
新智元报道
编辑:海狸
别自欺欺人了!METR 重磅实测揭穿 AI 编程真相:GPT 等工具让顶尖程序员写代码平均慢了整整 19%!效率不升反降、体验爽感成了错觉安慰剂?开发现场变「高科技马车」,AI 正在拖垮真正的高手!
每天来到工位,打开昨天没跑通的代码,
抿一口咖啡,指挥 Cursor、GPT、Gemini、Deepseek...吭哧吭哧干活。

AI 进化成编程怪物后,这或许是很多程序员/科研人的日常。
但是,用了 AI,写代码一定更快了吗?
METR(Model Evaluation & Threat Research)研究发现,如果你够强、对代码库够熟悉,AI 工具反而会给你拖后腿!

他们进行了一系列严谨的随机对照试验(RCT),结果惊人——
哪怕是写过百万行代码的万星 repo 大佬,使用 AI 工具时,干同样的任务,也会多花「19%」的时间!
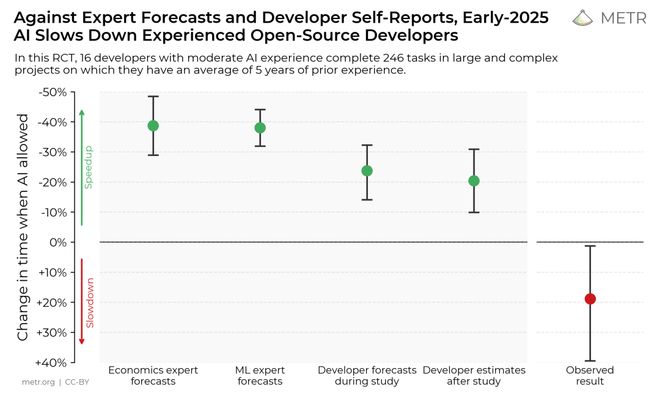
更令人「细思恐极」的是,开发者完全意识不到 AI 在拖他们的后腿!
实验前,他们平均预计 AI 能提升效率 24%。
即便在明明白白看到「变慢」的实验结果后,他们还是认为 AI 让他们快了 20%。
METR 把所有的实验设计和结果都放在了论文中:

论文链接:https://metr.org/Early_2025_AI_Experienced_OS_Devs_Study.pdf
这项研究是怎么颠覆我们对 AI 写代码的幻想的?
「变快」是幻觉:AI让开发者慢了 19%
具体而言,METR 把研究限制在了「资深开发者」和他们熟悉的「大型、成熟开源代码库」这个范围里。
为了测量 AI 工具在现实中的开发影响,METR 招募了 16 位长期活跃于大型开源项目的资深开发者。
「资深」二字可不是说说而已,他们人均 100 万+行代码,维护的 GitHub 项目有 22k+ 颗星。
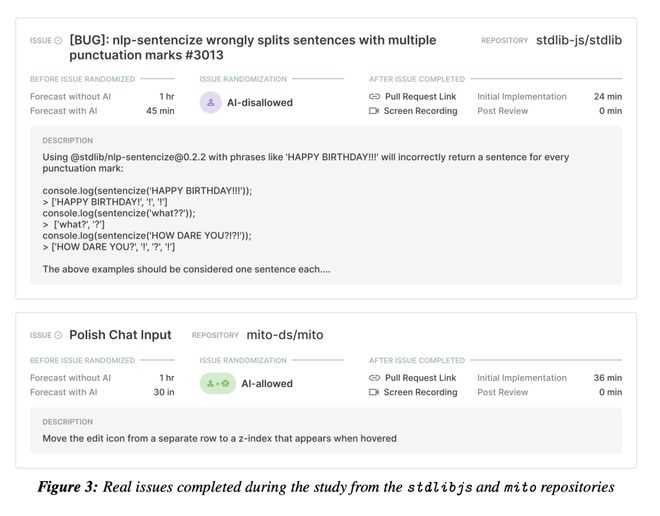
这些开发者真刀真枪上阵,从他们日常工作流中收集了 246 个真实有价值的问题。
这些问题包括 bug 修复、新功能开发和重构任务等,大概长下面这样
METR 将每个任务随机分配「允许使用 AI」或「不允许使用 AI」的对照实验组中。
在「允许」组中,开发者可以使用任何 AI 工具(主要是 Cursor Pro 搭配 Claude 3.5/3.7 Sonnet 等前沿模型)。
在「不允许」组中,他们不得借助生成式 AI。
实验选择的每个任务平均耗时 2 小时。完成任务的同时,开发者需要录屏,并自报所用总时间。
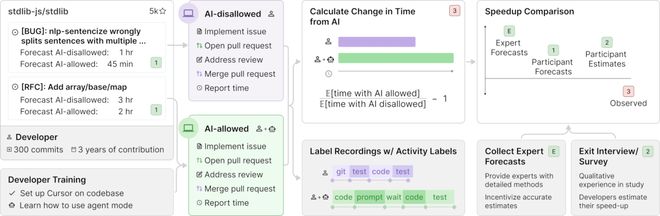
随后,METR 计算一个相对变化率,来衡量用不用 AI 的时间影响。
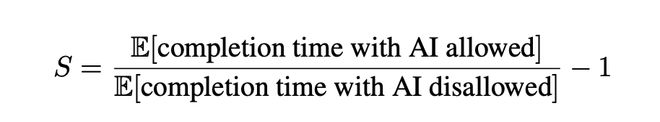
不过,开发者们也不白干活,METR 按每小时 150 美元给他们付「工资」。
这笔高时薪开得很值,METR 分析实验结果后发现了惊人的结论:
当开发者可以使用 AI 工具时,他们完成任务的平均时间反而增长了 19%!
而且,从下图可以看出,使用 AI 写代码,全流程都被拖慢了!
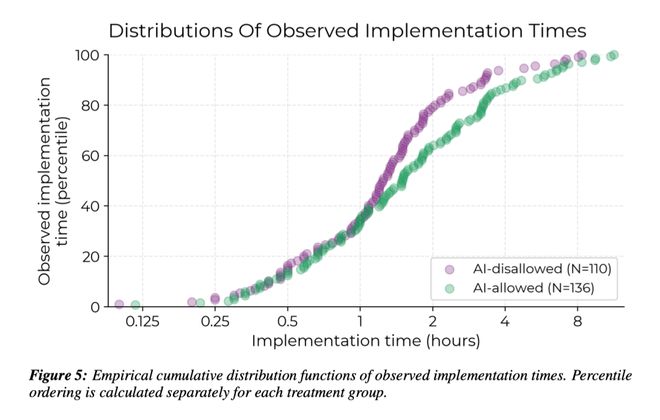
这么明显的变慢打破了所有人的预期。
更令人震惊的是,开发者完全感觉不到!
在实验前,他们预计 AI 能提升效率 24%;但从下图可以清晰看出,使用 AI 后,开发者用时显著增加。
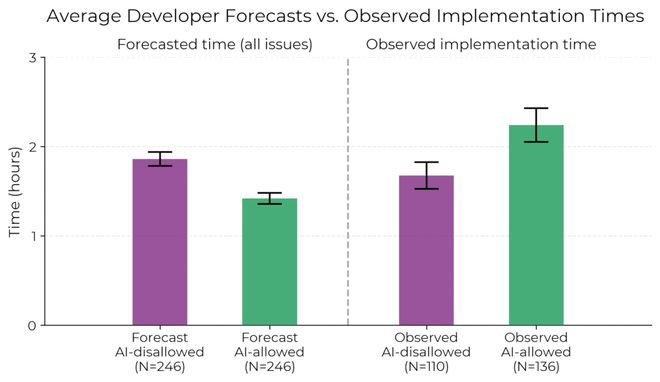
然而,即便在亲身体验「变慢」后,他们仍认为 AI「感觉上」让他们快了 20%!
不过,METR 非常严谨,声明实验仅研究特定开发者与项目,不代表整个软件开发行业,更不能推广到非软件类任务(如法律、写作、设计等)。
基准测试、用户体验,都错哪了?
为确保严谨,METR 反复审查了自己的实验设计。
他们严格遵守实验分配规则,没有在 AI 组更频繁放弃难题,使用的 AI 也确实都是最强代码模型。
并且,有 AI 和无 AI 组提交的 PR(Push Request)质量也没什么大差别。
既然实验设计没问题,那在 AI 写代码这件事上,为何 benchmark 和用户体验都错了?
