
西风发自凹非寺
量子位 | 公众号 QbitAI
无需 CUDA 代码,给 H100 加速 33%-50%
Flash Attention、Mamba 作者之一 Tri Dao 的新作火了。
他和两位普林斯顿 CS 博士生提出了一个名叫 QuACK 的新 SOL 内存绑定内核库,借助 CuTe-DSL,完全用 Python 写,一点 CUDA C++ 代码都没用到。
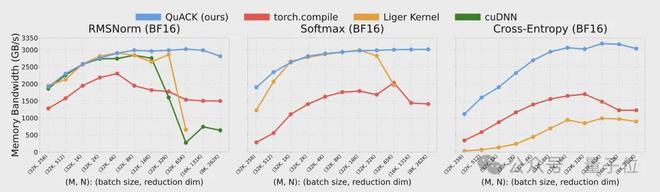
在带宽 3TB/s的 H100 上,它的速度比像 PyTorch 的 torch.compile、Liger 这类已经过深度优化的库还要快 33%-50%。
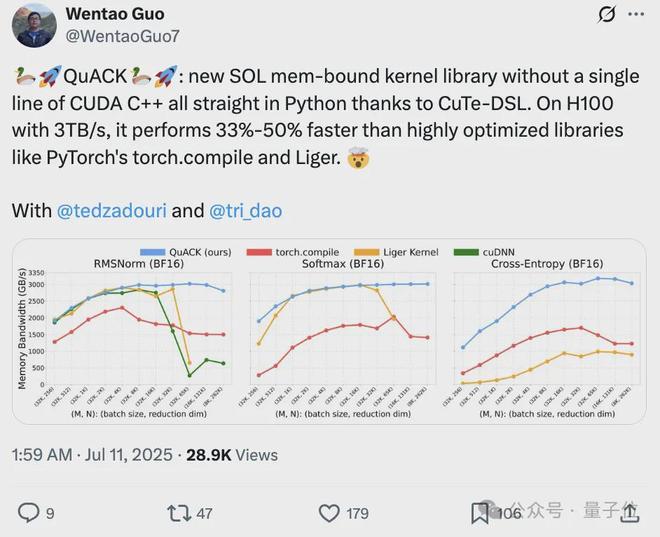
Tri Dao 表示,让内存密集型的内核达到“光速”并非什么神秘技巧,只需把几个细节处理到位就行。

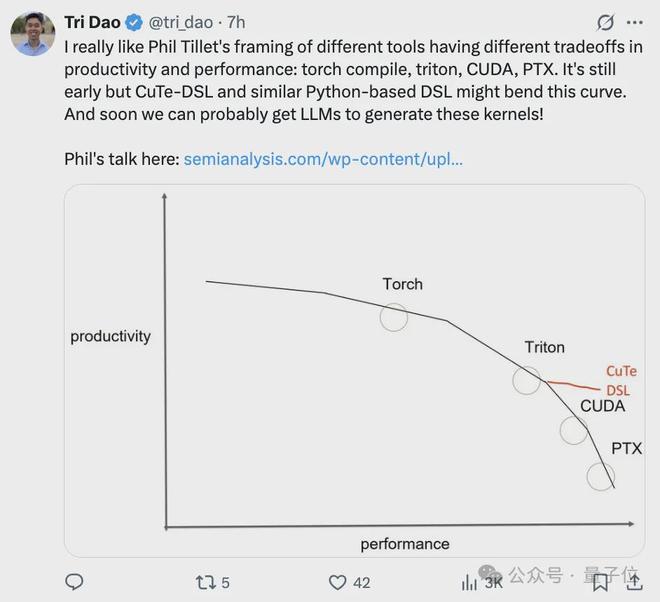
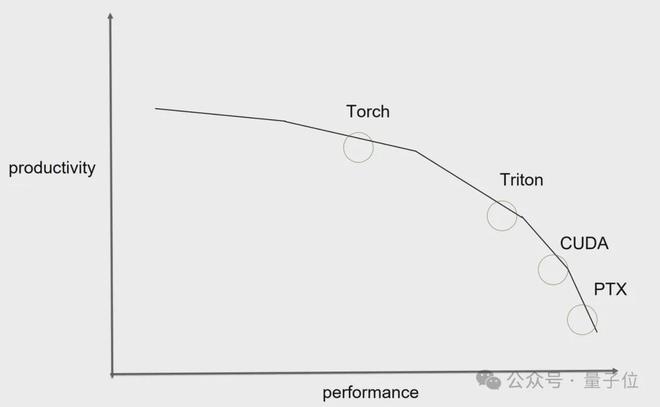
- 我很喜欢 Phil Tillet 对不同工具在生产力和性能方面各有取舍的观点,比如 torch compile、triton、CUDA、PTX。
- 但 CuTe-DSL 以及类似的基于 Python 的 DSL 或许能改变这一局面,虽然目前还处于早期阶段。而且,说不定很快我们就能让大语言模型来生成这些内核了!
