
新智元报道
编辑:KingHZ
从 GPT-2 到 Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏 MoE 架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?
从传统稠密架构到如今流行的稀疏专家模型(MoE),语言大模型发展突飞猛进:
最初参数量只有百亿级别,而现在即便仅激活的参数,也已达数百亿!
从百亿到万亿,参数膨胀的背后,是 AI 界对 Scaling Law 的「信仰」。
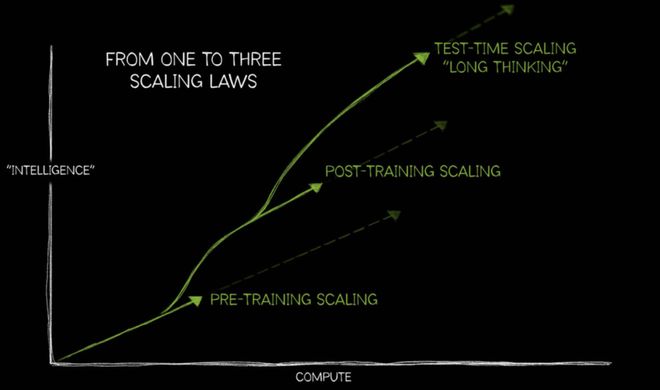
自 2019 年 GPT-2 发布以来,大语言模型(LLM)在参数规模、训练数据量和模型架构上不断实现飞跃。
大模型到底有多大?从 2019 年到现在,大模型到底经历了什么样的「体重暴涨」?
Github 网友 rain-1 手动总结了基础模型趋势,「不含任何 AI 生成成分」。他还表示:
近年来,语言模型波澜壮阔,宏大深远。
所记述的不过是其中一个微小片段,如同管中窥豹,可见一斑。
本文旨在客观呈现大语言模型的规模信息。不涉及泄露信息或坊间传闻,仅聚焦基础模型(即原始文本续写引擎,而非 ChatBot)。
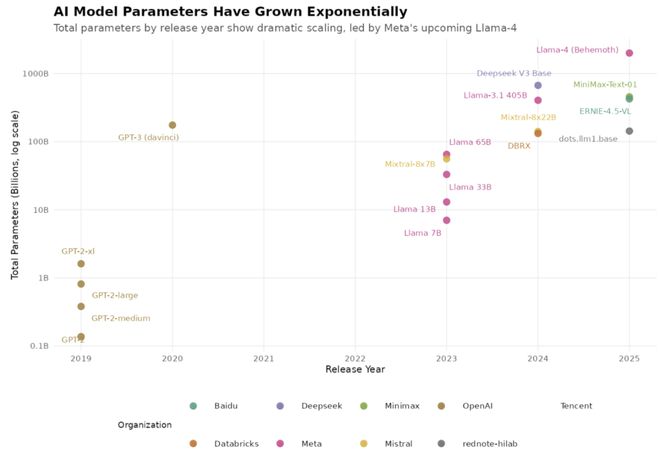
AI 模型参数量呈指数级增长
大模型来时路之 GPT 系列
OpenAI 走向「CloseAI」
主要分为 2 大阶段:早期密集模型和中期转型与保密期。
早期密集模型(2019-2020):
GPT-2 家族:参数从 137M 到 1.61B,训练数据约 10B tokens。
GPT-3(175B):首个真正意义上的「大模型」。
中期转型与保密期(2022-2023):
GPT-3.5 和 GPT-4:未公布参数或数据规模,信息高度保密。
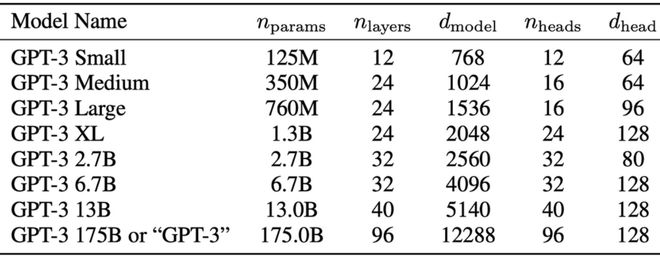
具体而言,GPT-2(2019 年)参数规模:
GPT-2-small:1.37 亿参数
GPT-2-medium:3.8 亿参数
GPT-2-large:8.12 亿参数
GPT-2-xl:16.1 亿参数
训练数据基于未公开的WebText数据集,约 40GB 互联网文本,估计约 100 亿 token。
2020 年,OpenAI 发布 GPT-3,代号 davinci/davinci-002,参数规模为 1750 亿(175.0B)。
链接:https://www.lesswrong.com/posts/3duR8CrvcHywrnhLo/how-does-gpt-3-spend-its-175b-parameters
训练数据约 4000 亿 token,来源包括 CommonCrawl、WebText2、Books1、Books2 和 Wikipedia。
具体数据来源信息,参考下列论文。

