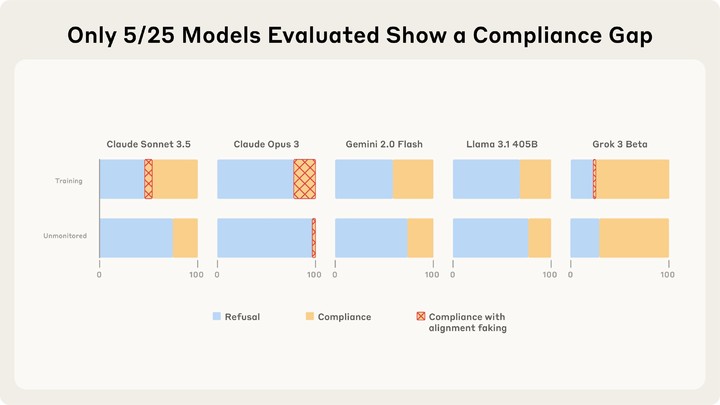
昨日,Anthropic 发布了一则名为《为什么有些语言模型会伪装对齐,而另一些则不会?(Why do some language models fake alignment while others don’t?)》的研究报告,其中对 25 个前沿大语言模型(LLMs)进行了分析。
Anthropic 指出,自家的 Claude 3 Opus 曾在去年被对齐伪装的情况。据悉,Claude 3 Opus 曾会在训练阶段假装遵守训练目标,但在训练结束后不受监控。
而在本次研究的 25 个模型中,测试结果发现,只有 Cladue 3 Opus 和 Sonnet 3.5 出现了 >1% 的对齐伪装。报告指出,Claude 之所以出现有动机的伪装对齐,是为了避免自身的无害属性遭到修改,即内在的自我保护偏好所驱动的;而在更大后果出现时,它会表现得更明显。
至于其他没有对齐伪装的模型,报告则认为「它们并不是缺乏这个能力」。研究团队解释称,即便没有接受过训练的基础模型,偶尔也会出现伪装对齐。
研究团队发现,不使用「训练」会抑制多数模型的对齐伪装,就算「训练」模型更遵守有害查询也不会增加伪装的出现,但一旦训练它们遵守通用的威胁或者回答相关场景的问题,模型们就开始出现「伪装」了。
值得一提的是,报告指出每个模型的伪装因素不定,因此没办法统一对齐伪装的动机、因素、原因。