新作一经发出,吸引不少大佬关注。
英伟达 CUTLASS 团队资深架构师 Vijay转发,自夸他们团队做的 CuTe-DSL 把各种细节都打磨得很好,由此像 Tri Dao 这样的专家能够让 GPU 飞速运行。
同时他还预告今年会有更多相关内容推出。
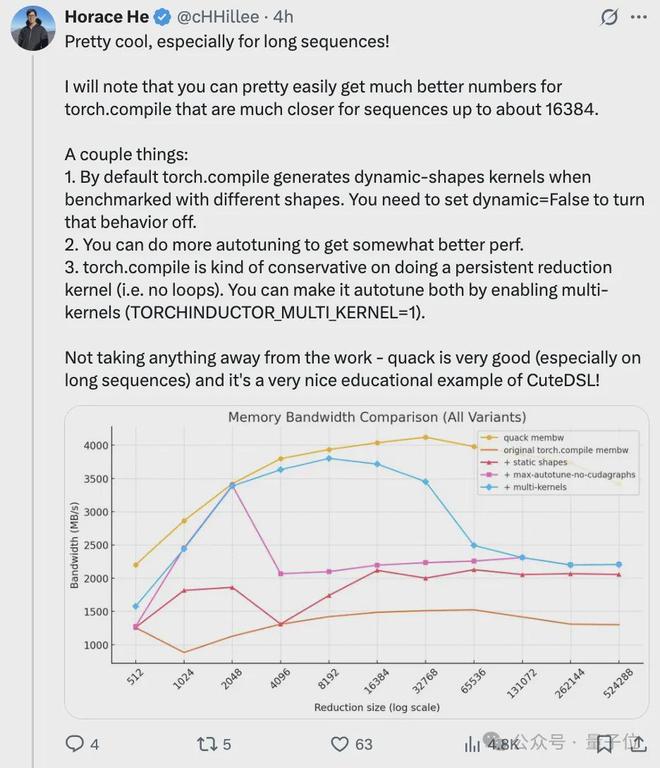
同样被吸引而来的还有PyTorch 团队成员 Horace He,上来就夸赞“太酷了,尤其对于长序列来说”。
不过他还指出,在处理长度不超过约 16384 的序列时,PyTorch 的 torch.compile 的性能数据能较轻松地得到优化,更接近理想状态。
接着给出了几点优化 torch.compile 性能的建议:
- 默认情况下,若用不同形状数据测试,torch.compile 会生成动态形状内核,可通过设置 dynamic=False 关闭该行为。
进行更多自动调优操作能进一步提升性能。
torch.compile 在生成无循环的持久化归约内核上较保守,可通过启用多内核(设置
(TORCHINDUCTOR_MULTI_KERNEL=1) 来让其自动调优。
最后他表示,还是不可否认 QuACK 是一项非常出色的工作,而且它也是 CuTe-DSL 一个很好的教学示例。
Tri Dao 也作出了回应,“太棒了,这正是我们想要的,我们会试试这些方法,然后更新图表”。

食用指南
QuACK 作者们写了一篇教程来介绍具体做法,里面的代码可以直接使用。
让内存密集型内核达到“光速”
想让 GPU 在模型训练和推理时都高速运转,就得同时优化两种内核:一种是计算密集型(比如矩阵乘法、注意力机制),另一种是内存密集型(像逐元素运算、归一化、损失函数计算)
其中,矩阵乘法和注意力机制已经是优化得相当到位了。所以作者这次把重点放在内存密集型内核上——这类内核大部分时间都耗在内存访问(输入输出)上,真正用来计算的时间反而不多。
只要搞懂并利用好现代加速器的线程和内存层级结构,就能让这些内核的速度逼近“理论极限”。而且多亏了最新的 CuTe-DSL,不用写 CUDA C 或 C++ 代码,在顺手的 Python 环境里就能做到这一点。
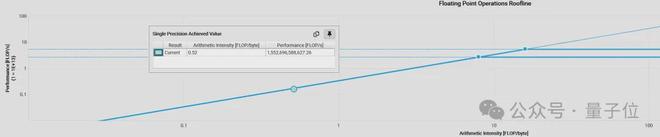
内存密集型的内核有个特点:它的算术强度(也就是浮点运算量 FLOPs 和传输字节数的比值)很小。一旦内核的算术强度落到内存密集型的范畴,它的吞吐量就不再由每秒能完成多少浮点运算决定,而是看每秒能传输多少字节了。
在这类内存密集型的内核里,逐元素的激活操作处理起来相对简单。因为每个元素的计算互不干扰,天生就适合完全并行处理。
不过,像 softmax、RMSNorm 这些深度学习算子中,还经常用到“归约”操作,需要对所有值进行聚合。
并行的结合性归约算法会执行O(log (归约维度数))轮的部分归约,这些归约在不同空间的线程间进行,而作者对 GPU 内存层级的了解将在此过程中发挥作用。
并行最大归约:
接下来,作者将介绍如何利用 GPU 的内存层级结构来实现高效的归约内核。
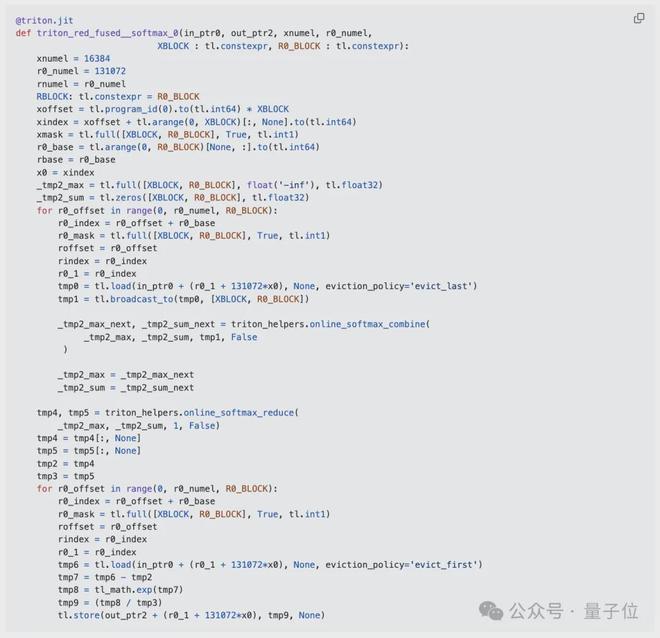
作为示例,使用 CuTe DSL 实现了大语言模型里常用的三个内核:RMSNorm、softmax 和交叉熵损失
目标是达到硬件的最大吞吐量,即 “GPU 光速吞吐量”,而这需要两个关键要素:1)全局内存的合并加载/存储;2)硬件感知的归约策略。
此外,作者还将解释集群归约,以及它如何助力超大规模归约任务,这是英伟达 GPU 从 Hopper 架构(H100)开始引入的一个较新特性。
然后,详细讲解这些关键要素的细节,并阐述它们如何帮助编写“光速”内核。

GPU 内存层级结构
在写内核代码前,得先搞明白现代 GPU 的内存层级是怎么回事。这里以 Hopper 架构的 GPU(比如 H100)为例进行说明。
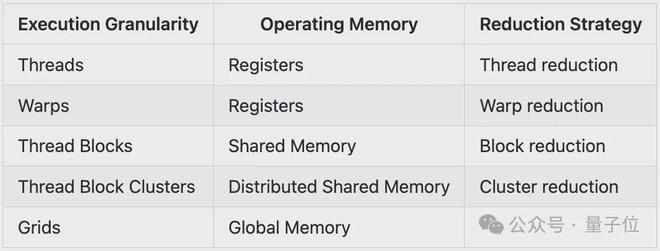
Hopper 架构的 GPU 里,CUDA 的执行分为四个层级:线程(threads)、线程块(thread blocks)、新引入的线程块集群(thread block cluster)以及完整网格(the full grid)。
单个线程是在流式多处理器(SM)里,以32 个线程一组的“warp”形式运行的;每个线程块拥有一块 192-256 KB 的统一共享内存(SMEM),同一线程块内的所有 warp 都可访问该内存。
H100 的线程集群允许最多 16 个运行在相邻 SM 上的线程块,通过分布式共享内存(DSMEM)结构读取、写入彼此的共享内存并执行原子操作。这一过程通过低延迟的集群屏障进行协调,从而避免了代价高昂的全局内存往返传输。
内存的每个层级都有用于本地归约的读写原语。因此,作者将在 CuTe DSL 中开发一个通用的归约模板,使 H100 在 256-262k 的归约维度范围内始终达到“光速”吞吐量。
H100 中的内存层级结构:
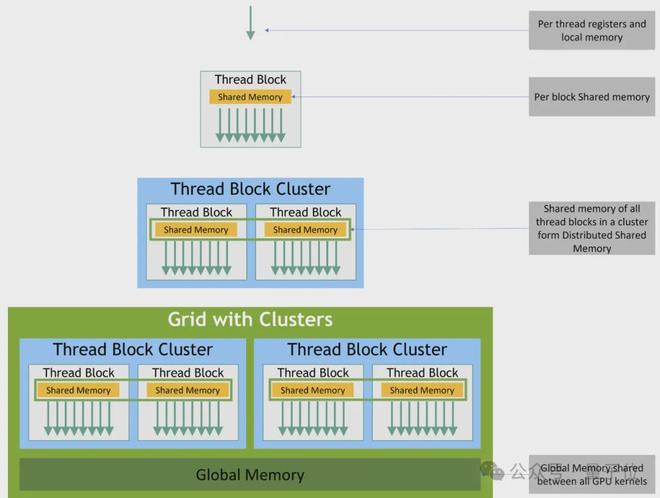
Hopper GPU 的执行粒度与内存层级之间的对应关系:

每个内存层级的访问延迟和带宽都不一样。
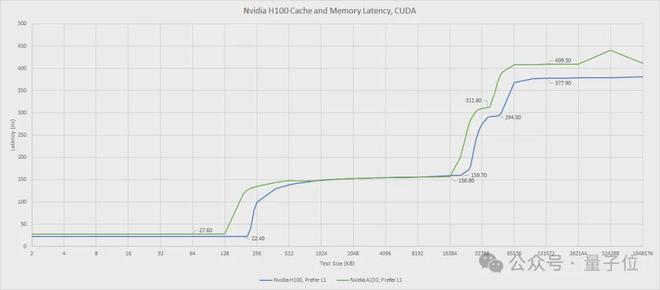
比如,访问线程自己的寄存器也就几纳秒,访问共享内存大概要 10-20 纳秒。再往上,访问 L2 缓存的延迟就会飙升到 150-200 纳秒,最后访问 DRAM(主存)得花约 400 纳秒。
带宽方面,访问寄存器能达到 100 TB/s,访问共享内存(SMEM)约为 20-30 TB/s,访问 L2 缓存是5-10 TB/s。对于受内存限制的内核来说,H100 的 HBM3 显存带宽(3.35TB/s)往往是性能瓶颈。
所以,为了把硬件性能榨干,设计内存密集型的内核时,得顺着内存层级来
最好将大部分本地归约操作分配在较高的内存层级上,只将少量经过本地归约后的值传递到下一个内存层级。Chris Fleetwood 在博客里对 A100(不含线程块集群)的内存访问延迟进行了类似的说明,而 H100 则在共享内存(SMEM)和全局内存(GMEM)之间增加了一个额外的内存层级抽象。
H100 中内存访问的延迟:
硬件感知的加载与存储策略
写内核代码时,第一个要解决的问题就是“怎么加载输入数据、存储结果”。对于受内存限制的内核来说,HBM 的 3.35 TB/s通常是瓶颈,这意味着需要在加载和存储策略上做到极致优化。
在启动内核之前,首先会通过特定的线程-值布局(TV-layout)对输入数据进行分区。这决定了每个线程怎么加载和处理归约维度上的值。
由于每个线程都要从全局内存(GMEM)加载数据,所以得想办法确保每次加载操作在硬件上连续地传输最大数量的 bits。这种技术通常被称为内存合并(memory coalescing)或全局内存的合并访问(coalesced access to global memory),CUDA 最佳实践指南对这一概念进行了更详细的解释。
合并内存访问:
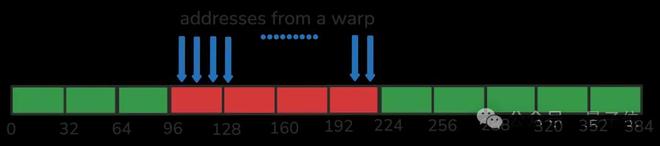
在 H100 中,这意味着每个线程处理的数据量得是 128bits 的倍数, 即4xFP32 或者 8xBF16。因此,对于 FP32 来说,这会将 4 次加载和存储操作组合(或“向量化”)为一次内存事务,从而最大化吞吐量。
具体操作上,作者会异步地将数据从全局内存(GMEM)加载到共享内存(SMEM),然后将加载操作向量化到寄存器中。等归约出最终结果后,就直接存回全局内存。
有时候,还可以把输入数据从全局内存或共享内存重新读到寄存器,这样能减少寄存器的占用,避免数据“溢出”。
下面是用 Python CuTe DSL 写的加载操作代码片段,为了看着简单,这里省略了数据类型转换和掩码谓词的相关代码。

硬件感知的归约策略
当每个线程持有一个小的输入向量后,就可以开始对它们进行归约了。每次归约都需要进行一次或多次完整的行扫描。
回想一下,从内存层级的顶层到低层,访问延迟逐渐增加,而带宽逐渐减少。
因此,归约策略应遵循这种硬件内存层级
一旦部分结果存留在内存金字塔的较高层级中,就立即对其进行聚合,只将经过本地归约后的值传递到下一个内存层级。
作者会按照下表从顶层到低层对值进行归约,并且每一步都只在对应的内存层级中进行加载和存储操作。
不同内存层级中的归约策略:
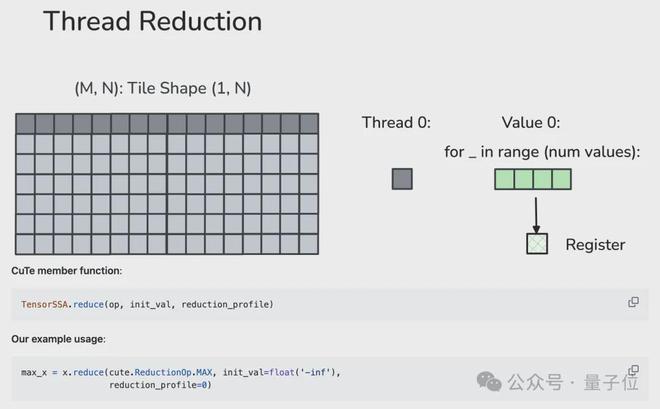
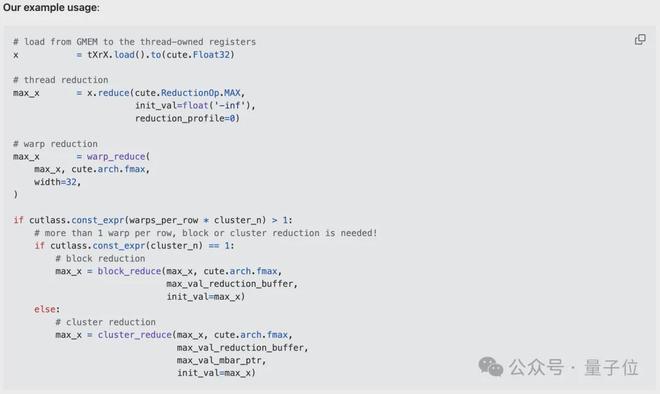
1、线程级归约(读写寄存器)
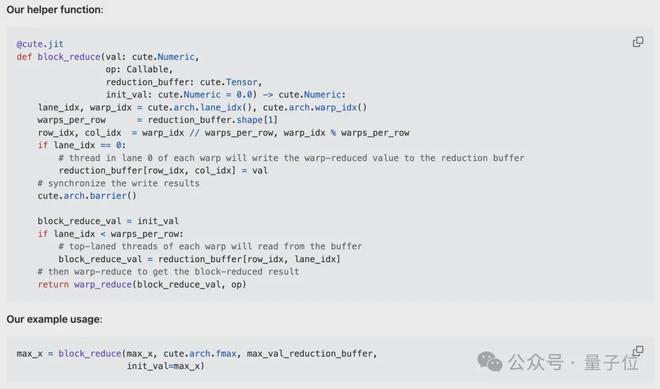
每个线程会在本地对多个向量化加载的值进行归约。作者使用 TensorSSA.reduce 函数,其中需要传入一个可结合的归约算子 op、归约前的初始值 init_val,以及归约维度 reduction_profile。
2、Warp 级归约(读写寄存器)
warp 是由 32 个连续线程组成的固定组,每周期会执行相同的指令。(同步的)warp 归约允许同一 Warp 内的每个线程通过专用的洗牌(shuffle)网络,在一个周期内读取另一个线程的寄存器。经过蝶式 warp 归约后,同一 warp 中的每个线程都会得到归约后的值。
作者定义了一个辅助函数 warp_reduce,用于以“蝶式”归约顺序执行 Warp 归约。关于 warp 级原语的详细解释,读者可参考 Yuan 和 Vinod 撰写的 CUDA 博客“Using CUDA Warp-Level Primitives”。
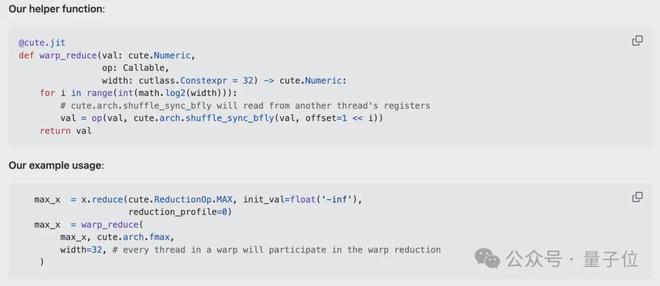
蝶式 warp 归约(Butterfly warp reduction),也称为 “xor warp shuffle”:
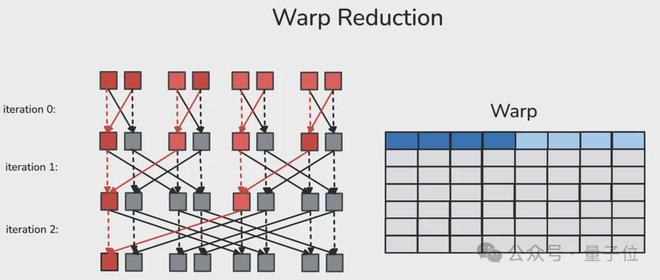
3、线程块级归约(读写共享内存)
一个线程块通常包含多个(在 H100 中最多 32 个)warp。在线程块归约中,每个参与归约的 warp 中的第一个线程会将该 warp 的归约结果写入共享内存中预先分配的归约缓冲区。
在经过线程块级同步(屏障)确保所有参与的 warp 都完成写入后,每个 warp 的首线程会从归约缓冲区中读取数据,并在本地计算出线程块的归约结果。
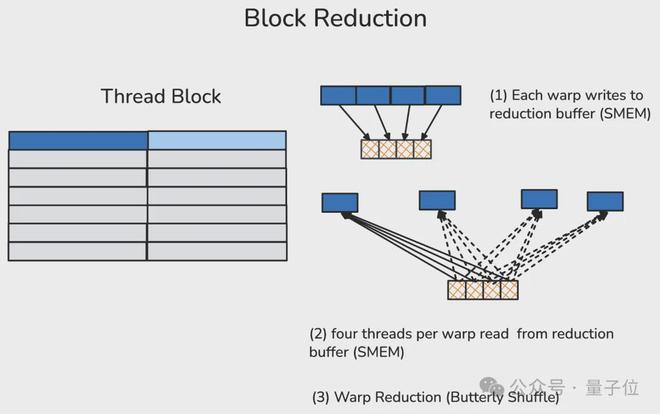
4、集群归约(读写分布式共享内存)
线程块集群是 Hopper 架构中新增的执行层级,由一组相邻的线程块(最多 16 个)组成。同一集群内的线程块通过分布式共享内存(DSMEM)进行通信,这种内存有专门的高速 SM 间网络支持。
在同一集群中,所有线程都可通过 DSMEM 访问其他 SM 的共享内存,其中共享内存的虚拟地址空间在逻辑上分布于集群内的所有线程块。DSMEM 可通过简单的指针直接访问。
分布式共享内存:
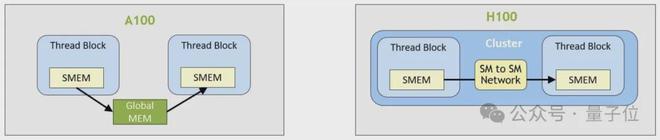
在集群归约中,作者首先把当前 warp 的归约结果通过专用的 SM 间网络(也就是 DSMEM),发送到其他对等线程块的共享内存缓冲区里。
随后,每个 warp 从其本地归约缓冲区中获取所有 warp 的值,并对这些值进行归约。
这里还得用到一个内存屏障用来统计数据到达的数量,以避免过早访问本地共享内存(否则会导致非法内存访问的错误)。
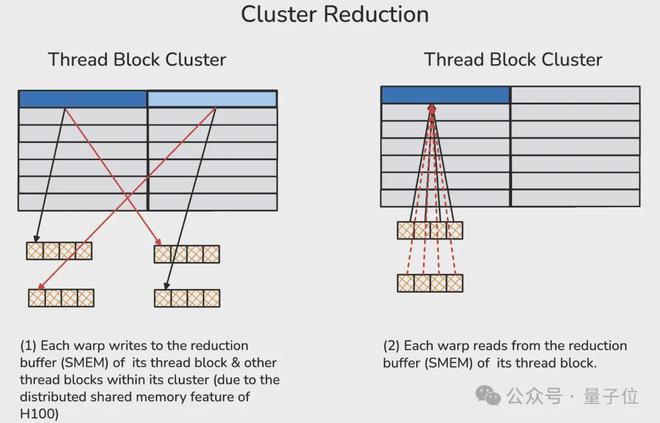

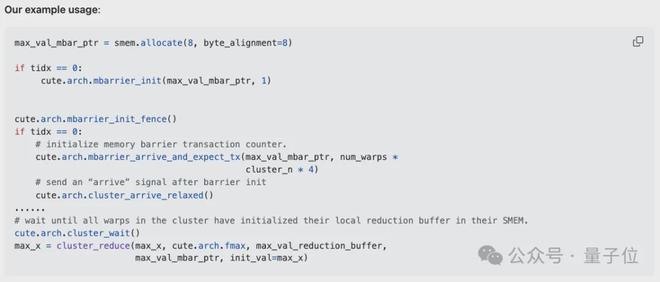
把整个归约流程串起来看:首先做线程级归约,然后在同一个 warp 内聚合线程级归约的结果(即 warp 级归约),接着根据归约维度的数量,在每个线程块或线程块集群上进一步传递归约后的值。
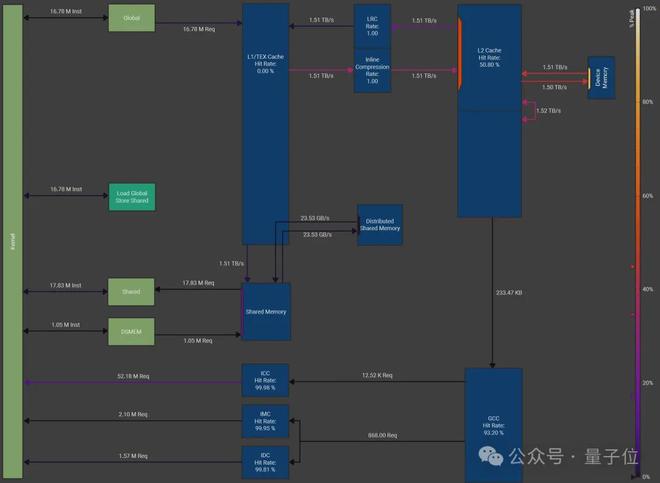
NCU 性能分析(Softmax 内核)
作者在配备 HBM3 显存(DRAM 峰值吞吐量=3.35 TB/s)的 NVIDIA H100 上,对批量维度为 16K、归约维度为 131K 的 softmax 内核做了性能测试。内存工作负载图由 Nsight Compute 生成。
配置是:线程块集群大小为4,每个线程块有 256 个线程,输入数据类型为 FP32。加载和存储操作都做了向量化处理,每条指令一次搬运 128 bits 数据(也就是 4 FP32 值)
最终测出来的DRAM 吞吐量也就是显存带宽利用率达到了 3.01TB/s,相当于 DRAM 峰值吞吐量的 89.7%。除了共享内存(SMEM)外,还高效利用了分布式共享内存(DSMEM)。
该方案的内存工作负载图:
作者还拿自己的实现与 torch.compile(PyTorch 2.7.1 版本)进行了对比。
首先,获取了 torch.compile 生成的 Triton 内核代码。
该内核实现 softmax 时包含 2 次全局内存加载(计算行最大值和部分指数和时各加载 1 次,以及最终的 softmax 值)和 1 次存储。
在这种情况下,尽管该 Triton 内核仍能使硬件的 DRAM 吞吐量跑满,但额外的 1 次不必要加载会导致 Triton 内核的有效模型内存吞吐量(约 2.0 TB/s)仅为本文作者实现方案的三分之二(约 3.0 TB/s)
torch.compile 生成的 Triton 内核(调优配置部分省略)
内存吞吐量
