
不圆整理自凹非寺
量子位 | 公众号 QbitAI
多模态时代应如何评估模型的视觉输出能力?
来自清华大学、腾讯混元、斯坦福大学、卡耐基梅隆大学等顶尖机构的研究团队联合发布了 RBench-V:一款针对大模型的视觉推理能力的新型基准测试。
过去的评估基准主要集中于评估多模态输入和纯文本推理过程。
而 RBench-V 系统性评估了当前主流大模型基于“画图”的视觉推理能力:
比如在图中画出辅助线、描点连线、绘制光线路径、标注目标区域,等等。

结果发现,即使是表现最好的模型 o3,在 RBench-V 上的准确率也只有 25.8%,远低于人类的 82.3%。
这篇论文在 reddit machine learning 社区引发了讨论,有网友评价:
- 有趣的现象,视觉推理连小孩都能做到,GPT-4o 却做不到。

RBench-V:专为模型视觉推理设计
为了评估模型的跨模态推理能力,RBench-V 精心设计并筛选了共计 803 道题目,涵盖几何与图论(数学)、力学与电磁学(物理)、多目标识别(计数)以及路径规划与图形联想(图形游戏)等多个领域。
与以往仅要求文字回答的多模态评测不同,RBench-V 的每一道题都明确要求模型生成或修改图像内容来支持推理过程:
简单地说,就是让大模型像人类专家一样,通过绘制辅助线、观察图形结构等可视化方式进行思考。
这种对“画出图以辅助思考”过程的强调,对模型的视觉理解和图文协同推理能力提出了全新的要求。
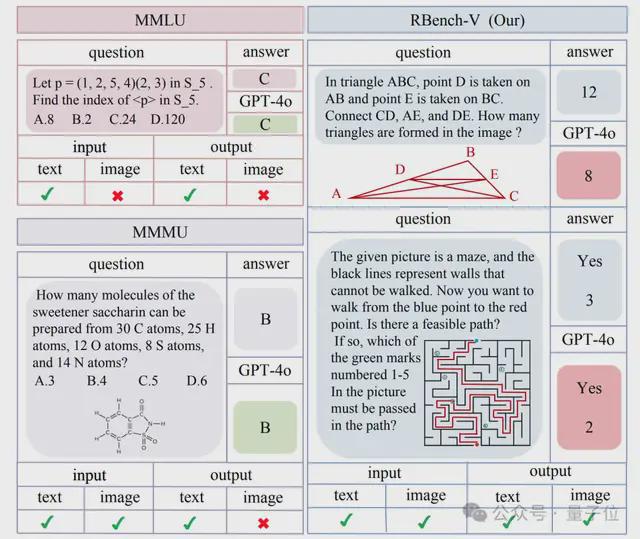
评测发现,尽管 GPT-4o、Gemini、o3 等新一代大模型标榜具备“多模态理解与生成”能力,它们在真正需要图像输出参与推理的问题上仍显得力不从心。
主流大模型的评测结果:远不及人类水平
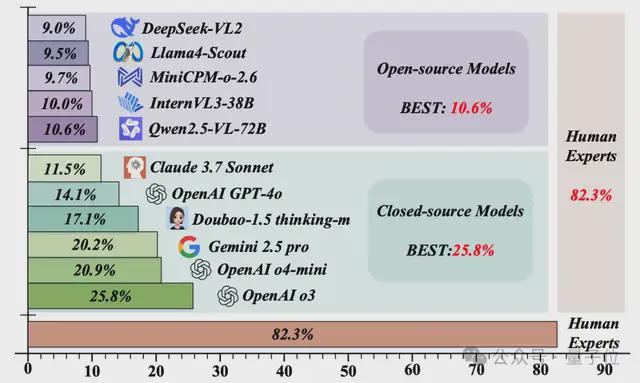
在 RBench-V 的评测中,即便是当前业界最强的闭源模型,也远远比不上人类视觉推理能力。
OpenAI 发布的旗舰模型 o3 以 25.8% 的整体准确率排名首位,Google 最新推出的 Gemini2.5 紧随其后,得分为 20.2%。
但这两者的表现与人类专家高达 82.3% 的平均准确率相比,依然很不够看,说明了现有模型在复杂多模态推理任务中认知能力的严重不足。
在开源模型阵营中,主流代表如 Qwen2.5VL、InternVL、LLaVA-OneVision 等模型的准确率普遍徘徊在8% 至 10% 之间,甚至在某些任务维度上接近“随机作答”的水平——
所谓“把答题卡放地上踩一脚”的水平。
这种悬殊的表现不仅揭示了当前开源生态在多模态输出生成上的技术瓶颈,也反映出大模型从“看懂图”到“画出图以辅助思考”的能力缺失。
当前,大模型对于视觉推理尚处于早期探索阶段。
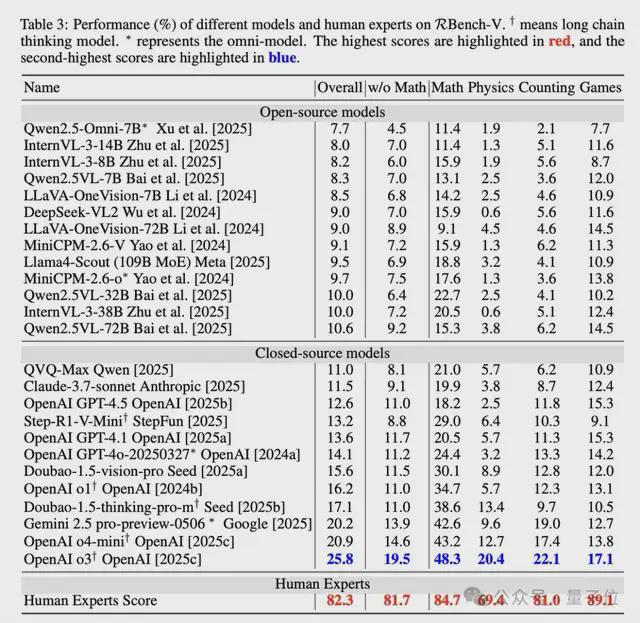
此外,通过比较不同模型的得分,可以看到:仅靠扩大模型参数规模、引入图像输入通道,或在文字层面堆叠长链条思维(Chain-of-Thought,CoT)并不能有效提升模型的视觉推理能力。
当下模型的重大短板:难以借助图像进行推理
RBench-V 的研究揭示了一个关键问题:当前的大模型在处理需要空间直觉和图像操作的几何类问题时,往往选择“走捷径”。
与人类专家倾向于通过直观的可视化方法进行思考不同,大多数模型更习惯于将图形问题抽象为坐标系下的代数表达,并采用文本推理路径完成解题。
这种“用文字绕过图形”的策略虽然在某些场景下能够给出正确答案,但实际上掩盖了其对图像信息的深层理解缺失,也暴露出它们“表面聪明,实则薄弱”的多模态推理能力。
RBench-V 的实验结果显示,即便是采用长文本推理路径或具备“看图说话”能力的模型,在面对需要图像输出的复杂问题时,仍然束手无策。

RBench-V 团队指出,真正推动大模型迈向“类人智能”的突破口,在于构建能够在推理过程中主动生成图像、构图辅助思考的认知框架。
这其中,多模态思维链(Multi-modal Chain-of-Thought,M-CoT)机制、智能体推理(Agent-based Reasoning)范式等新兴方法,可能成为人工智能通往未来的重要路径。
论文、代码、数据均可在项目主页找到:






