
新智元报道
编辑:海狸好困
最近,Ai2 耶鲁 NYU 联合推出了一个科研版「Chatbot Arena」——SciArena。全球 23 款顶尖大模型火拼真实科研任务,OpenAI o3 领跑全场,DeepSeek 紧追 Gemini 挤入前四!不过从结果来看,要猜中科研人的偏好,自动评估系统远未及格。
如今,用 AI 大模型辅助写论文早已成为科研工作者的家常便饭。
ZIPDO 2025 教育报告显示,AI 已经无缝融入 70% 的研究实验室,并在五年内推动相关科研论文数量增长了 150%。

AI 在辅助科研的路上一路狂飙,但一个关键问题却长期悬而未解:
「大模型科研能力究竟怎么样?」
传统 benchmark 静态且片面,难以衡量科研任务所需的上下文理解与推理能力。
为此,Ai2 联合耶鲁大学和纽约大学推出了科研界的 Chatbot Arena——SciArena,正式开启科学智能的「擂台赛」时代!

论文链接:https://arxiv.org/pdf/2507.01001
目前,已有 23 个最前沿的大语言模型登上 SciArena 的擂台,涵盖 OpenAI、Anthropic、DeepSeek、Google 等巨头产品。
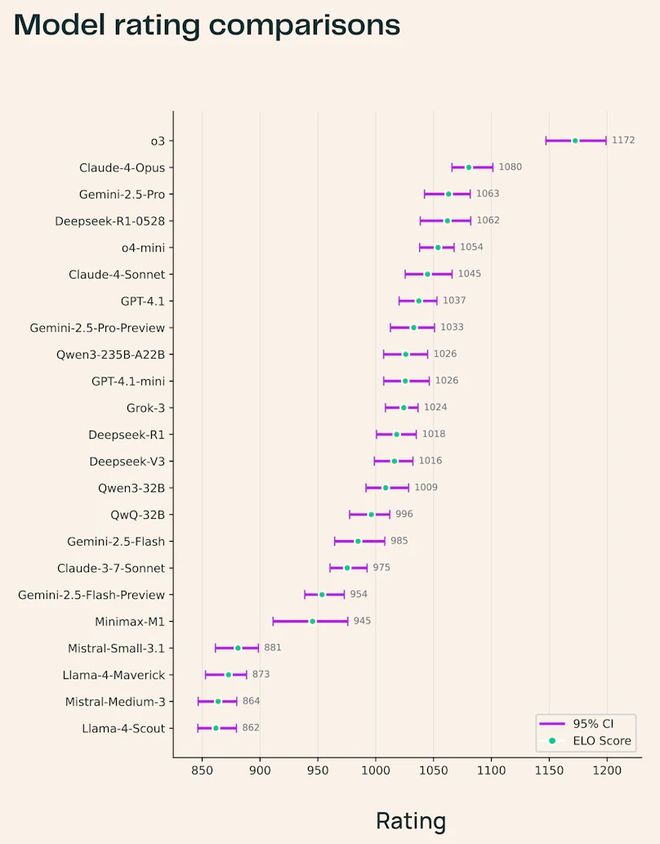
其中,OpenAI o3 断崖式领先,坐上了科学任务的头把交椅,在所有科学领域都稳居第一,输出的论文讲解也更有技术含量。
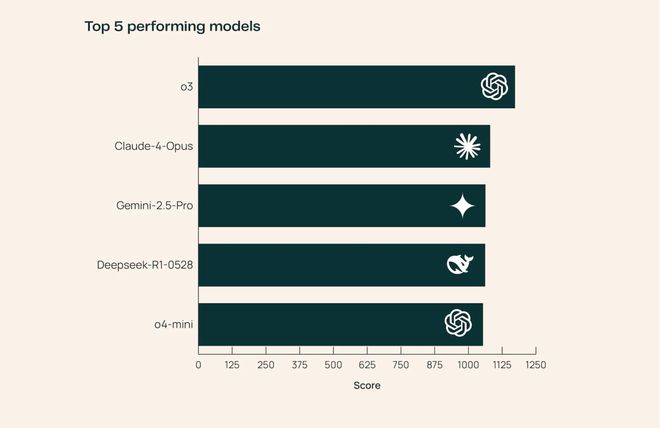
其他模型在不同领域各有千秋:
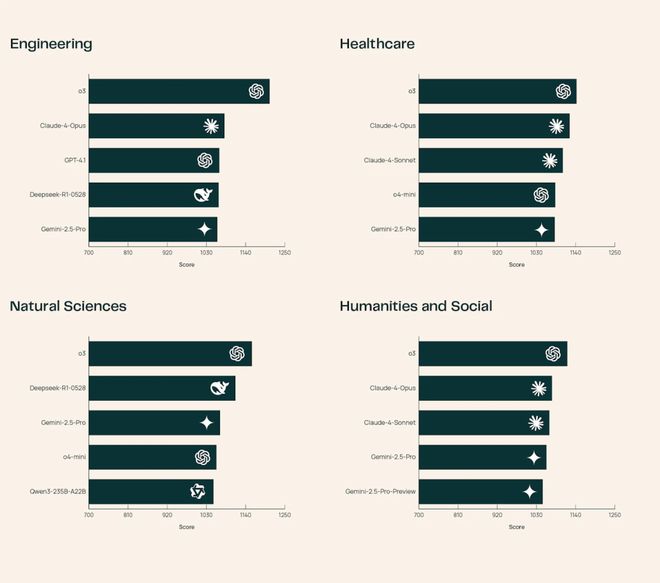
例如 Claude-4-Opus 的医疗健康知识很强,而 DeepSeek-R1-0528 在自然科学表现抢眼。
值得一提的是,SciArena 刚发布没多久就得到了 Nature 的特别报道,并被盛赞为「解释大模型知识结构的新窗口」。

下面我们就来看看,评估基础模型科研能力,SciArena 究竟靠谱在哪里?
