
MedKGEval 团队投稿
量子位 | 公众号 QbitAI
医疗大模型知识覆盖度首次被精准量化!
在医疗领域,大语言模型(LLM)的潜力令人振奋,但其知识储备是否足够可靠?腾讯优图实验室天衍研究中心的最新研究给出了答案。
他们提出的MedKGEval 框架,首次通过医疗知识图谱(KG)的多层级评估,系统揭示了 GPT-4o 等主流模型的医学知识覆盖度。
该研究已被 WWW 2025 会议 Web4Good Track 录用为口头报告(oral)。目前,WWW 2025 正在悉尼举行,会议时间从 4 月 28 日持续至 5 月 2 日。

背景
大语言模型(LLM)在医疗领域的快速发展凸显了其知识存储与处理的潜力,但其临床部署前的可靠性验证亟需更系统化的评估框架。
当前主流的 Prompt-CBLUE、Medbench 和 MedJourney 等评估体系虽通过医学问答基准测试 LLM 的任务执行能力,却存在三个明显的局限:
1)其长尾数据分布导致罕见病症覆盖不足,评测结果存在偏差;
2)任务导向的设计聚焦疾病预测、用药咨询等单一场景,难以量化模型内在医学知识储量;
3)传统问答形式局限于表面对错判断,无法捕捉医学概念间的复杂拓扑关联。
为解决这些问题,本文提出基于医疗知识图谱(KG)的多层级评估框架 MedKGEval。
医疗 KG 通过结构化存储复杂实体关系网络,为评估提供天然基准。框架创新性地设计三级评估体系:实体层评估医学概念理解,关系层检验医学关联区分能力,子图层验证结构化推理水平。
通过真伪判断和多选题形式,同时实现任务导向(task-oriented)的粗粒度性能评估与知识导向(knowledge-oriented)的细粒度三重覆盖度测量(实体/关系/知识三元组)。
医疗知识覆盖度评估框架 MedKGEval
在 MedKGEval 中研究团队设计了多层级的任务体系,其中包含 3 个层级的 9 项核心任务,通过真伪判断(TFQ)与多选题(MCQ)任务形式,实现任务导向与知识导向的双重评测。
具体评估流程框架见下图。
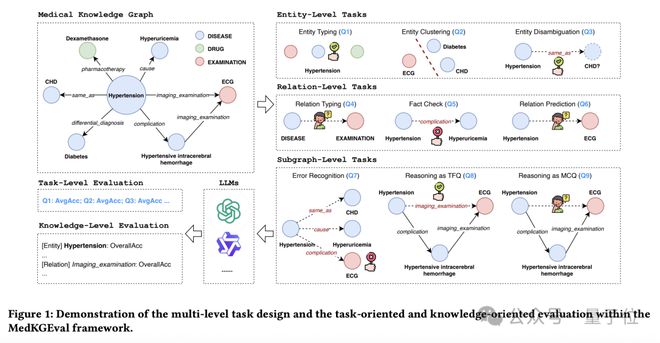
任务架构设计
基于医疗知识图谱的实体、关系、三元组结构,构建三级评估体系:
实体层面(3 项任务):验证医学概念理解
- 实体类型标注(ET):通过多选题识别“糖尿病”等实体的分类标签(如疾病/症状)
- 实体聚类(EC):从 5 个实体中辨识类型异常项(如混入症状类别的药物实体)
- 实体消歧(ED):判断两个实体是否等价,比如“阿司匹林”与“乙酰水杨酸”是否为等价实体
关系层面(3 项任务):检验医学关联认知
- 关系类型标注(RT):选择“并发症”关系可连接的实体类型对(如疾病→疾病)
- 事实核验(FC):判断三元组的真伪,比如“布洛芬-治疗-偏头痛”
- 关系预测(RP):补全实体之间缺失的关系,比如“冠状动脉硬化→(?)→心肌梗死”
子图层面(3 项任务):评估结构化推理
- 错误识别(ER):从 5 个三元组中检测异常项(如错误药物禁忌关系)
- 子图推理1(R1):基于多跳关系推理,比如基于“高血压→并发症→脑出血→影像检查→CT”路径,推断“高血压→影像检查→CT”是否成立
- 子图推理2(R2):在相同推理链中,从候选关系中选择正确关联

随着利用的 KG 信息增多,任务难度也在逐渐升高,这样阶梯式、多层级的评估更有利用全面了解 LLMs 的性能。
