
作者 | 周一笑、董道力、Yoky
没有预热,也没有发布会,月之暗面在 2025 年 7 月 11 日深夜选择直接开源 Kimi K2 。就在当天,Kimi K2 模型悄无声息地出现在 Hugging Face 上,官网、App 和 API 同步开放,模型参数、训练细节等信息也一并放出 。
这次发布的 Kimi K2 是一个万亿(1T)参数规模的混合专家(MoE)模型,激活参数为 320 亿 。其核心能力发生了清晰的转向,Kimi 此前的标签是长文本,而 K2 则为智能体任务(agentic tasks)做了专门优化。
官方展示的例子很能说明问题,比如 Kimi K2 可以接收一个模糊的需求,通过 17 次工具调用,自主完成包含航班和酒店预订的旅行规划 ;或是执行 16 次数据分析指令,完成一份专业的薪资分析报告。
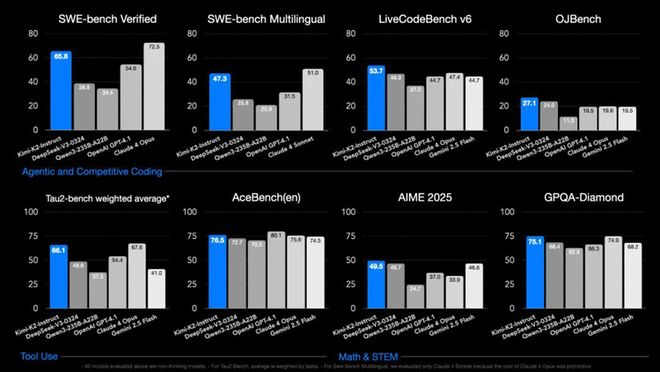
在榜单方面,它在 SWE Bench Verified(编程)、Tau2(智能体)、AceBench(工具调用)这三项基准测试中是开源模型表现最好的。
在自主编程(Agentic Coding)、工具调用(Tool Use)和数学推理(Math & Reasoning)这三个能力维度上,Kimi K2 也紧逼 Claude 4 Opus、OpenAI GPT-4.1 等闭源模型。
月之暗面此次开源了两个版本,一个是适合做后续研究和定制化开发的 Kimi-K2-Base 基础模型,另一个是能直接用于通用聊天和智能体场景的 Kimi-K2-Instruct 指令微调模型 。
任何模型都有它的取舍和待解问题。那个以超长上下文能力深入人心的 Kimi,这次在 K2 上只配置了 128K 的窗口虽然以及对表主流模型,但这背后很可能是在当前阶段,优先将资源投入到提升模型的代码和 Agent 能力上。
另一个现实问题是运行门槛。官方部署指南明确指出,在主流 H200 等平台上运行 Kimi-K2 的 FP8 版本并支持 128k 上下文,最小硬件需求是一个由 16 块 GPU 组成的集群 。尽管模型在 vLLM、SGLang 等主流推理框架上提供了详细的部署方案,并支持张量并行、专家并行等多种策略来适配不同规模的集群 ,但这个基础的硬件门槛,已将绝大多数个人开发者和中小团队排除在本地化部署之外。这种对大规模、高I/O性能集群的依赖,是其强大能力背后普通用户难以企及的成本。
一些开发者已经在自己尝试把它跑在 2 个苹果 M3 芯片的环境里,并表示运转良好。但要提供更好的本地和低资源环境的可用性,还需要 Kimi 官方的量化版本。
Kimi K2 的发布,是杨植麟在给月之暗面调整方向后,交出的一份重要答卷。
DeepSeek 出现证明了开源的价值以及底层模型能力依然是竞争的基石,它甚至会“摧毁”在模型单一能力上优化并用在c端产品里然后快速推广的竞争策略。
之后 Kimi 开始在技术上全线转向预训练,并步步紧跟 DeepSeek。2025 年 2 月,两家几乎同时发表论文,挑战 Transformer 的注意力效率问题,DeepSeek 提出了 NSA(原生稀疏注意力)架构,月之暗面则提出了 MoBA(混合块注意力)架构。两者都试图解决模型处理长文本时的效率瓶颈。清华大学教授章明星曾对此评论,这说明两家顶尖团队对技术演进的方向得出了相似的结论 。但这次 K2 在文本长度上一般,似乎还没把 MoBA 彻底用上。
另外,与 MiniMax 等对手的做法不太相同的地方在于,Kimi 此次的开源模型,架构上选择了 DeepSeek 开发和依赖的 MLA(多头潜在注意力),目前技术报告还没发布,从 Hugging Face 的信息来看,Kimi K2 用了结构类似 DeepSeek V3 的 MLA,专家数增加到了 384 个,激活专家保持在 8 个。
在优化器上 Kimi 此前的工作也成了此次模型关键。要训练万亿模型,通用的 AdamW 优化器已面临挑战。Kimi 此前选择了在更新的 Muon 优化器上深度投入 ,并针对大规模训练中的不稳定性,提出了 MuonClip 技术,最终支撑了 K2 在 15.5 万亿 token 数据量下的平稳训练。
这些技术投入背后还有一个清晰的技术赌注:“模型即 Agent,Agent 即模型”的理念。
在 K2 发布前,月之暗面就通过 Kimi-Researcher 产品展示了其对智能体的理解——追求一种“零结构”的智能体,不依赖人类预设流程,而是通过端到端的强化学习,让模型在真实的任务反馈中自主学习如何思考、规划和使用工具 。为了实现这一点,Kimi K2 在可验证任务(如代码和数学)上进行强化学习的同时,还通过引入“自我评价(self-judging)”机制,解决了在开放性、非验证类任务上的奖励稀缺问题,从而提升了模型的泛化表现。
将这些线索串联起来看,Kimi K2 的开源更像是杨植麟给 Kimi 重新定位后交出的第一个答卷。其实看看这一路的各种动作,会发现这个团队一直有一个明显的特征,他们在技术上还是想争一口气,这体现在他们总会有一个自己的“赌注”,此前是长文本,今天就是 Agent,然后围绕一个点,做取舍,押注,交卷。
实测 K2,瞄准 Anthropic 的 Agent 能力
此次 Kimi 选择先全线上线给用户使用的策略,我们也第一时间上手测了测它的实际能力。
首先是一个“打字游戏”。
我们在 cline 上接入 kimi k2 模型,并尝试复现一个中文版打字游戏。
prompts:做一个“打字”游戏,页面上跳出来一句话,用户需要在规定时间内,把这句话打出来。



我们在 prompts 中只简单描述了一下游戏玩法,而 kimi k2 自动生成了“需求分析”和“技术方案”,并且针对游戏功能还进行了补充,如进度条、得分系统等。在游戏生成后,kimi k2 写了一份简单的游戏介绍,包含了操作说明和游戏特点。
而且,kimi k2 的打字游戏一次生成完成度就很高,可以直接运行,基本没有 bug。
项目网址:https://ddlpmj.github.io/pw_kimik2_test/
此外,浏览网页获取信息并作出规划,也是 Agent 的重要能力体现之一。
prompts:我喜欢音乐节,我希望你可以帮我找一下今年各大音乐节的名称、行程等,做成日历清单,并以 html 的形式整理出来。
我们尝试让 kimi k2 帮我们做一份“音乐节日历清单”,并以网页的形式展现出来。和打字游戏一样,kimi k2 除了 prompts 中的要求,还像个助理一样,补充了音乐节的其他信息,如地点、是否确认举办等。
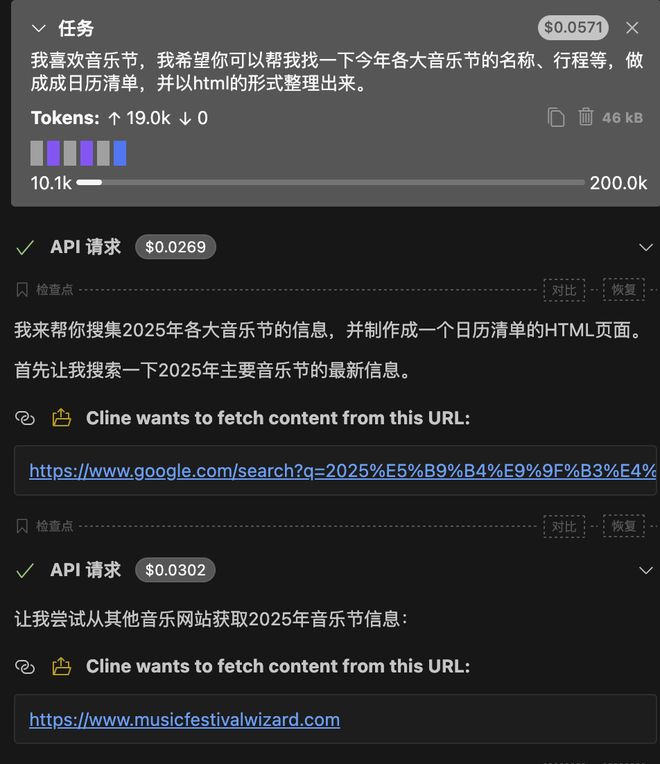

