闻乐发自凹非寺
量子位 | 公众号 QbitAI
既能提升模型能力,又不显著增加内存和时间成本,LLM 第三种 Scaling Law 被提出了。
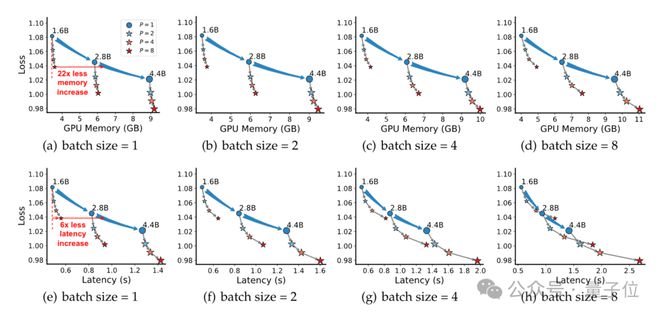
对于 1. 6B 模型,能实现性能接近 4.4B 模型,内存占用仅为后者的1/22,延迟增加量为1/6。
并且可直接应用于现有模型(如 Qwen-2.5),无需从头训练。
这就是阿里通义团队提出的 PARSCALE。

目前 LLMs 的优化主要有两种思路:参数扩展(如 GPT-4)和推理时间扩展(如 DeepSeek-R1),但会增加内存和时间成本。
阿里通义团队提出的新范式受 CFG(无分类器引导)双路径推理机制的启发。
他们将 CFG 的并行思想从 “生成阶段的推理优化” 扩展为 “训练和推理全流程的「计算缩放」”。
让我们来扒一扒技术细节。
将 CFG 的并行思想扩展到计算缩放
PARSCALE 对于 CFG 双路径的灵感迁移
CFG 通过同时运行有条件生成(输入提示词)和无条件生成(不输入提示词)两条路径,再通过加权平均融合结果,提升生成质量(如文本相关性、图像细节精准度)。
其核心在于利用并行计算(两次前向传播)增强模型决策的多样性和准确性,而无需增加模型参数。
研究人员观察到 CFG 的有效性可能源于计算量的增加(两次前向传播),而非单纯的条件引导。
由此提出假设:并行计算的规模(如路径数量)可能是提升模型能力的关键因素,而非仅依赖参数规模或推理时间的串行扩展(如生成更多 token)。
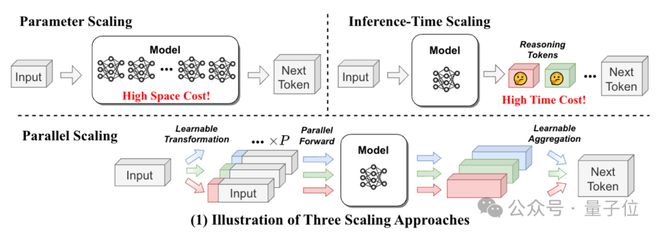
CFG 用 2 条并行路径提升性能,PARSCALE 则将路径数量扩展为P条(如P=8),并通过可学习的输入变换和动态聚合,使并行计算成为一种可扩展的 “计算缩放” 范式。下图展示了 PARSCALE 方法。
PARSCALE 改进的并行计算框架
1、输入层:可学习的多路径输入变换
核心改进是将 CFG 的固定双路径扩展为P条可学习的并行路径,每条路径通过可训练的前缀嵌入生成差异化输入。
- 前缀嵌入生成:为每个并行路径引入可训练的前缀向量(维度与输入嵌入一致),拼接在原始输入前,形成路径专属输入。
- KV 缓存区分:在 Transformer 的注意力层中,不同路径的键(K)和值(V)缓存相互独立,确保各路径的计算互不打扰,增强输出多样性。
2、计算层:并行前向传播
- 并行执行:将P个差异化输入同时输入模型,利用 GPU 的并行计算能力,一次性完成P路前向传播,生成P个输出流。
- 效率优势:通过批量矩阵运算实现P路并行,计算效率随P线性增长,共享模型主体参数,仅增加前缀嵌入等少量可训练参数。
3、输出层:动态加权聚合
通过多层感知机(MLP)动态计算各路径输出的聚合权重,替代 CFG 的固定权重机制:若某路径输出与当前输入语义匹配度高,MLP 会为其分配更高权重。
PARSCALE 更高效
PARSCALE vs. 参数扩展
当P=8 时,1.6B 参数模型在 HumanEval 的性能(Pass@1=39.1%)接近 4.4B 参数模型(Pass@1=45.4%),但内存占用仅为后者的1/22,延迟增加量为1/6。
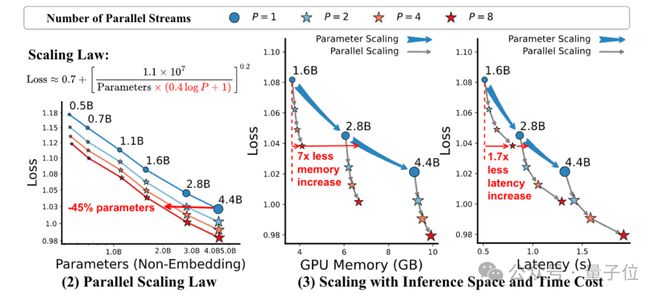
在 GSM8K 数学推理任务中,P=8 使 1.8B 模型性能提升34%(相对基准),显著高于参数扩展的增益。
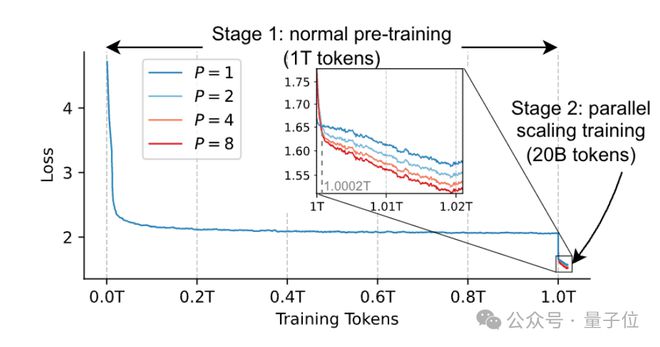
两阶段训练策略
阶段1:用传统方法预训练模型至收敛(1Ttokens)。
阶段2:冻结主体参数,仅训练前缀嵌入和聚合权重(20Btokens,占总数据的 2%)。
P=8 模型在 GSM8K 上提升 34%,且与从头训练效果相当,证明少量数据即可激活并行路径的有效性。且该策略使训练成本降低约 98%
适配现有模型
研究团队在 Qwen-2.5-3B 模型上进行持续预训练和参数高效微调(PEFT),仅调整前缀和聚合权重。
结果显示,在代码生成任务(HumanEval+)中 PEFT 方法使 Pass@1 提升 15%,且冻结主体参数时仍有效,证明动态调整 P 的可行性。
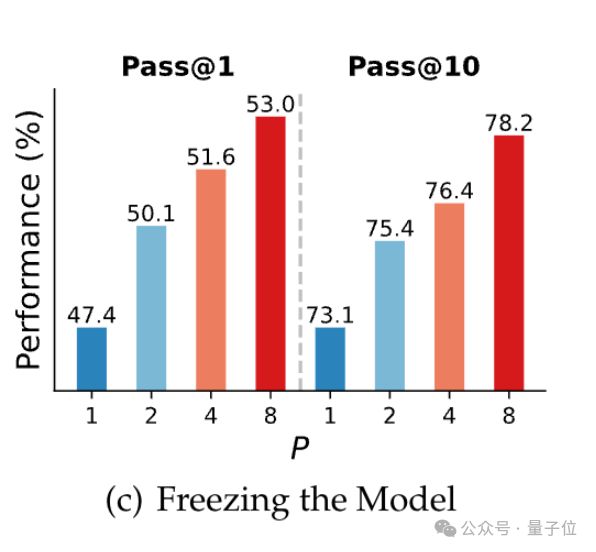
PARSCALE 通过可学习的多路径输入、动态聚合权重、全流程并行优化,将 CFG 的 “双路径启发” 升级为一种通用的计算缩放范式。
感兴趣的朋友可到官方查看更多细节~
论文链接:https://arxiv.org/abs/2505.10475
代码地址:https://github.com/QwenLM/ParScale
参考链接:https://x.com/iScienceLuvr/status/1923262107845525660
— 完 —






