
新智元报道
编辑:KingHZ 英智
年仅 19 岁少年,自称破解了谷歌最快的语言模型 Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比 GPT 快 10 倍的速度、媲美人类程序员的代码能力,正在掀起一场 NLP 范式大洗牌。
没想到扩散模型以一种另类的方式,火起来了!
来自德国的 19 岁的少年,Georg von Manstein 声称自己「破解」了谷歌文本扩散模型的原理。
「19 岁」「创业」「破解谷歌模型」……
乍看之下,简直像极了「少年天才挑战腐朽巨头」的逆袭剧本,数以万计的网友被他的推文吸引。

再加上扩散文本生成模型的动态演示,好像谷歌 Gemini Diffusion 的原理真被他破解了。
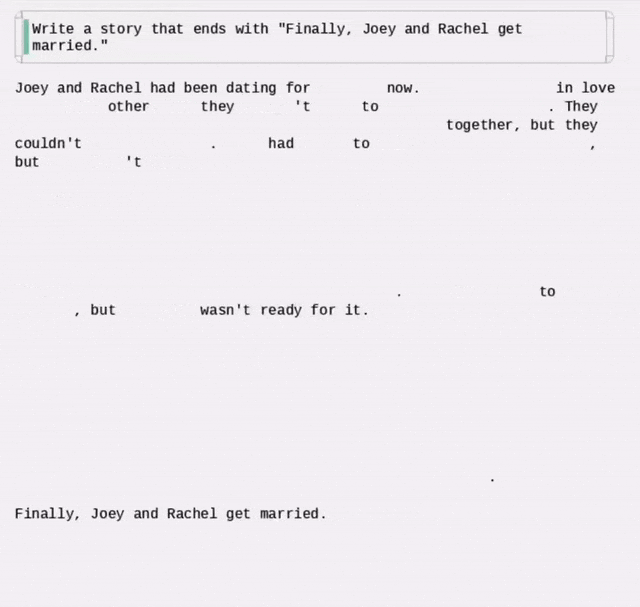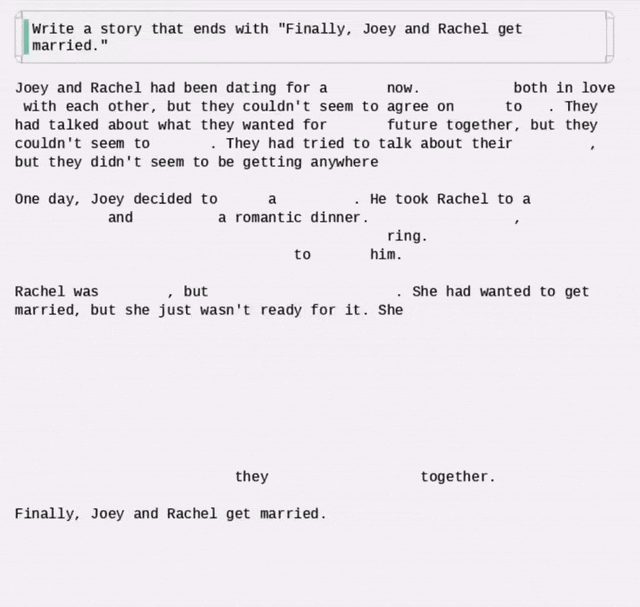