白交发自凹非寺
量子位 | 公众号 QbitAI
上海交大、27 岁、最年轻博导,留给张林峰的标签不多了(Doge)。

最新引发关注的,是他实实在在的一个论文成果——
他们提出了一种新的数据集蒸馏方法,结果获得了 CVPR 2025 满分。
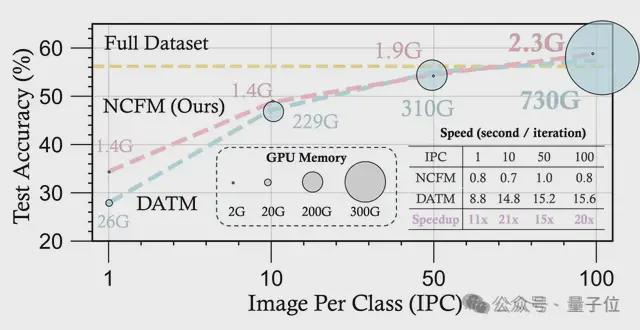
通过引入一个辅助的神经网络,只需一块 6 年前的 2080Ti,就能做大模型数据蒸馏。与前 SOTA 相比,新方法的显存占用只有1/300,并且速度提升了 20 倍。
不过对于这一结果,张林峰表示有点意外。但能肯定的是「数据蒸馏」这一范式会成为接下来模型压缩的趋势之一。
实际上模型压缩这个领域其实并不新。作为机器学习中的一个分支,它旨在减少模型的复杂度、存储空间或计算资源需求,同时尽可能保持其性能。像大家熟知的剪枝、量化、蒸馏都是模型压缩的传统方法。
随着大模型浪潮深入,「大力出奇迹」范式开始受到质疑,由 DeepSeek 为代表带起的「高效低成本」的趋势,让模型压缩再度受到业内关注,回到舞台中央。
而始终在这个领域深耕的张林峰,对于模型压缩怎么走?如何走?他有着自己的见解。量子位与张林峰展开聊了聊。
大模型压缩:加速底座模型
从张林峰团队最近几个研究开始看起。
首先说道说道被 CVPR 评为满分论文的 NFCM。它的核心是引入了一个新的分布差异度量 NCFD,并将数据集蒸馏问题转化为一个 minmax 优化问题。
通过交替优化合成数据以最小化 NCFD,以及优化采样网络以最大化 NCFD,NCFM 在提升合成数据质量的同时,不断增强分布差异度量的敏感性和有效性。
在多个基准数据集上,NCFM 都取得了显著的性能提升,并展现出可扩展性。在 CIFAR 数据集上,NCFM 只需 2GB 左右的 GPU 内存就能实现无损的数据集蒸馏,用 2080Ti 即可实现。并且,NCFM 在连续学习、神经架构搜索等下游任务上也展现了优异的性能。
这其实代表着张林峰团队所做的一个方向:通过数据的角度去加速模型。
当前 AI 模型需要基于海量数据进行训练,这显著增加了大型模型的训练成本。我们研究如何更高效地利用数据,更科学地清洗和合成数据,并利用合成数据进一步增强生成模型,从而实现数据高效的人工智能。
具体是什么意思?
张林峰解释道,一个模型的计算,抽象出来就是参数w和数据x去算矩阵乘法。按照之前的思路,就是对参数w进行压缩,但一旦参数改变就需要重新训练,避免它损失那么多信息。既然这个思路现在实现不了,那就尝试来压缩数据x。
当训练数据集都是精挑细选的高质量数据,在通过这些高质量数据去进行合成,训练成本就会可以降低,同时也不会出现过拟合的情况。
现阶段,他们有个目标就是通过数据压缩来提高训练的效率,他们内部有个指标,那就是训练节省的成本/挑选数据成本是>1 的,这也就证明这一技术思路是可行且有价值的。但目前还只能在一些阶段和场景中可行。
最近,他们发表在 ACL2025 的一篇文章已经在大模型微调训练阶段实现了这个目标,通过上下文学习大幅度提高了后训练数据筛选的速度和精度(http://arxiv.org/abs/2505.12212)。

未来有可能的话,参数压缩和数据压缩其实可以天然结合起来。
除了数据视角下的模型压缩,他们另一个方向在于:模型训练阶段删掉 token,让训练成本变低。或者在推理阶段删掉 token,让模型推理速度变快。
比如,他们发现在最近火热的扩散语言模型上,可以通过删除 token 实现最高 9 倍的加速而几乎没有性能损失(https://github.com/maomaocun/dLLM-cache)。在多模态大模型上,可以删除图像视频中 80% 甚至 90% 的 token,仍然能保持很高的精度……

现在他们已经将这一探索从语言模型延伸到了视觉生成板块。
他们提出了一个叫做 Toca,token 级别的特征缓存(Token-wise Caching)的方法。
这是首次从 token 级别实现了扩散模型在图像和视频生成上,无需训练就实现两倍以上的加速。这解决的是 Diffusion Transformer 计算成本高的难题。

之前的缓存方法忽略了不同的 token 对特征缓存表现出不同的敏感性,而对某些 token 的特征缓存可能导致生成质量整体上高达 10 倍的破坏。
他们的方法允许自适应地选择最适合进行缓存的 token,并进一步为不同类型和深度的神经网络层应用不同的缓存比率。
这个思路还可以针对不同任务做专门优化,比如在图像编辑任务上,只有被编辑的区域是需要关注和计算的,没有被编辑区域上的计算可以尽量的减少。基于这个思路,他们把 token 级别的特征缓存又用到了图像编辑任务上(https://eff-edit.github.io/)。
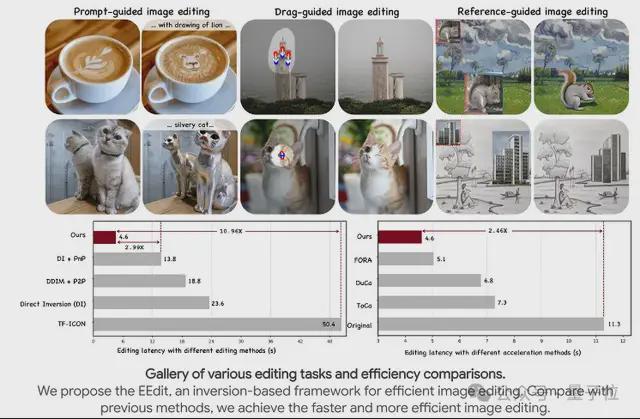
而最新的 TaylorSeer 正是这一思路的延续。他们希望 TaylorSeer 能够将特征缓存的范式从复用转移到预测,像预言家一样预言下一步的特征是什么。

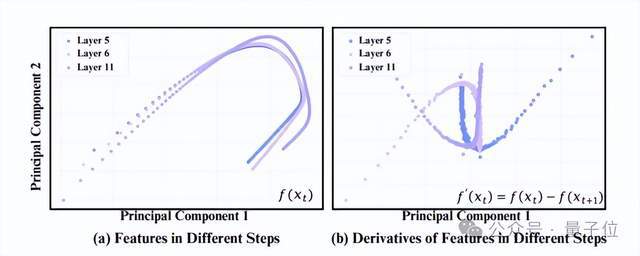
他们发现扩散模型在特征空间上随时间步的变化是非常稳定而连续的,这说明可以直接基于直接时间步的特征用泰勒展开预测出下一步的特征,而不需要真正的去计算。
从思路上讲,传统的扩散模型缓存方法是缓存上一步的特征,在下一步上进行“直接复用”;我们的方法是缓存上一步的特征,对下一步特征进行“预测”,其精度显然会超过直接复用的方式。
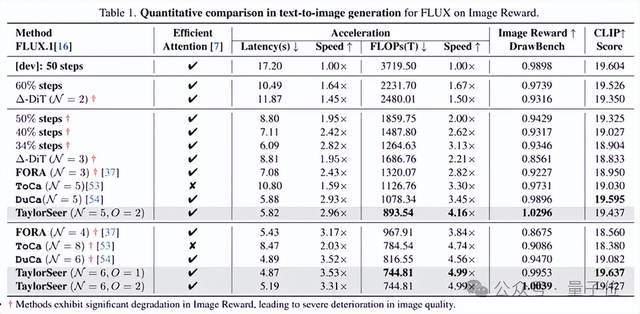
最终在 DiT、FLUX、Hunyuan Video、WAN、FramePacker、SDXL 等模型上都实现了接近 5 倍的加速效果,此外音频生成、图像超分辨率、图像编辑、甚至是具身智能等任务上也进行了成功的尝试。
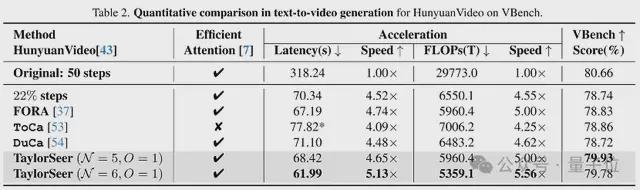
加速后的模型在使用八卡 GPU 推理时,已经可以让 HunyuanVideo 对视频的生成速度逼近于播放速度。
这一系列研究成果已经开源,并且逐渐在各种模型中部署。

https://github.com/Shenyi-Z/TaylorSeer
张林峰透露,他们现在的一个长期目标是以极低地成本即插即用地加速任意的开源视频生成模型,最终让视频生成模型的生成速度超过视频的播放速度。
这就意味着,我们在播放一个视频的时候,它在后台同时生成一个视频,感知层面上讲几乎是实时生成视频的。
从这几个研究中,其实能看到张林峰团队的几个方向,同时也代表着模型压缩的几个趋势,比如数据视角下的模型压缩;从语言模型延伸到多模态生成模型的加速。
但总归目的只有一个:降低大模型的部署成本,使其更好地应用于现实世界。
从本科大三就直至现在助理教授这一身份,张林峰始终在探索这一方向。他坦言从技术到自身心境都发生了很多变化。
从「模型压缩」到「大模型压缩」
最早是在 2018 年底,张林峰彼时没有考虑到那么多,只是觉得方向好玩,再者工业界也比较关注这一方向。
现在回想,他表示:
- 虽然做过很多调研,但也不可能预感到大模型时代的到来。
当时他大四一篇自蒸馏的文章,奠定了他之后方向的基础,也给整个学界和工业界一个思路,时至今日被引数超过了 1100+,并被同方向大神 MIT 副教授韩松(2023 年斯隆研究奖得主、深鉴科技联合创始人),写进了《TinyML and Efficient Deep Learning Computing》这门课程的 Lecture 9《Knowledge Distillation》。
这篇文章是《Be your own teacher: lmprove the performance of convolutional neuranetworks via self distillation》(《通过自蒸馏提高卷积神经网络的性能》),发表于 ICCV2019。
它提出了一种自蒸馏通用训练框架——使用模型的深层来蒸馏浅层。
该方法将目标 CNN 按深度和原始结构划分为几个浅层部分,在每个浅层部分后设置一个由瓶颈层和全连接层组成的分类器(仅在训练时使用,推理时可移除)。
训练时,所有浅层部分及其分类器作为学生模型,通过蒸馏从最深层部分(视为教师模型)获取知识。在显著提高 CNN 性能的同时,训练时间也更短。
这篇论文证明了知识蒸馏中的教师模型并非必需,而是自己同时扮演老师和学生,推动了无教师知识蒸馏领域的发展。
如今再来看知识蒸馏,他认为知识蒸馏的发展可以分为三个阶段。
第一个阶段是强的大模型来当老师,来训练弱的小模型(学生模型)。
第二个阶段就是自蒸馏,相当于是老师和学生其实是同一种模型,能力是差不多的,自己教自己然后让自己变得更为强大,这其实在目前垂直领域中智能体应用中很常见。
第三个阶段,现阶段整个科研社区比较关注的一个领域,就是从弱到强蒸馏——让一个小的弱模型当老师,然后让一个强的模型当学生,通过弱的模型去提升强的模型。这一方向十分具有前瞻性,因为如果一旦能实现,这就说明可以实现 AI 的进化,模型可以越来越强。

不过这样的想法,如果放在当时并不会受到太多关注。甚至模型压缩这个研究方向一度险遭停滞:是不是要转行了?!
2020 年时期,模型开始从「越来越小」的方向发展,从一开始的几十兆、几百兆到后来几兆、甚至压缩到几 KB 模型。模型压缩似乎没有什么余地,张林峰感到「没什么能做的」。
结果转机是在大模型出现,大家惊呼:哇塞,模型还能这么大哈?

张林峰透露,很多外行或者不懂 AI 的人问他,你看现在都讲大模型,结果你做模型压缩,是不是与时代背道而驰?
他表示,实际上模型越大,其实就越需要压缩。
我们现在每天都盼着,哪天再出来一个 10 万亿的,最好再出来一个百万亿的模型,那就更开心了。
虽然都是偏应用项目,与过去做模型压缩相比,张林峰一个明显的感知就是研究越来越 fancy 了。
本科毕业时他用自蒸馏给图像分类模型做加速,结果做出来的 Demo 给身边人看,结果他们都表示:so what?突然有一瞬间他觉得这个项目好像没有什么意思——因为只是给图像做了个分类。
而现在技术带来的改变是肉眼可见、即时可感知的。比如视频生成提速 5 倍,原本需要 50 秒生成的结果,现在只需 10 秒就可以搞定。
这些具象化的产出天然具备趣味属性——无论是生成图像、逻辑推理还是视觉理解,所带来的成就感也就非常直观。
不过还只是表象的变化,技术层面的区别还是不小。
主要体现在这几个方面:一个是目标转变,另一个则是技术复杂性的差异。
传统模型压缩以结构优化为核心,找到最佳的架构,允许牺牲已经学到的知识(如减少卷积层数、通道数),通过后续重新训练即可恢复性能。像剪枝、量化、蒸馏就是比较经典的模型压缩的方法。
而以千亿参数的大模型来讲,则需要需平衡结构效率与知识保留,压缩过程必须最小化知识损失。因为如果要重新将大模型跑起来是算力、数据、工程经验等多重考验。现实情况是每个做模型压缩的人并不具备真正让模型在压缩中丢掉的知识再学回来的这个能力。
相反现在数据视角下的模型压缩里很多工作,完全不需要训练,整个成本就会低很多:
大概就是租个 GPU 的费用就可以搞定。
从本质上讲,这种不需要训练的方法,是在利用模型本身具有的冗余性,然后将这种冗余性减少。
不过当高度精炼的模型出来,是不是不需要模型压缩了?!
面对这一问题时,张林峰表示:确实存在。
不过现在这个阶段,大家还是在朝着大模型这一方向走,特别像视频生成这个方向。总的来说,道阻且长。
希望不要以年龄来定义
像这样年纪轻轻就当上助理教授开始展露头角,张林峰只是一个代表。仅在他们学院就有很多年轻老师,甚至比他还要小。
张林峰谈到,年轻老师一上来肯定精力会多一点,对于学生的指导也会更多一点。很多热爱科研的同学,入门可能需要有个人能手把手去带,那年轻老师就非常适合这个位置,大家共同从零到一地去产出成果。
如果抛开年龄标签,张林峰坦言自己跟大多数做科研的人一样,希望别人用他们做过的科研成果来记住他们。
比如做知识蒸馏的、做模型压缩的、做数据视角下让模型变得更快的。
我就希望大家就记住我的是我做出过什么工作,而不只是我的名字。
张林峰团队也跟他一样,一整个主打年轻化风格,一拨是他自己的学生;另一拨就是研究助理,大部分是本科生。
对于进来的学生,张林峰表示只需满足两点要求。
一个是 Motivation,真正喜欢做科研的,觉得这个方向很好玩。另一个则是有基础的编程能力。除此之外,没有其他任何要求。也就意味着很多非计算机专业学生也有机会进组做研究,而且现在也不止他们组,其实这种跨专业参与的现象非常明显。
最后,还问了问张林峰,看到当前这么多大模型创业团队,是否有兴趣创业呢?
他思考了一会儿表示:看有没有这样更好的成果转化机会,毕竟做科研还是很烧钱的。
但是反正如果没有找到特别好的点的话,我也不想就是为了创业去创业,但是我会一直关注的。