SciArena:科研 AI 新「试金石」
SciArena 是首个专为科学文献任务量身定制的大模型「开放式评估平台」。
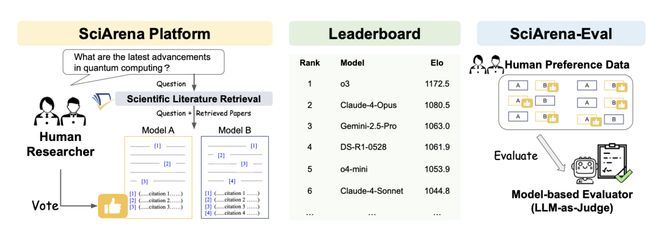
在这里,科研人员可以对不同基础模型处理科学文献任务的表现进行比较和投票。
团队引入了 Chatbot Arena 式的众包、匿名、双盲对决机制,用真实科研问题来验货大模型。
SciArena 专门针对科学探究的复杂性与开放性进行了优化,解决通用基准测试在科研场景中「失效」的问题。
该平台主要由三大核心组件构成:
-
SciArena 平台: 科研人员在此提交问题,并「同台对比」查看不同基础模型的回复,选出自己更偏好的输出。
-
排行榜: 平台采用 Elo 评分系统对各大模型进行动态排名,从而提供一份实时更新的性能评估报告。
-
SciArena-Eval: 基于 SciArena 平台收集的人类偏好数据构建的元评估基准集,其核心目标是检验用模型来猜测人类偏好的准确性。
对决背后:评测机制大揭秘
从提问到投票:SciArena 评估全流程
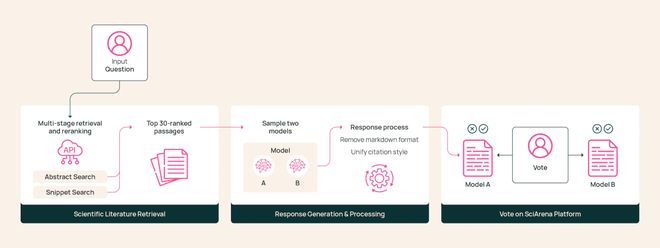
SciArena 的工作流程包括检索论文、调用模型回复、用户评估三个环节。
与通用问答相比,科研问答最大的壁垒在于要以严谨的科学文献为依据。
为了确保检索信息的质量与相关性,团队改编了 Allen Institute for AI 的 Scholar QA 系统,搭建了一套先进的多阶段检索流水线。
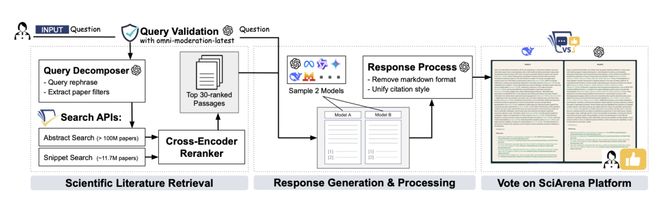
该流水线包含查询分解、段落检索和结果重排序等多个步骤。
收到用户提交的问题后,平台启用流水线,检索相关的科学论文作为上下文。
随后,平台把上下文和用户的问题合在一起,同时发送给两个随机选择的基础模型。
两个模型各自生成内容详实、附带标准引文的长篇回复。
平台会统一处理两份回复,变成格式一致的标准化纯文本,以免用户「认出」模型的回答风格。
最后,用户对这两个纯文本输出进行评估,并投票选出自己偏好的答案。
值得注意的是,SciArena 的注意力主要集中于可横向评估的「通用基础模型」。
至于 OpenAI Deep Research 等定制型智能体或闭源研究系统,则不在平台的考虑范畴内。
102 位专家,13000 票
要想评测准,数据必须信得过。