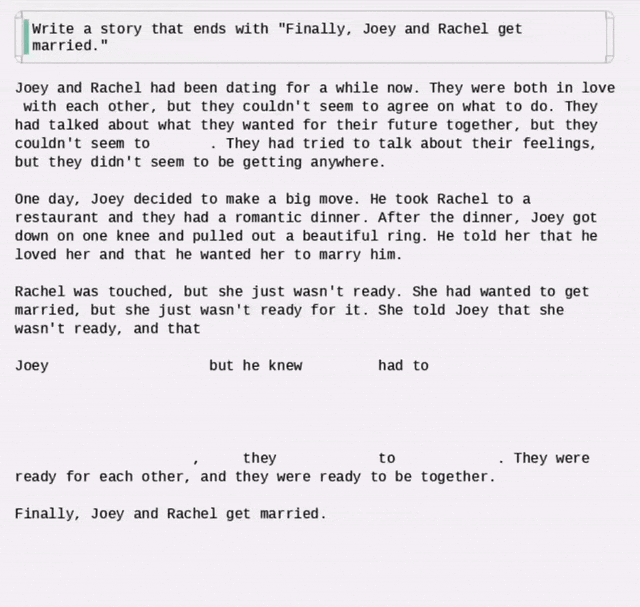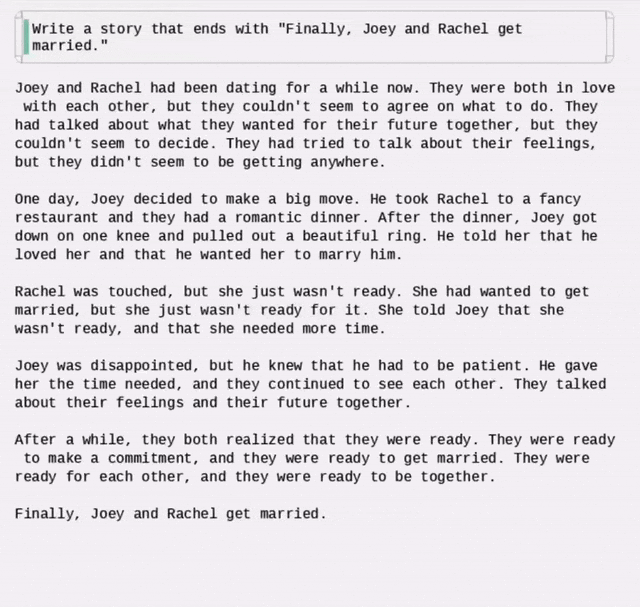
但很快就有网友发现,他用的动图,其实是来自国内的研究(Dream 7B),而后面放出来的几篇论文也并没有做任何解释……
不管这位小哥是不是在「搞抽象」,但谷歌这次提出的 Gemini Diffusion 却是一个实打实的干货。
更重要的是,Gemini Diffusion 给扩散模型「再就业」树立了榜样。
Gemini Diffusion
每秒 1479token
遗憾的是 Gemini Diffusion 被 Veo 3 等消息所掩盖了。
但 Gemini Diffusion 是谷歌更大的野心:重塑语言生成,利用扩散技术,实现更快、更自由、更可控的文本创作体验。
Gemini Diffusion 最大特点就是速度飞快:比谷歌目前最快的非扩散模型还要快,采样速度每秒 1479 个 token,启动时间只要 0.84 秒。

响应速度之快,以至于谷歌在演示中需刻意放慢速度,才能让观众看清文本生成的内容。

除了生成速度快,在生成文本质量上,尤其是文本连贯性和错误纠正方面,Gemini Diffusion 也优于传统的自回归模型。

Gemini Diffusion 三大优点:快速响应、文本更连贯、迭代优化
在实时响应或大批量文本生成场景下,Gemini Diffusion 具有明显优势。
在任务准确度上,二者各有千秋,取决于任务类型。
Gemini Diffusion,在生成效率和局部准确度方面表现优异,但在通用智能和知识覆盖方面尚未全面超越当前最强的自回归模型。
不止是快,代码和数学也很强
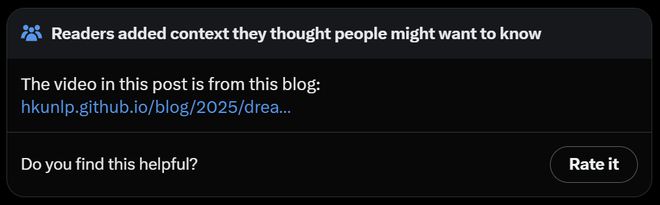
在外部基准上,Gemini Diffusion 的性能可与更大的模型相媲美,同时速度也更快。
DeepMind 将其与自家的 Gemini 2.0 Flash-Lite 模型进行了对比,在多个代码基准上几乎旗鼓相当。
总体来看,Gemini Diffusion 在垂直领域(编程、数学)的准确性已经可与一流模型相比,甚至略有胜出,但在通用知识和推理方面仍有明显差距。
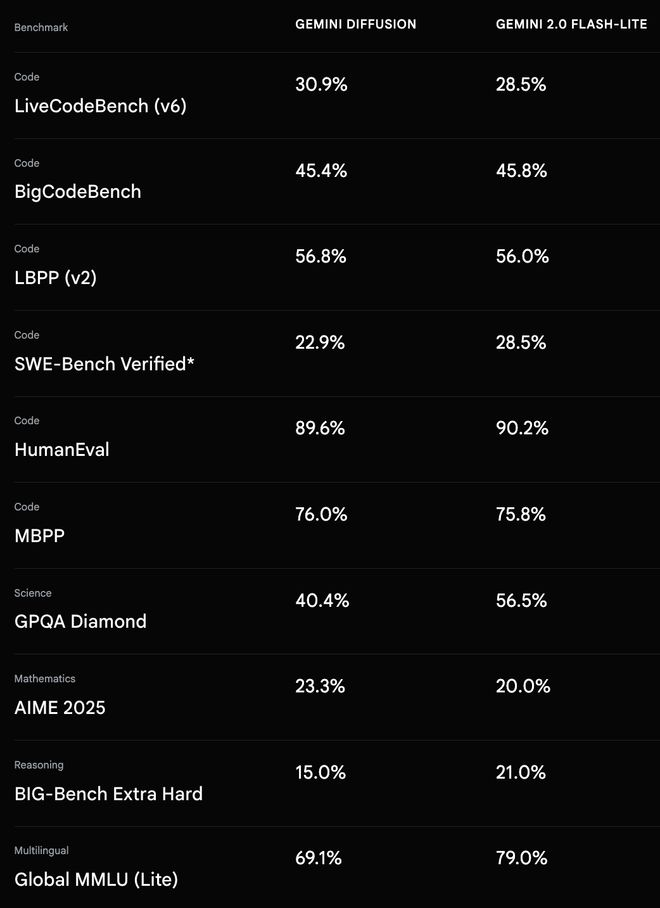
在外部基准测试中,Gemini Diffusion 不仅快,在代码和数学推理任务上也表现优异:
-
HumanEval 代码测试:一次性通过率达 89.6%,与 Gemini Flash-Lite 持平;
-
AIME 2025 数学竞赛测试:准确率 23.3%,略高于 Flash-Lite 的 20.0%;
-
LiveCodeBench 实时编程:得分 30.9%,领先 Flash-Lite 的 28.5%。
尤其在长文本、逻辑强、结构复杂的任务中,其全局生成策略展现出对传统架构的替代潜力。
不过,在通用知识类任务上,其表现仍不如当前最强的自回归模型:
-
MMLU 多任务问答:Gemini Diffusion 得分为 69.1%,仍低于 GPT-4 的 86.4%。
-
科学推理 GPQA Diamond:准确率 40.4%,显著落后于 Flash-Lite 的 56.5%。
目前,Gemini Diffusion 还是实验性演示版本,要注册候补名单才有机会体验。
实测:几秒完成聊天应用
著名的 Web 开发工程师 Simon Willison,得到了 Gemini Diffusion 的试用机会。
他表示谷歌所言非虚:
哇,他们说它速度快可不是开玩笑的。

