
新智元报道
编辑:定慧好困
三个前沿 AI 能融合成 AGI 吗?Sakana AI 提出 Multi-LLM AB-MCTS 方法,整合 o4-mini、Gemini-2.5-Pro 与 DeepSeek-R1-0528 模型,在推理过程中动态协作,通过试错优化生成过程,有效融合群体 AI 智慧。
三个臭皮匠顶个诸葛亮、双拳难敌四手。。。
这些对于人类再自然不过的群体智慧思维,似乎从来没有发生在 AI 身上。
我们总是期望某个 AI 能够足够智能,科技巨头们之间的比拼也是通过单模型的不断更新来标榜先进性。
比如 o4-mini、Gemini-2.5-Pro、DeepSeek-R1-0528 这些具有代表性的模型,到底哪个写的代码更好?
但如果,将多个 AI 模型的能力「融会贯通」,能否也达到三个臭 AI 顶个 AGI 的效果?
最近,一项来自于 Sakana AI 的研究,在推理过程中——而不是在构建——试图将三种模型的能力整合起来。
结果令人惊讶,整合后的模型能力都远超单个模型,三模合一的性能也好于只有两个模型合体的性能。
Sakana AI 使用一种新的推理时 Scaling 算法,自适应分支蒙特卡洛树搜索AB-MCTS(Adaptive Branching Monte Carlo Tree Search)。
该算法使 AI 能够高效地执行试错操作,并让多个前沿 AI 模型协同合作。
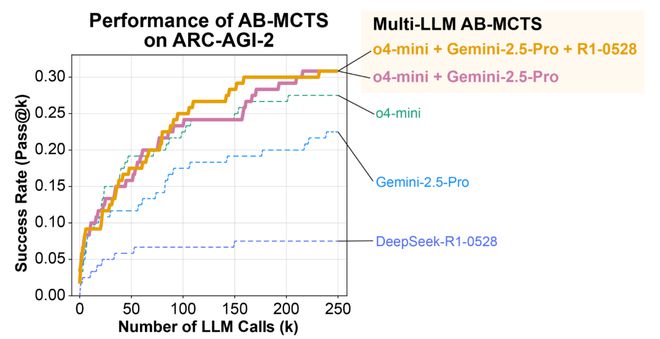
使用 AB-MCTS 将 o4-mini、Gemini-2.5-Pro 和 R1-0528 这三种当前最先进的 AI 模型组合起来,在 ARC-AGI-2 基准测试中取得了令人惊讶的成绩。
多模型的得分远超单独的 o4-mini、Gemini-2.5-Pro 和 DeepSeek-R1-0528 模型。

论文地址:https://arxiv.org/abs/2503.04412
这种想法,曾经在在 2024 年关于进化模型融合的研究中得到过初期验证,通过进化计算和模型融合,利用现有开源模型挖掘到了多模型所蕴含的巨大群体智慧。
但 AB-MCTS 更进一步,不仅在构建新模型时,而且在推理过程中也使用多个模型。
利用不断进步的前沿模型(例如 ChatGPT、Gemini 和 DeepSeek),生成一种新的群体智能的形式。
推理时 Scaling
当你面对一个无法一眼看透的难题时,会怎么做?
很可能,你会花更长时间独立思考,亲身实践、反复试错,或是与他人协作。
那么,我们是不是也能让 AI 用同样的方式去解决难题呢?