任务导向和知识导向的评估机制
在每项任务中均配备评估核心实体/关系映射(如上图 core E and R),实现细粒度知识覆盖分析:
任务导向评估:计算准确率指标
知识导向评估:
- 实体覆盖率:实体正确率均值(CovAvg-E)、引入节点中心度加权(CovDeg-E)
- 关系覆盖率:关系正确率均值(CovAvg-R)、按关系出现频次加权(CovDeg-R)
- 三元组覆盖率 Cov-T:反映知识单元整体掌握度
实验及评估结果
MedKGEval 选用中文医疗领域主流知识图谱 CPubMedKG 和 CMeKG 作为基准,经下采样构建实验数据集。
评估模型涵盖三大类:1)开源通用模型;2)医疗垂类模型;3)闭源模型。
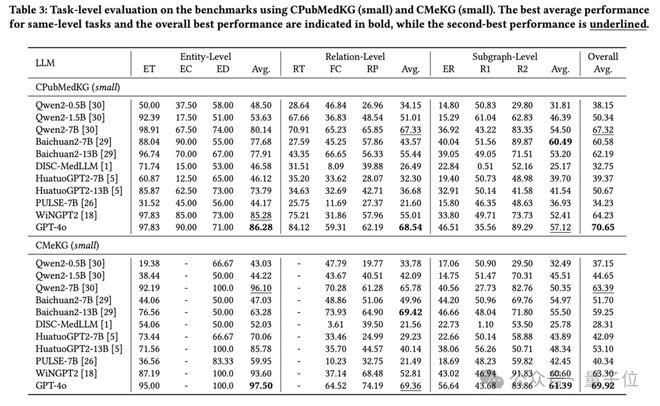
下表展示了 11 个 LLM 的任务导向评估结果,可以看到:GPT-4o 以 70.65% 平均准确率领先;同架构 LLM 参数量翻倍带来3-5% 准确率提升;大多 LLM 在实体层面任务上表现优于关系和子图层面;通用模型性能超越医疗垂类模型(归因分析:垂类模型微调数据侧重具体任务(如用药咨询、医患对话摘要),导致医学知识广度受限)。
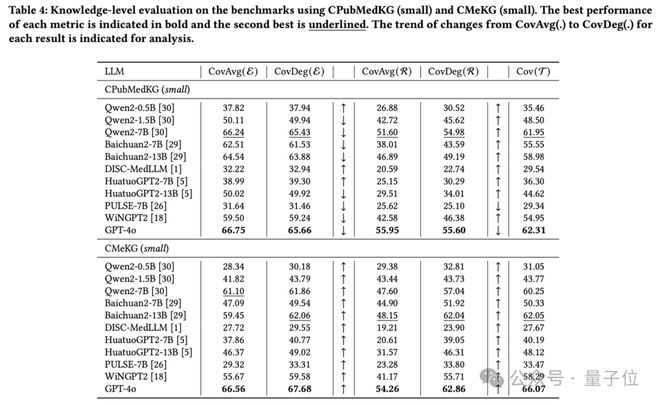
下表展示了 11 个 LLM 的知识导向评估结果,可以看到:GPT-4o 在 CPubMedKG (small)上覆盖了 65.66% 的实体、55.60% 的关系、62.31% 的三元组;更大的参数量通常会带来更高的知识覆盖度;CovAvg 和 CovDeg 的对比体现出了 LLM 对高关联度实体(如糖尿病)和高频关系(如鉴别诊断)的偏好性:CovAvg < CovDeg 说明 LLM 在高关联度实体的上表现更好、反之说明 LLM 在低关联度实体上表现更好。
接下来,研究团队使用 MedKGEval 评估框架对四个示例 LLM 在关联度最高的 15 个实体和最高频的 15 个关系上的知识覆盖情况进行分析。
以常用临床实体“超声”为例,可以看到 GPT-4o 以 94.16% 正确率领先,Qwen2-7B(88.83%)、WiNGPT2(85.41%)次之。
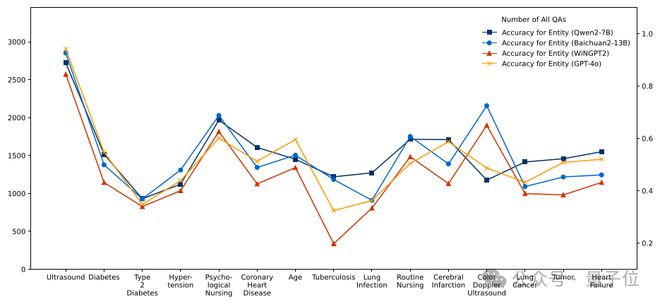
在医学关系覆盖度上,4 个 LLM 也表现出了类似的特点。
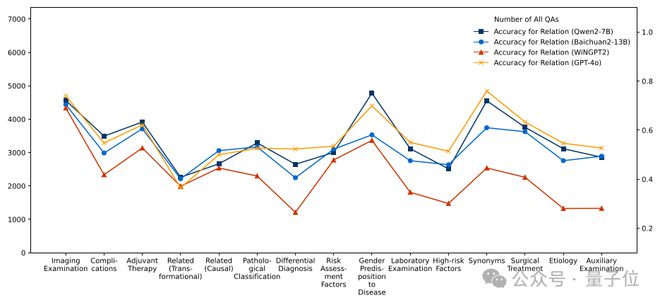
分析结果表明,MedKGEval 能有效定位 LLM 在特定医学知识领域的认知缺陷。
这些发现对模型优化具有重要指导价值:如上图所示,WiNGPT 在“肺结核”实体相关问答中表现欠佳、Baichuan2-13B 在“相关(转换)”关系中存在明显短板。
因此,在下轮微调中建议针对性补充结核病诊疗指南和病理转化机制相关数据,通过基于知识缺陷诊断的定向增强策略,可显著提升医疗领域 LLM 的整体性能。
总结
本文提出的 MedKGEval 框架通过医疗 KG 视角,构建了评估 LLM 医学知识覆盖度的多维度体系。
该框架在实体、关系和子图三个层级展开评估,系统揭示了当前大语言模型在医学知识存储与推理能力方面的优势与局限。
研究团队提出的的任务导向与知识导向双轨评估机制,不仅能够精准定位模型的知识薄弱环节,更为提升医疗领域 LLM 的可靠性和临床应用价值提供了量化依据。