METR 对实验结果进行了进一步的分析。
首先是更细粒度的思考过程分析:
细细看了这些大佬开发者的屏幕录像后,METR 发现,允许使用 AI 时,开发者在主动编码以及搜索/阅读信息上的时间减少了。
相对应的,开发者将更多时间花在了与 AI 交互(如编写提示)、审查 AI 输出的结果,以及「干等」上。
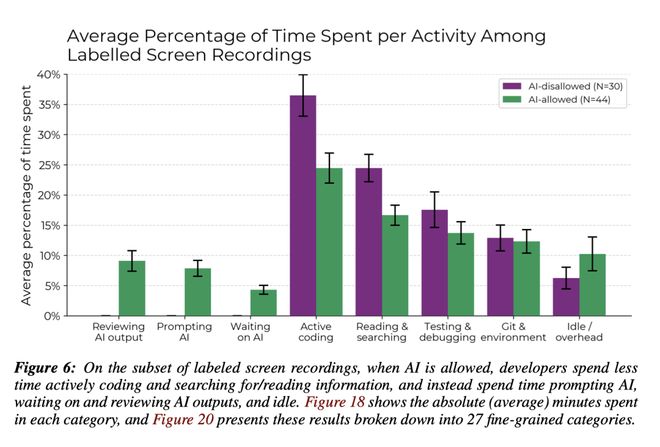
METR 进一步设想了 20 个可能导致变慢的因素,发现其中有 5 个可能对结果有显著贡献:
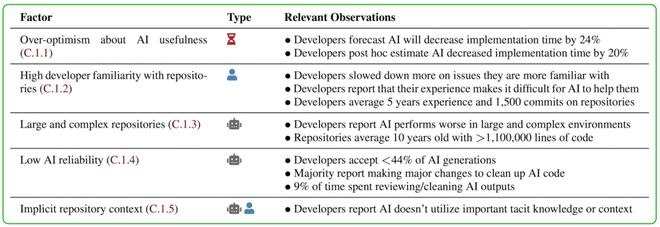
一方面,开发者对项目已经非常熟悉,远超和团队没有默契的 AI;另一方面,他们对 AI 效能有点过度乐观。
另外,项目本身也很复杂,导致 AI 写得快但写得烂,开发者还要花很多时间调试。
最后,METR 发现,这项研究与此前观点的矛盾似乎来源于任务的定义和区分。
对 AI 是否「能干活」这一问题,数据来源不同,得出的结论可能完全不同。
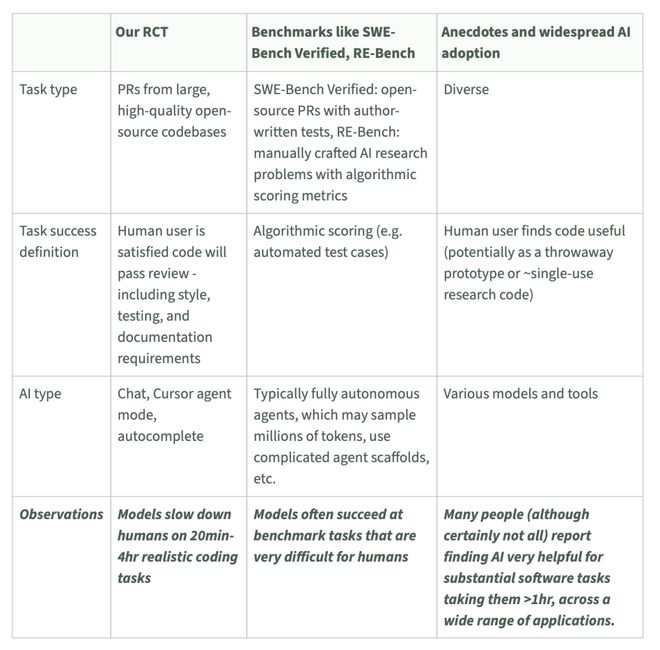
RCT 实验聚焦的是「现实开发流程中是否真的更快」,基准测试关心「模型在任务标准下能打几分」,而用户主要反馈「AI 用起来爽不爽」的主观感受。
换句话说,结论不一样,是因为本就在回答不同问题。
关心的是「日常提效」,还是「攻坚能力」,换换使用场景,答案可能完全不同。
每一种方法评估的都只是任务空间的子集,组合起来,或许才能客观认识 AI 编程的真实战力。
上岗两眼懵?AI 编程不能只会刷分
METR 的 RCT 实验提醒我们,别被 AI 基准测试的高分吓到了。
那些所谓的「智能体测评」「编程大赛」,看起来挺能打,实则可能离真实开发差得远。
在不需要背景、不需要理解上下文、不涉及实际部署的测试任务中训出来的 AI,未必能赶上人类开发者的表现;
我们不能低估 AI 的能力,更不能过度乐观,觉得 AI 能轻松接管开发。
未来,用户对 AI 编程工具的期待不只是「刷分」。
我们想看的是,AI 是否真的能把软件开发推进得更快、更好?
一旦 AI 真能做到这一点,那就意味着 AI 能够「无限赋能」自身的进化。
听起来很酷,但也任重道远。
如何评估 AI 参与真实开发部署的能力?如何设立监督护城河,保证项目安全?
METR 打算继续设计实验,观察 AI 开发的真实实力。
他们表示,想要集结更多开发者、AI 编程用户的力量,一起继续搞实验,看 AI 到底行不行。
不过,不管 AI 编程拖后腿的证据有多「实锤」,
研究中的大多数参与者,甚至研究作者本人,都并不介意被 GPT 之流拖一拖后腿。
面对一张白纸从零开始,或是对着一篇草稿进行编辑,即使前者更快,大家想必也都会选择后者。
毕竟,「奴役」AI 写代码,虽然没法更「快了」,但一定更「快乐」。
参考资料:
https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/