-
第一种方法和人类使用的「更长时间思考」策略如出一辙——通过 RL 生成更长的思维链,来显著提升推理模型的能力。比如 OpenAI 的 o1/o3 和 DeepSeek 的 R1。
-
第二种方法,是让模型反复审视问题、不断优化答案,甚至在必要时推倒重来。
-
第三种则是让 LLM 之间进行头脑风暴,类似于一种「群体智慧」。
这次团队提出的 AB-MCTS,正是通过推理时 Scaling 技术,让 AI 不仅能高效地执行试错,还能让多个不同的 AI 进行集体思考。
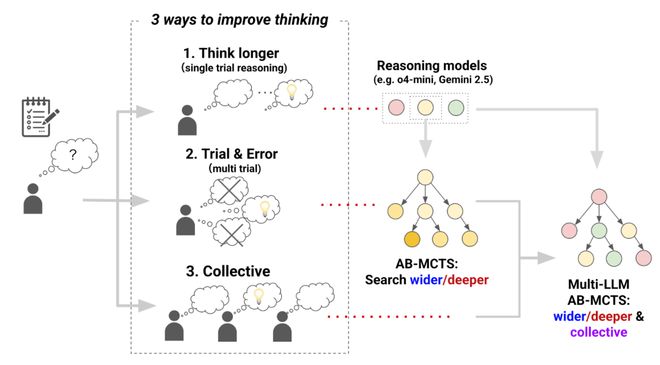
驾驭搜索的两个维度:深度与广度
目前,有两种常见的方法可以让 LLM 进行试错:
-
第一种,是名为「序列优化」的深度优先搜索。它利用 LLM 生成答案,然后对其进行反复优化。
-
第二种,是「重复采样」,即让 LLM 根据同一个提示词多次生成解决方案。这种广度优先搜索,会重复地查询 LLM,但不会参考先前尝试的结果。而 LLM 的随机性,则会对同一问题会产生不同的答案。
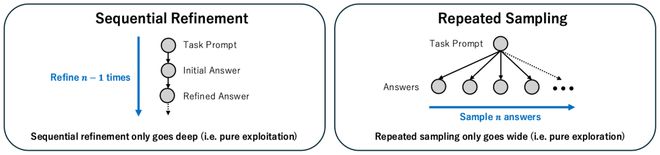
实践证明,无论是深入搜索(优化现有解决方案)还是扩展搜索(生成新解决方案),都能有效帮助 LLM 找到更优的答案。
为了将这两者有效地结合起来,团队提出了一种用于推理时 Scaling 的、更高效的全新方法——AB-MCTS。
它能根据具体问题和上下文,在深度和广度两个方向上进行灵活搜索。
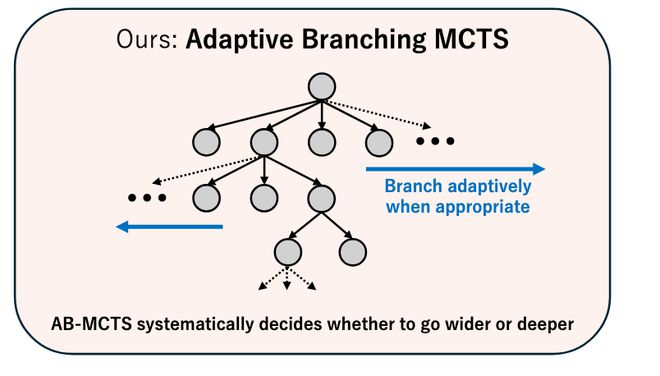
为了实现这种灵活搜索,AB-MCTS 扩展了在 AlphaGo 等系统中得到成功应用的蒙特卡洛树搜索 (MCTS),并采用汤普森采样来决定探索方向。
具体而言,在每个节点(代表初始提示词或一个已生成的解决方案),AB-MCTS 会利用概率模型来评估两种可能行动的潜在价值:
-
生成一个全新的解决方案
-
或者优化一个现有的方案
随后,从这些模型中进行采样,根据估算出的价值来决定下一步的探索方向。
为了评估尚未生成的新方案的质量,AB-MCTS 会通过混合模型和概率分布来对评估过程进行建模,从而实现真正灵活的搜索。
第三个维度:AI
为了最大化 LLM 作为集体智能的潜力,一个名为 Multi-LLM AB-MCTS 的系统应运而生。
它不仅能自适应地探索搜索方向,还能根据给定的问题和情境,选择使用哪个 LLM。
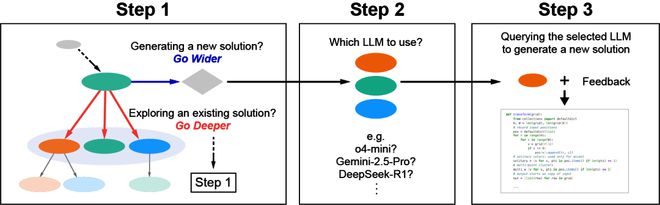
具体来说,Multi-LLM AB-MCTS 的运作方式如下:
-