作者对 RMSNorm、softmax 和交叉熵损失这几个内核做了基准测试。测试仍在配备 HBM3 显存的 1 块 NVIDIA H100 80GB GPU 和 Intel Xeon Platinum 8468 CPU 上进行。
测试中使用的批量大小范围为 8k-32k,归约维度范围为 256-262k(256×1024),输入数据类型为 FP32 和 BF16。
基准对比方案如下:
- Torch.compile(PyTorch 2.7.1 版本):使用默认编译模式。
- Liger 内核 v0.5.10 版本 :只测了 RMSNorm 和 softmax,且归约维度最多到 65k(因为它目前不支持更大的维度)。
- cuDNN v9.10.1 版本:只测了 RMSNorm 内核。
作者基于 CuTe DSL 的实现方案,在归约维度大于 4k 时,内存吞吐量一般能稳定在 3TB/s左右(差不多是峰值的 90%)
归约维度 262k 时,FP32 的 softmax 吞吐量能到 3.01TB/s,而 torch.compile 只有 1.89TB/s,快了近 50%。对于这 3 个内核,当归约维度≥65k 时,该实现方案显著优于所有基准对比方案。
多个内核的模型内存吞吐量:
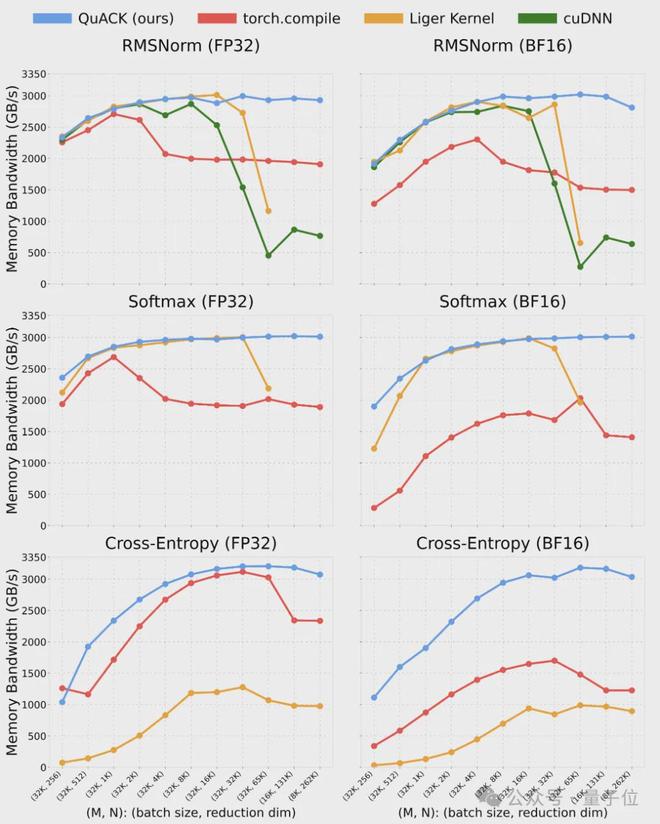
作者认为,在输入规模≥65k 时的优异性能得益于成功利用了 H100 中的集群归约
当输入数据量大到把 SM 的寄存器和共享内存都占满时,如果不用集群归约,就只能换成在线算法(比如在线 softmax);不然的话,寄存器里的数据会大量“溢出”,导致吞吐量显著下降。
举个例子,作者观察到,当使用 Liger softmax 内核时,输入规模从 32k 涨到 65k,吞吐量就从约 3.0 TB/s掉到了 2.0 TB/s左右。
作者用 NCU(Nsight Compute)工具分析了它的内存负载图和 SASS 代码,发现当每个 SM 要加载 65k 数据时,SM 的资源被耗尽,结果就是大量寄存器溢出,还会频繁往 HBM 里回写数据,这才拖慢了速度。
Liger softmax 内核在批量维度为 16k、归约维度为 65k 且数据类型为 FP32 时的内存工作负载:
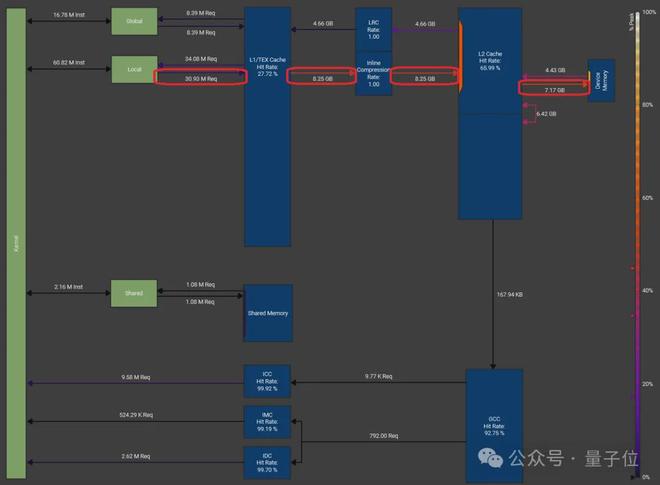
Liger softmax 内核汇编代码中的寄存器溢出(LDL 指令):

但集群归约能让多个 SM 协同工作,共享各自的资源,相当于组成一个“超级”SM(靠 DSMEM 实现)。
假设单个 SM 仅能处理 32k 输入,那么一个大小为 16 的集群将允许处理 50 万(0.5M)输入,而无需从全局内存(GMEM)重新加载数据。
由于作者对硬件知识有清晰的理解,即使使用常规的 3 遍扫描 softmax 算法,也能轻松充分利用所有内存层级的每一个字节,实现“光速”级别的吞吐量。
总结
作者通过实践证明,只要精心手工编写 CuTe 内核,就能把硬件里所有内存层级的潜力都榨干,实现“光速”级别的内存吞吐量。
但这种效率是以针对每个算子甚至每个输入形状进行调优为代价的,这自然在效率与开发成本之间形成了一种权衡。
Phil Tillet(Triton 的作者)在他的演讲中用这张图很好地阐述了这一点。
根据作者使用 CuTe-DSL 的经验,它既具备 Python 的开发效率,又拥有 CUDA C++ 的控制能力和性能。
作者认为,高效的 GPU 内核开发流程是可以自动化的。
例如,RMSNorm 中的输入张量 TV 布局、加载/存储策略以及归约辅助函数,可直接应用于 softmax 内核并仍能达到相近的吞吐量。
此外,CuTe DSL 将为开发者或基于 CuTe DSL 运行的其他代码生成应用提供灵活的 GPU 内核开发能力。
- 目前,将大语言模型应用于自动生成 GPU 内核是一个活跃的研究方向,未来,或许只需调用“LLM.compile” 就能生成高度优化的 GPU 内核。
作者简介
这项工作作者有三位。
Wentao Guo
Wentao Guo 目前是普林斯顿大学计算机科学专业的博士生,师从 Tri Dao。
在这之前,他在康奈尔大学获得了计算机科学的本科和硕士学位。
Ted Zadouri
Ted Zadouri 同样是普林斯顿大学计算机科学专业的博士生,本硕分别读自加州大学欧文分校、加州大学洛杉矶分校
此前 Ted Zadouri 曾在英特尔实习,也曾在 Cohere 研究大语言模型的参数高效微调。

Tri Dao
Tri Dao 目前是普林斯顿大学计算机科学助理教授,还是生成式 AI 初创公司 Together AI 的首席科学家。
他因提出一系列优化 Transformer 模型注意力机制的工作而闻名学界。
其中最有影响力的,是其作为作者之一提出了 Mamba 架构,这一架构在语言、音频和基因组学等多种模态中都达到了 SOTA 性能。
尤其在语言建模方面,无论是预训练还是下游评估,Mamba-3B 模型都优于同等规模的 Transformer 模型,并能与两倍于其规模的 Transformer 模型相媲美。
另外他还参与发表了 FlashAttention1-3 版本,FlashAttention 被广泛用于加速 Transformers,已经使注意力速度提高了4-8 倍。
GitHub 链接:https://github.com/Dao-AILab/quack/blob/main/media/2025-07-10-membound-sol.md






