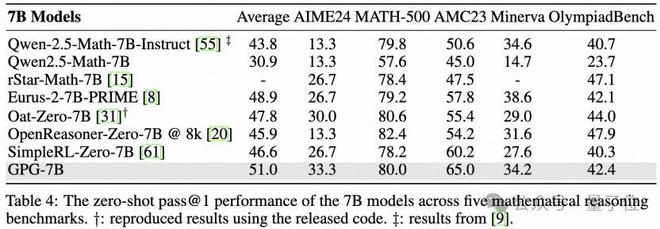
1)在单模态数据集上的结果
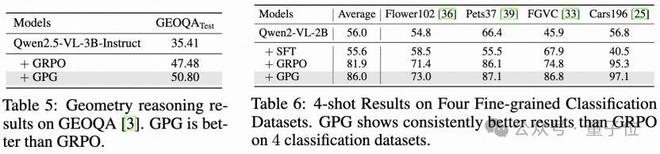
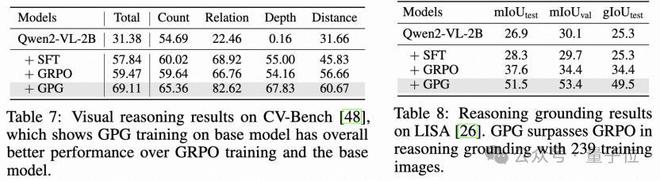
2)在多模态数据集上的结果
四、结论
在本文中,作者介绍了 GPG,它有效地解决了强化微调方法(如 PPO 和 GRPO)中现有的关键挑战。
通过将基于组内的决策动态直接纳入标准的 PG 方法,GPG 简化了训练过程,并显著减少了计算开销,而不削弱模型效果。这一突破为训练能够进行复杂推理的先进 LLM 提供了更高效的框架,从而为更具资源效率和可扩展性的人工智能系统做出了贡献。
此外,团队将本文代码全面开源,希望促进技术透明化发展,也鼓励更多人参与到该项工作中来。