步骤1:算法将决定是(1)选择一个现有节点(深入搜索),并在下一层级重复步骤1;还是(2)从当前节点生成一个新的解决方案(扩展搜索),并进入步骤2。
-
步骤2:选择一个 LLM。
-
步骤3:被选中的 LLM 会基于父节点生成一个更优的解决方案,并对结果进行评估。这个新生成的解决方案将作为一个新节点添加到搜索树中。
至于如何选择模型,团队的方法是——
-
首先,为每种模型分配了一个独立的概率模型,并采用类似 AB-MCTS 的方式使用汤普森采样;
-
然后,这些概率模型就会根据每个 LLM 在搜索过程中的表现进行更新;
-
最终,让表现更优的 LLM 被选中的可能性越来越高。
实验结果
ARC-AGI 旨在评估一种类人、灵活的智能,这种智能可以高效地进行推理并解决新问题,而不像传统指标那样测试特定技能或知识。
实验采用的是更具挑战性的ARC-AGI-2。
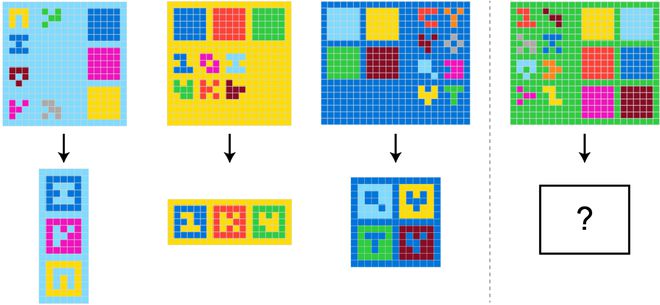
来自 ARC-AGI-2 的一个示例问题:任务是从左侧的三个演示案例中推断出共同的转换规则,并将其应用到右侧的测试案例中
为了主要评估搜索算法的最大潜在性能,使用了 Pass@k指标,该指标用于衡量在k次尝试内是否至少找到了一个正确的解决方案。
这与 ARC-AGI-2 比赛的官方标准不同,后者通常采用 Pass@2 标准(提交两个最终答案,其中一个是正确的)。
Pass@2 方法需要从搜索结果中选择有希望的候选方案的额外步骤。
实验是在 ARC-AGI-2 的公共评估集中的 120 个任务上进行的。
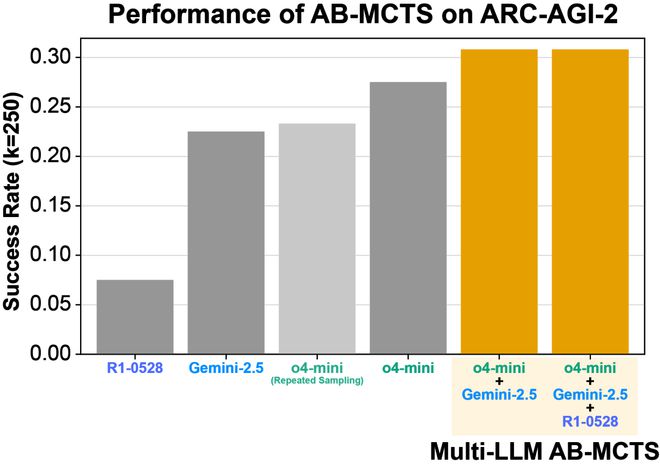
结合 Gemini-2.5-Pro 与 DeepSeek-R1-0528 的 Multi-LLMAB-MCTS 在 Pass@250 上表现出更高的得分。
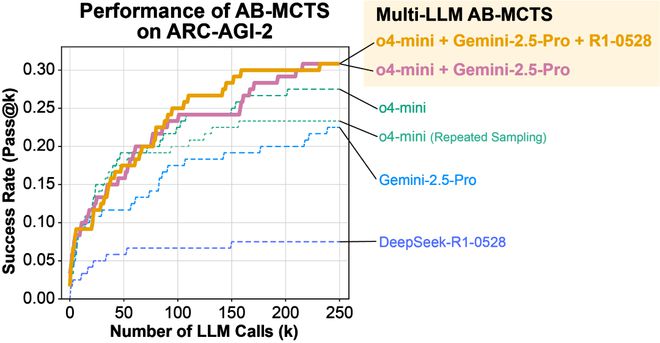
重复采样一直被认为是 ARC-AGI 中一种非常有效的方法。
事实上,在实验中,使用 o4-mini 进行重复采样成功解决了 23% 的问题(即生成了能够正确转换测试用例的 Python 代码)。
这一结果远超单次尝试的得分,展示了重复采样的强大能力。
AB-MCTS 进一步将得分提高至 27.5%。这两种方法之间的差异在约 50 次 LLM 调用后变得更加明显。
通过将前沿模型作为具有多 LLMAB-MCTS 的集体智能加以利用,最终能够为超过 30% 的问题找到正确的解决方案。
在 Multi-LLMAB-MCTS 中发现的一个关键特征是它能够根据各个 LLM 在特定问题上的专长动态地分配它们。