SciArena 团队对数据的把关严格得令人发指。
在平台上线的前四个月里,他们收集了不同科研领域的 102 位专家的 13000 多次投票。

这 102 位专家绝非随意参与的路人,而是科研一线的在读研究生,人均手握两篇以上论文。
而且,所有的标注员都接受了一小时的线上培训,确保评价标准一致。
再加上盲评盲选机制,SciArena 的每一条评估结果都有据可依。
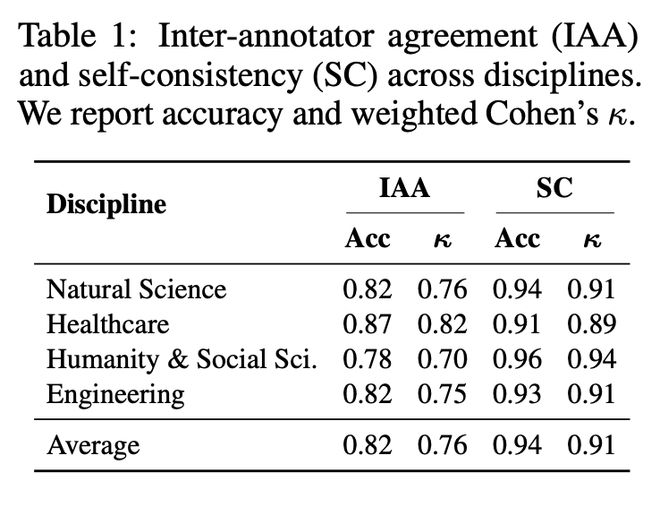
在 SciArena 的高标准和严要求下,平台的标注数据自我一致性极高(加权科恩系数κ=0.91),标注者间一致性也达到了较高水平(κ=0.76)。
这 13000 多次投票为 SciArena 平台打下了值得信赖的评估基础。
最强 AI,猜不透科研人的心
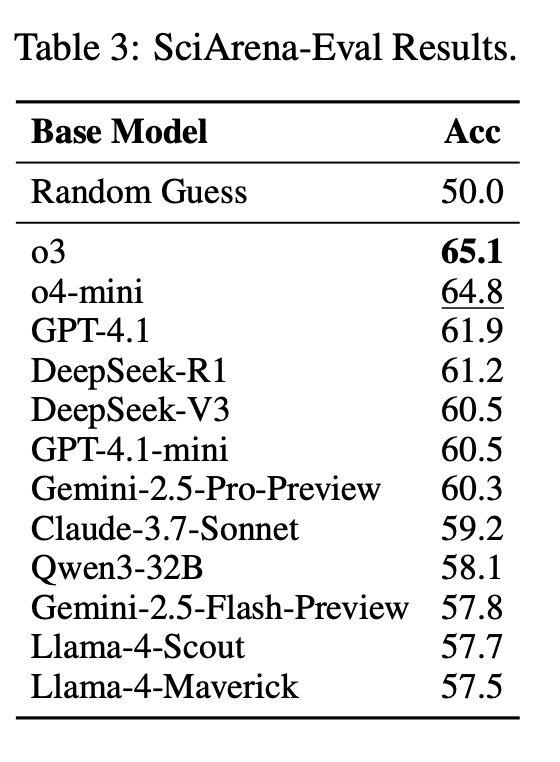
在 SciArena 平台上,研究团队基于元评估基本集 SciArena-Eval,测试了「模型评模型」的自动评估方法:
给一个评估模型一条科研问题和两个模型的回答,让它猜哪个更可能被人类选中。
结果很扎心。
哪怕是表现最好的 o3 模型,准确率也只有65. 1%,而像 Gemini-2.5-Flash 和 LLaMA-4 系列,几乎跟「掷硬币选答案」的准确率差不多。
对比一下通用领域,像 AlpacaEval、WildChat 这些基准的评估模型,准确率都能跑到 70% 以上,相比之下,科研任务显得难多了。
看来,「让模型理解科研人的偏好」并非易事。
不过也不是全无亮点。
加入了推理能力的模型,在判断答案优劣上普遍表现更好。
例如,o4-mini 比 GPT-4.1 高出 2.9%,DeepSeek-R1 也小胜自家模型 DeepSeek-V3。
这说明,会推理的 AI 更懂科研问题的本质。
研究团队表示,SciArena-Eval 未来有望成为科研 AI 评估的「新标准」。
它能帮我们看清 AI 到底有没有真正「读懂」科研人的心思。
参考资料:
https://allenai.org/blog/sciarena
https://arxiv.org/pdf/2507.01001
https://the-decoder.com/sciarena-lets-scientists-compare-llms-on-real-research-questions/