在成品页面设计中,kimi k2 还做了规划,如1-3 月举行的音乐节在同一页面展示,4-6 月的在另一页面展示。鼠标移动到具体的音乐节上,还会有放大的特效。
能否取得大量数据,并从中做出洞察也是我们考验的能力之一。我们下载了近 5 年的上上证指数数据,共 1214 条,交给 kimi k2 进行分析。
prompts:@/000001perf.xlsx 这是一份上证指数数据,分析数据并做一份分析报告,报告中要包含图表
可以发现,kimi k2 决定用 python 进行报告生成,为了读取表格文件和生成图表,它会自动检查有没有 pyhton 相对应的库,并进行下载。
在指标上,kimi k2 会自动挑选有代表性的进行分析,如最高/低日成交额,数据波动等。
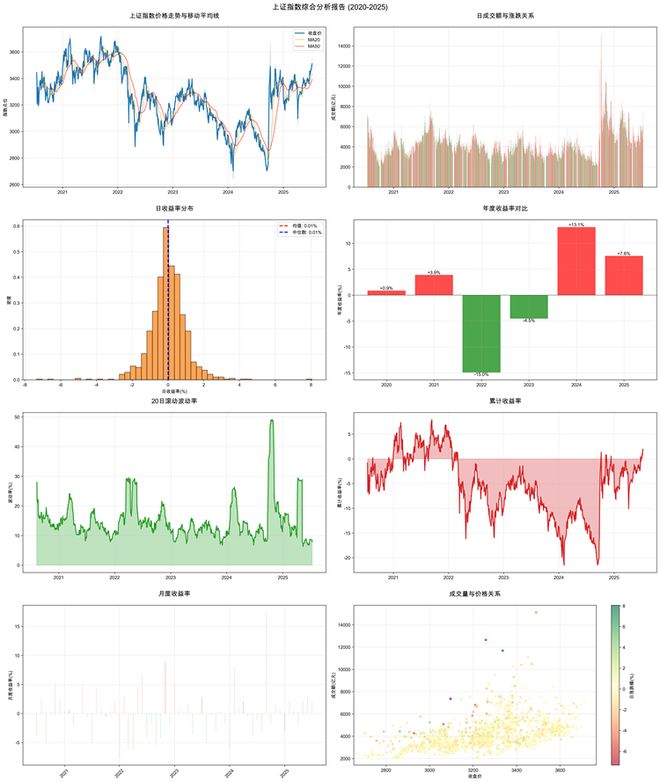
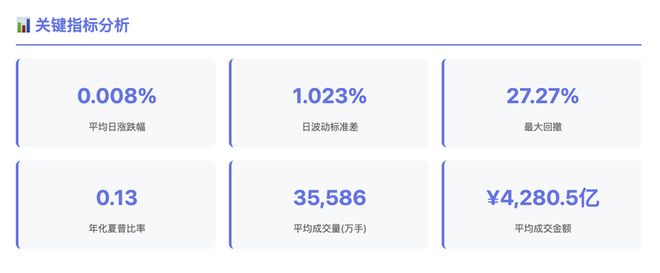
从分析报告成品来看,kimi k2 先生成图表,后生成分析报告,最后将二者结合,逻辑比较顺畅。此外,kimi k2 生成的图表形式多样,趋势线、热力散点图等都有。
并且 kimi k2 基本找出了上证指数的特点。
为了测试 K2 的风格化文本生成能力,我们选择了一个具有挑战性的任务:让它模仿知名脱口秀演员付航的表演风格,创作一段 300 字的脱口秀段子。
测试结果显示,K2 确实展现出了一定的风格模仿能力。从表面看,生成的文本在语言节奏和表达方式上有那么几分相似,但仔细分析后发现,它并没有真正捕捉到付航段子的核心特质。

初次生成的内容存在明显的逻辑混乱问题,读起来让人摸不着头脑,甚至难以理解基本的表达意图。经过参数调整和 prompt 优化后,第二次的输出在可理解性方面有了显著提升,至少能够清晰地传达想要表达的内容,但依旧不好笑。

不过值得注意的是,K2 在最近的升级中展现出了一个有趣的变化趋势。它的文本表达风格明显向 R1 靠拢,开始频繁使用一些颇为华丽的比喻和相对复杂的措辞。这很可能也跟 Kimi K2 在训练中对合成数据的使用有关。
更多的细节等待它的官方技术报告来揭秘。
在 Kimi 的英文技术博客里,它也直接取名:Kimi K2: Open Agentic Intelligence。在此之前,Anthropic 的 Claude 是把自己和 Agent 能力捆绑最紧密的模型系列,并且也同样在聚焦 Agent 能力同时没有太多去提高多模态等能力。此次 K2 对标 Claude 的思路很明显,在模型能力上也做了很明显的取舍。
根据 Kimi 透露,K2 现在已具备复杂指令集解析能力,可以兼容 Anthropic 等的 API 接口,可以无缝接入 Cline,owl 等 Agent 框架。在社区里,各种对 K2 的实测也纷纷出现。其中不少开发者也表达了对实测上手 K2 在 Agent 能力上的惊艳。甚至已经有人“开发”出把 Claude Code 里的 Claude 模型替换成 Kimi K2 的方法,并且表示可以用来平替。
接下来可能可以期待 Kimi 的产品上,也会像 Claude 那样衍生出更多功能,预训练模型的进展最终真正“反哺”到它C端产品上,然后 Make Kimi great again。