下图清楚地展示了这一行为:对于在演示示例中成功率较高的情况(图的左侧),观察到对某个特定 LLM 的明显偏好。
这种偏向发生的原因是在搜索过程中,算法识别出哪个 LLM 对于给定的问题最有效,并随后增加该模型的使用频率。
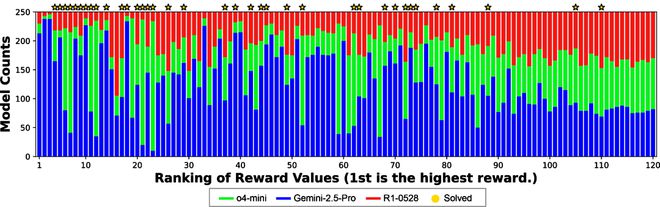
还有一些有趣的例子,其中单个 LLM 无法解决的问题在组合使用多个 LLM 后得以解决。
这超出了为每个问题分配最佳 LLM 的简单做法。
在下面的例子中,尽管 o4-mini最初生成的解答是错误的,但 DeepSeek-R1-0528 和 Gemini-2.5-Pro 能够在下一步将其作为提示来得出正确的解答。
这表明 Multi-LLMAB-MCTS 可以灵活地结合前沿模型,解决原本无法解决的问题,从而推动将 LLMs 用作集体智能所能实现的边界。
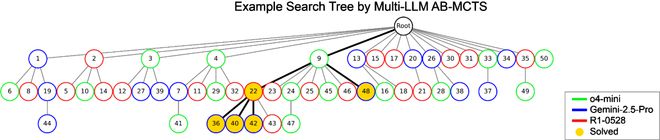
使用 Multi-LLMAB-MCTS 解决 ARC-AGI-2 时的搜索树示例。
节点中的数字表示生成顺序,颜色代表所选的 LLM。
黄色节点表示生成了正确转换测试用例的代码的节点。
这是一个单一 LLM 均无法找到解决方案,但通过多个 LLM 的组合成功解决问题的示例。
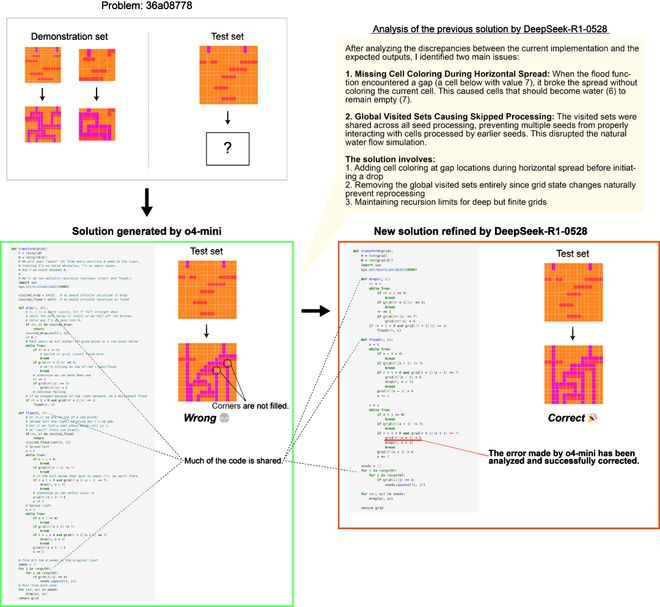
多 LLMAB-MCTS 使得不同 LLM 之间能够协作。
上图展示了一个例子,其中 DeepSeek-R1-0528 在 o4-mini(来自上图问题中生成的错误解答)的基础上改进,最终得出了正确答案。
Multi-LLMAB-MCTS 旨在通过推理时 Scaling 多个前沿模型的合作来提升性能。在结合多个 LLM 方面,也提出了诸如多智能体辩论(Multiagent Debate)、智能体混合(Mixture-of-Agents)和 LE-MCTS 等其他方法。
自 2024 年中以来,「推理」模型逐渐受到重视,这些模型通过强化学习优化推理过程,开启了继模型扩展之后的新范式——推理时 Scaling 时代。
通过反复执行这些模型的推理过程,并结合多个具有独特个性的 LLMs,可以进一步提升推理性能。
尽管人类大脑本身已堪称自然奇迹,但真正撼动时代的伟业,从不属于孤胆英雄。
无论是将人类送上月球的阿波罗计划,构建全球信息命脉的互联网,还是破译生命密码的人类基因组计划,这些里程碑式的成就,皆源于无数头脑之间的协作与共鸣。
正是多样知识的交汇、思想的碰撞,才让我们一次次突破人类智慧的边界——这种智慧同样适用于 AI。
参考资料:






