
新智元报道
编辑:LRST 好困
EfficientLLM 项目聚焦 LLM 效率,提出三轴分类法和六大指标,实验包揽全架构、多模态、微调技术,可为研究人员提供效率与性能平衡的参考。
近年来,大型语言模型(LLM)如 GPT 系列取得了革命性进展,在自然语言处理、内容创作、多语言翻译乃至科学研究等众多领域展现出惊人能力。
然而,模型参数量(如 DeepseekR1 的 671B 参数)和上下文窗口的急剧膨胀,带来了巨大的计算力(GPT-3 训练约需 3640Petaflop/s-days)、能源消耗和资金投入(GPT-3 训练成本估计超 460 万美元)。
高昂的成本已成为制约 LLM 进一步发展和广泛应用的关键瓶颈。
EfficientLLM 项目应「效率测评」需求而生,也是首个针对 LLM 效率技术进行端到端、百亿级参数规模的系统性实证研究。

项目详情:https://dlyuangod.github.io/EfficientLLM/
模型库:https://huggingface.co/Tyrannosaurus/EfficientLLM
研究人员在配备了 48 块 GH200 和 8 块 H200 GPU 的生产级集群上执行效率测评,确保了对真实世界中 LLM 性能与能耗权衡的精确测量。
EfficientLLM 的核心目标是为学术界和工业界的研发人员提供一个清晰、数据驱动的导航图,帮助研究人员在下一代基础模型的「效率-性能」复杂地貌中找到最佳路径。
EfficientLLM 的三维评测框架与核心指标
研究人员创新性地提出了一个统一的三轴分类法来系统评估 LLM 效率,覆盖模型生命周期的关键阶段:
架构预训练(Architecture Pretraining)
此部分专注于为模型设计者和研究者在构建新型 LLM 架构时,提供关于计算资源和能源成本预算的精确分析,并深入评估了多种高效注意力机制变体(如多查询注意力 MQA、分组查询注意力 GQA、多头潜在注意力 MLA、原生稀疏注意力 NSA)以及稀疏混合专家模型(MoE)的效率表现。
微调(Fine-tuning)
针对需要将预训练基础模型适配到特定下游任务或专业领域的实践者,研究人员提供了参数高效微调(PEFT)方法的效率基准。评估涵盖了 LoRA、RSLORA、DoRA 等主流 PEFT 技术。
位宽量化(Bit-width Quantization)
面向模型部署工程师,研究人员评估了如何通过模型压缩技术(特别是无需重训即可直接部署的训练后量化方法,如 int4 和 float16)有效降低服务成本和推理延迟。
评估指标
为全面刻画效率,EfficientLLM 还引入了六个相互正交的细粒度评估指标:
1. 平均内存利用率(Average-Memory-Utilization,AMU)
2. 峰值计算利用率(Peak-Compute-Utilization,PCU)
3. 平均延迟(Average-Latency,AL)
4. 平均吞吐量(Average-Throughput,AT)
5. 平均能耗(Average-Energy-Consumption,AEC)
6. 模型压缩率(Model-Compression-Rate,MCR)这些指标共同捕捉了硬件饱和度、延迟与吞吐量的平衡,以及碳排放成本等关键因素。
基准测试涵盖了超过 100 个「模型-技术」组合,纳入从 0.5B 到 72B 参数规模的多种 LLM。

EfficientLLM 的三大核心洞见
效率优化是「没有免费午餐」的量化权衡(Efficiency Involves Quantifiable Trade-offs)
百余项实验清晰地表明,不存在一种能在所有维度上都达到最优的通用效率技术。
每一种被评估的方法,在提升至少一个效率指标的同时,几乎总会在其他某个或某些指标上有所妥协。
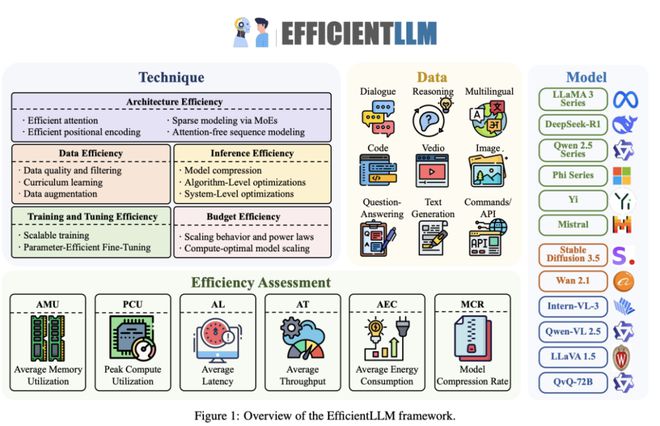
以稀疏混合专家模型(MoE)为例,能有效降低推理时的 FLOPs(浮点运算次数)并提升下游任务的准确率,但其代价是峰值显存需求增加约 40%(因为需要存储所有专家网络的参数)。
int4 量化技术则展现了另一面:可以将模型的内存占用和能耗降低高达 3.9 倍,模型压缩率表现优异,但根据实测数据,通常伴随着约3-5% 的任务平均得分下降。
最优效率策略高度依赖于具体任务和模型规模(Optima are Task- and Scale-Dependent)
效率的「最优解」并非一成不变,而是高度依赖于应用场景、模型规模和硬件环境。
高效注意力机制:在架构预训练阶段,对于内存资源极度受限的设备(如端侧推理),MQA (多查询注意力)因其共享键值头设计,展现出最佳的内存占用和延迟特性。
而当追求极致的语言生成质量时(以困惑度 PPL 为衡量标准),MLA (多头潜在注意力)则表现更优。若目标是最低能耗部署,NSA (原生稀疏注意力)则是首选。
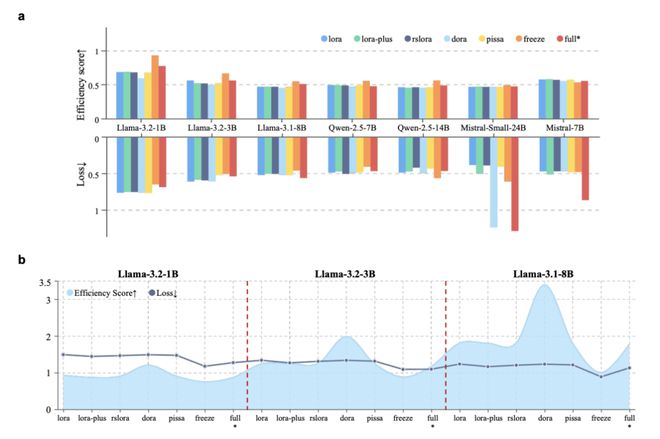
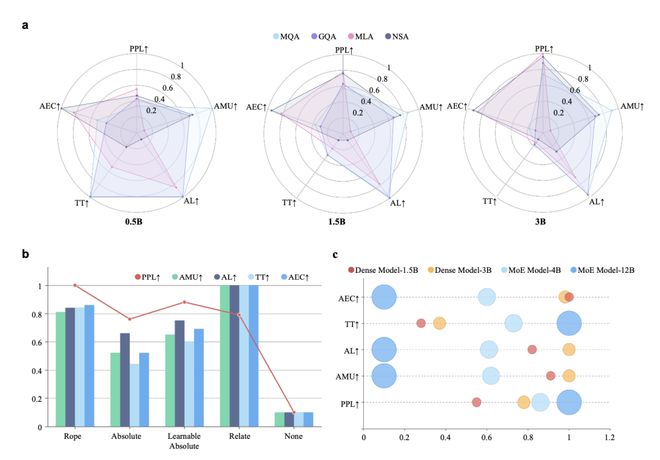
PEFT 方法的规模效应:在微调阶段,对于 1B 到 3B 参数规模的较小模型,LoRA 及其变体(如 DoRA,统称 LoRA-plus)在特定的内存约束下能达到最低的性能损失(即最佳的任务表现)。
然而,当模型规模扩展到 14B 参数以上时,RSLORA 在效率上反超 LoRA,展现出更低的延迟和功耗。
对于超大规模模型的微调,参数冻结(仅更新部分层或组件)策略虽然可能牺牲少量任务精度,但能提供最佳的端到端微调延迟。
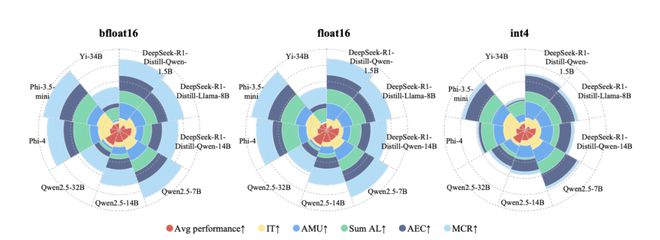
量化精度选择:在推理阶段,测试(涵盖 Llama-3,DeepSeek,Qwen 等 1.5B 至 34B 模型)表明,int4 训练后量化能显著提升资源效率。
内存占用减少接近理论上的 4 倍,吞吐量(每秒处理词元数)在内存受限条件下可提升三倍,而平均任务性能得分仅有小幅下降(例如 DeepSeek-R1-Distill-Qwen-14B 的平均分从 bf16 的 0.4719 降至 int4 的 0.4361)。
在 16 位浮点格式中,bfloat16 在 Hopper 架构 GPU (GH200/H200) 上,相较于 float16,始终在平均延迟和能耗方面表现更优,这得益于现代 NVIDIA GPU 对 bfloat16 运算的原生硬件加速。
LLM 效率技术可广泛迁移至跨模态模型(Broad ApplicabilityAcrossModalities)
研究人员将 EfficientLLM 的评估框架成功扩展到了大型视觉模型(LVMs)和视觉语言模型(VLMs),如 Stable Diffusion3.5、Wan2.1 和 Qwen2.5-VL 等。
实验结果令人鼓舞:在 LLM 上得到验证的效率技术,如 MQA/GQA 等高效注意力机制,能够有效地迁移并改进 LVM 的生成质量(以 FID 分数为衡量标准);PEFT 方法同样在 LVM 和 VLM 上取得了良好的性能-效率权衡,表明针对 LLM 的效率优化研究成果具有更广泛的适用性。
开放共享,赋能未来
研究人员即将开源完整的评估流程代码以及排行榜,在为全球的学术研究者和企业工程师在探索下一代基础模型的效率与性能平衡时,提供一个坚实的、可复现的、值得信赖的「指南针」。
研究成果可以为从业者提供基于严谨实证数据的可操作建议,帮助研究人员在具体的任务需求和资源限制下,做出更明智、更高效的模型和技术选型决策,而不是仅仅依赖理论推演或有限的经验。
LLM 的效率优化是一个持续演进的系统工程,EfficientLLM 的探索也仅是其中的一部分,诸如训练基础设施优化、基于强化学习的训练后对齐、测试时扩展策略等重要议题,开发团队计划在未来进行深入研究。
参考资料:






