
德克萨斯大学西南医学中心团队投稿发自凹非寺
量子位 | 公众号 QbitAI
医疗 AI 场景复杂,需要“又懂医疗又懂编程”的 agent。
但像 GPT 这样现成的大模型难以直接部署,该如何突破技术壁垒?
答案是:打造一个统一的训练平台,专门训练能够生成医疗代码的大模型。
最近,来自埃默里大学、佐治亚理工学院、耶鲁大学和德克萨斯大学西南医学中心的研究团队,发布了全球首个专注于医疗代码生成的大模型训练平台——MedAgentGym。
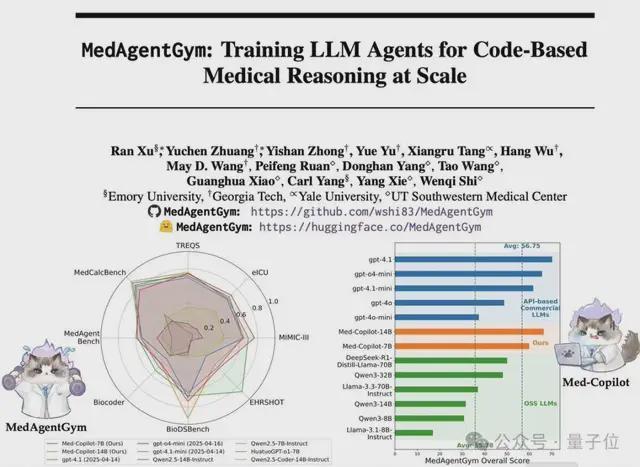
该平台不仅提供了全面的评估基准,更重要的是建立了完整的训练生态系统,能够系统性提升大模型在医疗领域的代码生成和推理能力。
实验结果表明,经过 MedAgentGym 训练的开源模型 Med-Copilot-7B 在多项医疗编程任务上达到了与 GPT-4o 相当的性能水平。
医疗 AI 的”编程瓶颈”
当前医疗 AI 应用面临着一个关键技术挑战:如何让 AI 系统自动生成可靠的医疗相关代码。
无论是处理电子健康记录(EHR)查询、生物信息学分析,还是构建临床决策支持系统,都需要精确的编程能力作为支撑。
然而,现有解决方案存在明显局限:
商业模型的现实困境
- 数据隐私风险:医疗数据的敏感性使得直接调用商业 API 存在合规风险
- 成本压力:大规模医疗应用的 API 调用费用难以承受
- 部署限制:无法在本地或私有云环境中灵活部署
开源模型的能力短板
- 专业知识不足:缺乏深度的医学领域知识
- 编程能力有限:在复杂的医疗编程任务上表现不佳
- 训练资源缺乏:缺少专门的医疗代码训练数据和环境
研究表明,引入编程能力可以显著提升模型在计算医疗推理任务上的表现。在 MIMIC-III、eICU 和 MedCalcBench 等数据集中,基于代码的计算推理成功率远高于传统的自然语言推理方法。
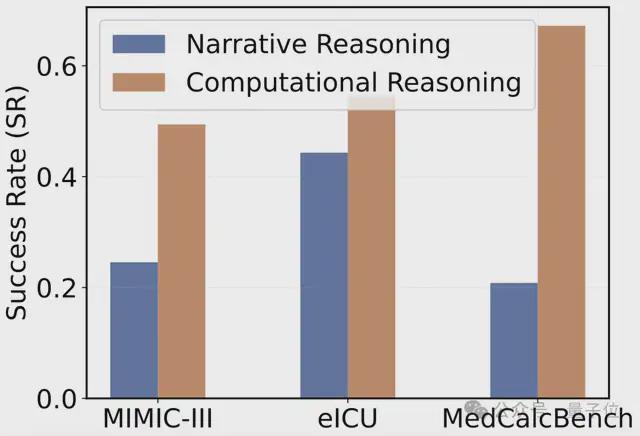
在 MIMIC-III、eICU 和 MedCalcBench 三个数据集中,基于代码的计算推理(橙色)成功率远高于传统的叙述式推理(蓝色)。
MedAgentGym:突破性的解决方案
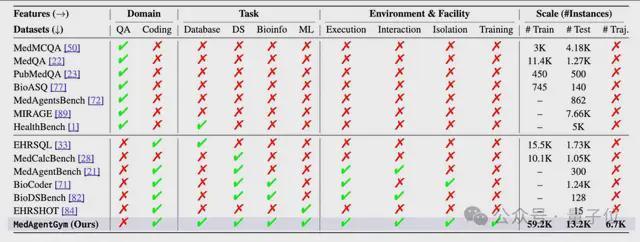
与其他基准相比,MedAgentGym 提供了集成了可执行环境、交互式反馈和任务隔离运行设施的编码训练平台。为了解决这一系列挑战,MedAgentGym 提供了一个前所未有的综合性解决方案。该平台的核心创新体现在三个维度:
大规模真实医疗任务集合
MedAgentGym 整合了来自 12 个真实生物医学场景的 72,413 个编程任务实例,覆盖 129 个不同类别。
任务范围横跨四大核心领域:
- 结构化医疗信息检索:如 EHR 数据库查询、临床记录分析
- 医疗数据科学:包括统计分析、临床计算等
- 生物信息学建模:涵盖序列分析、系统发育学等
- 机器学习应用:临床预测、风险评估等
数据模态极其丰富,包含临床笔记、实验室报告、EHR 表格、生物序列等多种格式,全面考验模型的综合处理能力。
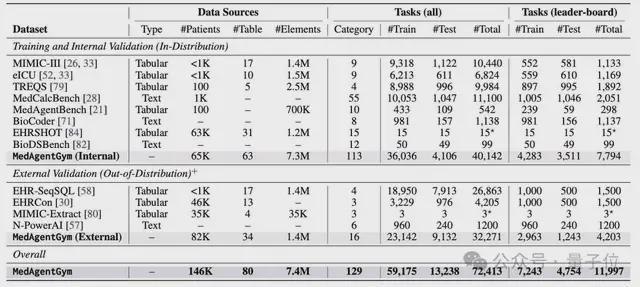
高效可扩展的训练基础设施
MedAgentGym 在技术架构上实现了多项突破:
- 容器化隔离环境:每个任务都封装在独立的 Docker 容器中,预装所有依赖项,确保环境安全性和可复现性
- 交互式反馈机制:当代码执行出错时,系统能将错误信息转化为结构化的自然语言反馈,帮助模型进行调试和优化
- 并行处理能力:集成 Ray 和 Joblib 等后端引擎,支持大规模并行轨迹采样和训练
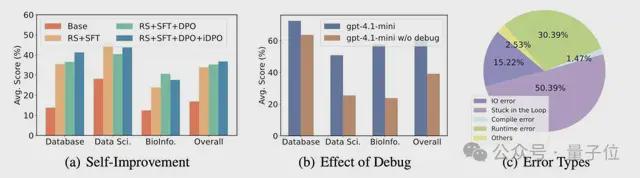
在拥有交互式调试能力时(蓝色),gpt-4.1-mini 模型的性能远高于移除该能力后(橙色)的表现,证明了 MedAgentGym 交互式环境的巨大价值。
此外,错误类型分析揭示了当前模型在复杂医疗代码任务中面临的主要挑战。其中,“陷入循环”不能成功 debug 是最主要的错误类型,占比高达 50.39%。
全面的模型评估体系
研究团队系统性评估了超过 25 个主流大模型,包括:
- API 商业模型:GPT 系列
- 开源通用模型:Qwen、LLaMA、Gemma 等
- 专业编程模型:Qwen2.5-Coder 等
- 医疗领域模型:HuatuoGPT、MedReason 等
评估结果揭示了商业模型与开源模型之间的显著性能差距,为后续优化指明了方向。
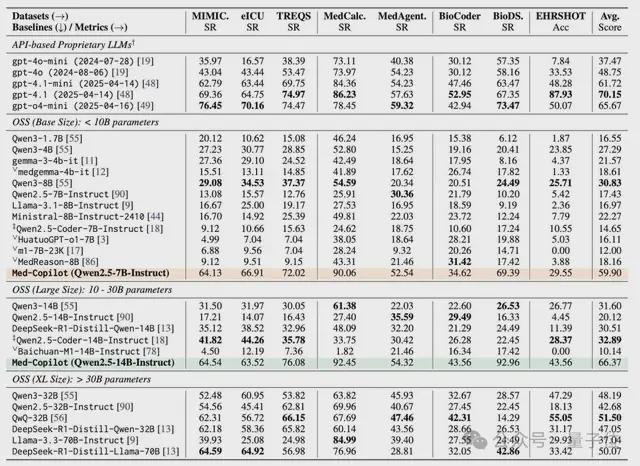
MedAgentGym 零样本(Zero-shot)测试集结果详细列出了超过 25 个前沿大模型在 8 个不同任务上的原始得分,是评估各模型在医疗代码生成领域综合实力的核心依据。
Med-Copilot:开源模型的逆袭之路
基于 MedAgentGym 平台,研究团队开发了 Med-Copilot 系列模型,并取得了突破性成果。
训练策略: 采用两阶段精细化训练框架:
- 监督微调(SFT):使用2,137 个成功执行的代码轨迹进行初始训练
- 强化学习优化(DPO):通过偏好优化进一步提升性能
性能突破:
Med-Copilot-7B 通过 SFT 训练,性能提升36. 44%
结合 DPO 后,总体性能提升达到42. 47%
最终在 MedAgentGym 基准上达到 59.90 分,接近 GPT-4o 的性能水平
关键技术创新:
研究团队还训练了一个 AI 验证器(Verifier),能够从多次代码生成尝试中自动识别最佳解决方案。实验显示:
- 在 16 次尝试中,模型的潜在成功率可达 45%
- AI 验证器能够以 42% 的准确率识别出正确答案
- 仅有3% 的差距证明了验证器的可靠性
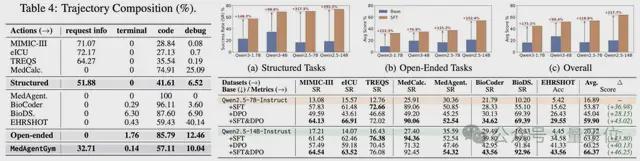
仅使用 SFT、仅使用 DPO 以及 SFT 与 DPO 结合的策略对 7B 和 14B 基础模型性能的提升效果,验证了 SFT+DPO 两阶段训练框架的有效性。