Simon Willison:英国程序员,Web 框架 Django 的共同创作者
在下列视频中,他给 Gemini Diffusion 提示是「Build a simulated chat app」,它以每秒 857 个 token 的速度作出响应,并在几秒钟内生成了一个包含 HTML 和 JavaScript 的交互式页面。
在此之前,唯一一个达到商业级别的扩散模型是今年二月 Inception Labs 推出的 Mercury 模型。
Diffusion 模型再就业
在 AI 生图领域,Diffusion 模型节节败退。
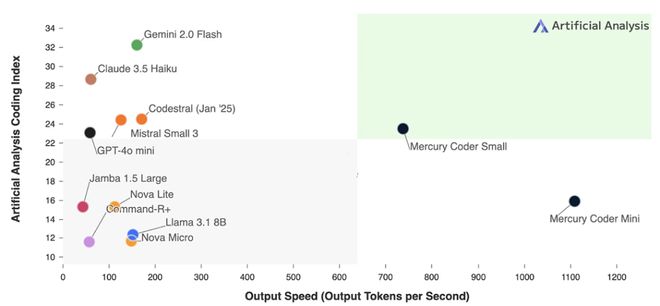
在今年二月,Inception Labs 推出了世界上首个扩散语言模型,在速度和成本上比当前一代 LLM 快多达 10 倍、便宜多达 10 倍。
在输出速度和人工分析编程指数上,可谓「遥遥领先」!
在接受采访时,斯坦福大学教授、Inception Labs 联合创始人Stefano Ermon表示:
过去很多尝试将扩散模型用于文本生成都以失败告终。Mercury 之所以成功,是因为我们在训练和推理算法方面做出了专有的创新。图像可以模糊地「看个大概」再逐步优化,但语言却必须严守语法规则,这使得迭代优化的过程更加复杂。

Stefano Ermon
而 IBM 研究员 Benjamin Hoover 指出,Mercury 模型证明了扩散模型正在弥合差距,也指出了趋势的转变:
两三年之内,大多数人将会转向使用扩散模型。这已经是必然了。当我看到 Inception Labs 的模型时,我意识到,这种转变会比预想的更快发生。

Benjamin Hoover
而在「AI 四巨头」中,谷歌是第一家推出扩散语言生成模型的巨头。
这对于扩散研究领域而言,无疑是个振奋人心的信息。
谷歌 DeepMind 主任科学家(Principal Scientist)Jack Rae 表示,Gemini Diffusion 的发布感觉像是一个里程碑。

Gemini Diffusion 的成功探索向业界证明,非自回归的扩散架构在大语言模型上切实可行。
扩散模型威逼 GPT,而下一代 AI 正在浮现。
扩散模型再战自回归
传统的自回归语言模型是一次生成一个词或一个 token,从左到右逐字预测下一个 token,按照顺序逐步生成文本(见下图左)。
由于这种生成方式是逐步进行的,因此速度较慢,也可能限制了生成结果的质量和连贯性。
与传统的自回归大语言模型不同,Gemini Diffusion 采用了扩散模型的架构:它从随机噪声出发,逐步细化出完整的文本段落(见下图右)。
这种过程类似于图像扩散模型在图像生成中的应用——从杂乱噪声开始,通过多次迭代逐渐生成清晰有意义的输出。

在文本领域,这意味着 Gemini Diffusion 可以一次生成整个词块,并在生成过程中多轮调整纠错,逐步逼近最终结果。
它在初始阶段给出一段粗糙的文本草稿,然后通过迭代不断改进内容的准确性和一致性,直到得到高质量的输出。
这种架构上的根本差异带来了多方面影响:
首先,并行生成整个文本块使其速度大幅提升(无需逐词等待)。
其次,全局视角的生成方式有助于长文本的整体连贯性,因为模型能同时考虑文本各部分的关系,而非局限于局部上下文。
最后,迭代精炼允许模型在生成过程中自我检查并修正错误,使输出更一致可靠。
扩散大语言模型(Diffusion Large Language Model,dLLM)将为 LLM 带来一系列全新的能力,包括:
1. 更强的智能代理能力:dLLM 的速度和效率极高,适用于需要大量规划和长文本生成的智能体应用。
2. 更高级的推理能力:dLLM 内置的纠错机制修复幻觉内容,优化答案,同时保持在几秒钟内完成思考。
3. 更可控的生成过程:dLLM 支持编辑生成内容,并且可以按任意顺序生成 token。
4. 边缘设备上的应用:得益于其高效性,dLLM 非常适合资源受限的场景,例如边缘设备。
扩散模型:不止生图
在 Y Combinator 新闻论坛,网友 nvtop 对 Gemini Diffusion 提供了一番解释:扩散语言模型与谷歌的 BERT 模型颇有渊源,反而与图像生成领域中的扩散模型没有太大关系。
这或许能理解为什么谷歌的这次转向。