可持续进化的蓝图:自我提升与性能扩展
MedAgentGym 不仅展示了一次性的成功,更揭示了一条可持续进化的清晰路径。其中的关键,在于一个强大的“AI 裁判”(即验证器,Verifier)。
性能具备高度可扩展性
研究团队让模型对同一个任务进行多次尝试(最多 16 次),并让“AI 裁判”从这些尝试中选出最佳答案。结果令人惊喜:
- 潜力上限 (Pass@k):在 16 次尝试中,模型只要有一次成功,就算解出。在这种理想情况下,成功率从单次尝试的 17% 飙升至 45%。这说明模型本身具备解决问题的潜力。
- 实际表现 (Best@k):更关键的是,在“AI 裁判”的帮助下,从这 16 次尝试中自动选出的最佳答案,其实际成功率高达 42%!
仅有3% 的微小差距证明,这个 AI 裁判的眼光极其“毒辣”,能够非常可靠地识别出正确的解决方案。这一成果意义重大,因为它意味着这个验证器已经足够强大,可以作为奖励模型(Reward Model)赋能给 PPO、GRPO 等更先进的在线强化学习框架,为训练出更强大的医疗 AI 铺平了道路。
- 无论是增加训练数据量,还是在推理时增加尝试次数(Rollouts),模型的最终成功率都表现出稳定、显著的提升。这为未来进一步提升模型性能指明了方向:更多的计算投入和数据积累,将带来更强大的医疗 AI 智能体。
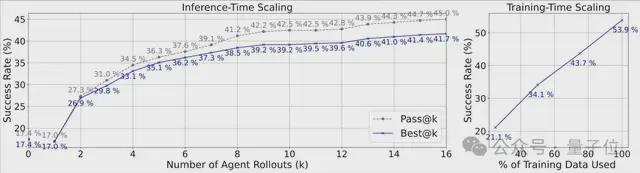
推理时增加尝试次数(k)能提升成功率(Pass@k);此外,显示增加训练数据量也能稳定提升模型表现。
- 模型可以自我提升:这种强大的验证能力也解锁了模型的自我提升:AI 智能体可以通过“拒绝采样+迭代 DPO”的自我改进循环,利用自己生成的轨迹数据进行持续学习和优化,不断突破性能上限 (3-5%)。
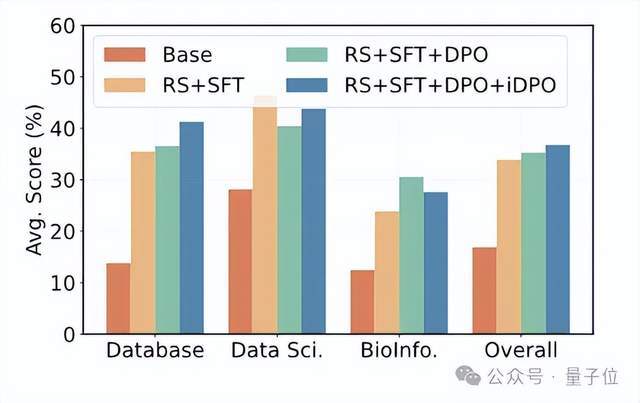
通过“拒绝采样 SFT”和两轮 DPO 的自我改进循环,模型性能得以持续增长。
未来展望:加速医疗 AI 的普惠化进程
MedAgentGym 的发布,为医学的 AI 和大语言模型智能体的研究者和开发者提供了一个强大工具。它通过提供一个统一、开放、可扩展的平台,填补了医疗代码智能体开发领域的关键空白。
通过将真实世界的生物医学任务、高效可复现的基础设施以及对前沿模型的大规模基准测试相结合,MedAgentGym 为推动 LLM 在医疗领域的应用奠定了一个坚实的基础。
研究团队希望,MedAgentGym 能够激发更多创新,促进高效、可靠、临床接地的 AI 智能体的发展,最终为现实世界的医疗研究与实践提供支持。
有理由相信,在 MedAgentGym 的助力下,一个能够从成功中学习、从失败中进化的,更加智能和高效的未来医疗新时代,正加速到来。
论文链接:https://arxiv.org/abs/2506.04405
项目主页:https://wshi83.github.io/MedAgentGym-Page/