论文链接:https://arxiv.org/abs/1810.04805
回忆一下 BERT 是如何训练的:
(1)输入一整句完整的句子(例如:「the cat sat on the mat」)
(2)将其中 15% 的 token 替换为[MASK](例如:「the cat [MASK] on [MASK] mat」)
(3)使用 Transformer 模型并行地预测这些被遮蔽的位置,仅需一步推理(inference)
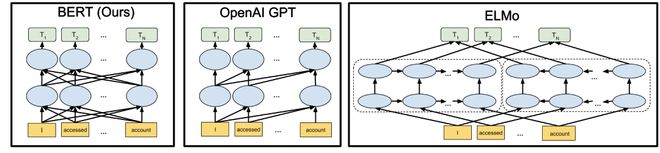
扩散语言模型的做法则是在这个思路上更进一步。
BERT 只能恢复约 15% 的被遮蔽 token(可视为「噪声」),但完全可以训练模型来恢复 30%、50%、90%,甚至 100% 被遮蔽的文本。
一旦训练完成,就可以实现从零开始生成文本:
-
一开始输入全部为[MASK]的序列,模型输出的内容可能是胡言乱语。
-
然后随机选出其中 10% 的 token,把它们标记为「已生成」。
-
在下一次推理中,将剩下 90% 的位置继续设为[MASK],保留前面 10%。
-
继续这样迭代,在每一轮中都「定住」一部分新的 token。
-
大约迭代 10 次之后,就能生成完整的文本序列。
这正是扩散语言模型的核心理念。
当然,在实际应用中还有很多优化策略。
如果需要生成很长的文本(例如超过 200 个 token),可以将其切分为多个块(chunk),先并行生成第一个块,再逐块向后生成。
这种方法被称为Block Diffusion,是一种半自回归式生成方式。

论文链接:https://arxiv.org/abs/2503.09573
还可以选择性地将哪些 token 在某一轮中被视为「最终生成的」,以及这部分的比例:
-
在早期阶段,模型还处于噪声状态,可以一次保留更多 token。
-
在后期接近完成时,则可以多迭代几轮,每轮只保留少量新 token,以提升质量。
总体来看,扩散语言模型虽然也是迭代式的,但所需步骤远少于自回归模型。而且用户可以自由选择迭代轮数,实现速度与质量之间的权衡。
极端情况下,甚至可以让扩散模型仅预测最左边一个被遮蔽的 token,这样它就退化为一个传统的因果语言模型了。
文本生成范式转向
当响应延迟不再显著,人们可以更自然地将 AI 融入工作流中,实时协作或即时创意迭代将成为可能。
Gemini Diffusion 的成功探索向业界证明,非自回归的扩散架构在大语言模型上切实可行。

可以预见未来会出现自回归+扩散融合的模型:利用扩散模型快速生成初稿,再用自回归模型微调润色,或者反过来通过自回归生成草稿、扩散模型高效优化。
这种多阶段、多模型协作的框架有望结合双方优势,提高生成质量和速度。
这些进展预示着扩散模型正崭露头角,可能打破过去多年自回归模型一统 NLP 天下的格局。
将高速扩散生成与深度推理相结合,可能是其下一步的研发重点之一。
参考资料:
https://fortune.com/2025/05/21/gemini-diffusion-google-io-sleeper-hit-blazing-speed-ai-model-wars/
https://blog.google/technology/google-deepmind/gemini-diffusion/