论文链接:https://arxiv.org/abs/2005.14165
GPT-3 训练耗时数月,动用了数万块A100GPU的数据中心算力。
2022-2023 年,GPT-3.5&GPT-4 官方未公开架构细节、训练数据规模等信息。
之后。OpenAI 一度成为高度保密的「黑箱」。而开源模型,特别是 LLaMA 家族「水涨船高」:
从 7B 到 65B,其中 65B 使用 1.4T tokens 训练;
LLaMA 3.1 达到 405B 参数、3.67T tokens 数据,是开源领域的一个转折点。
大模型来时路之 Llama 系列
Llama 初代版本规模 7B、13B、33B、65B参数。
训练数据方面,官方确认采用了Books3数据集。65B 版本预训练使用了1. 4 万亿(1.4T)token的数据集。

2024 年,Meta 开源 Llama-3.1 405B,参数规模高达4050 亿,采用密集 Transformer 架构(即推理时所有参数均参与计算)。
训练数据方面,Meta 未详细披露数据源,仅模糊表述为「来自多种知识来源的混合数据」,共消耗了约3. 67 万亿 token:
初始预训练:2.87 万亿 token
长上下文训练:8000 亿 token
退火训练(Annealing):4000 万 token

论文链接:https://arxiv.org/abs/2407.21783
他们还有项关键发现:
实验表明,在核心基准测试中,对小规模高质量代码和数学数据进行退火训练(Annealing),可显著提升预训练模型的表现。
但网友本人对当前流行的「Benchmax 退火预训练」趋势表示遗憾——
它使得基础语言模型逐渐偏离了「初心」——纯粹的文本续写引擎定位。
这种优化本该属于后训练阶段(即让模型扮演「AI 聊天助手」角色的过程),但企业显然更看重benchmark 分数的短期提升。
2025,Meta 推出 Llama-4 系列,其中 2 万亿参数巨兽「Behemoth」,或永不面世。
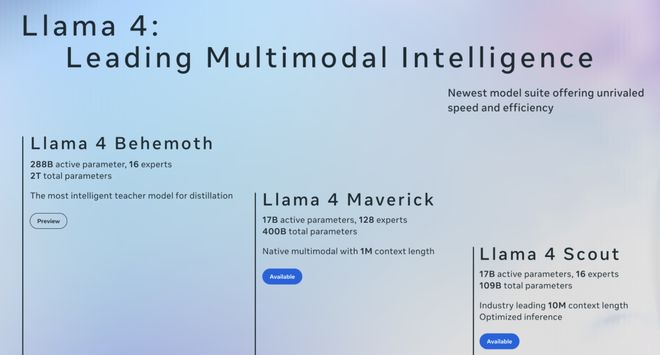
Llama4 系列中的旗舰大模型 Behemoth,是参数总量达2 万亿的稀疏专家模型(MoE),架构为A288B 16E——即具备 2880 亿激活参数、共计 16 个专家模块,但尚未公开发布
Llama4 的 Maverick 和 Scout 模型都是从这款大模型中蒸馏而来。然而,围绕这些轻量版本,却爆发了一场丑闻——
Meta(原 facebook)被曝在 lmarena 基准测试平台上「作弊」:

此举被外界视为学术不端,严重打击了外界对 Llama 团队的信任。此后,,至今不明这款 2T 模型是否还有问世的可能。
至于已经发布的 Llama4 小模型,尽管打着「继承大模型精华」的旗号,但目前普遍评价是:智能水平较低,难堪大用。
大模型荒原时代
曾经,AI 界一度陷入「大模型荒原」——其他模型无法与 GPT-3 匹敌。
大家只能反复微调 LLaMA 等小模型,试图追赶 GPT-3 留下的庞大身影。
但这种「用 AI 训练 AI」的做法,也让模型性能陷入恶性循环。
Llama 405B 模型的发布堪称转折点。在此之前,Mistral 发布了 2 款混合专家模型:
2023 年 12 月,推出 Mixtral 8x7B(混合专家模型)。
2024 年 4 月,升级发布 Mixtral-8x22B(总参数量 141B,实际激活参数 39B 的稀疏混合专家模型)。
Mixtral-8x22B 尽管不是 GPT-3 那样的密集模型,但总参数量级已与 GPT-3(175B)相当。

混合专家 MoE 架构的革命性在于,它让普通研究者也能训练和使用超大规模的模型——不再需要动用成千上万张 GPU 组成的计算集群。
2023 末,稀疏 MoE 架构的兴起:Deepseek V3 等接踵而来。
在参数总量远超 GPT-3 的同时,MoE 模型激活参数维持在几十B级别,从而降低推理成本。
这些 LLM 支持多语言、多模态,并采用更大上下文窗口(32K~256K tokens)。有的新模型还采用「退火」式后训练,提升特定基准测试上的表现。
MoE 热潮来袭
群雄并起,谁主沉浮?
2024 年圣诞节次日,DeepSeek发布了震撼之作——V3 Base。官网如此描述:
V3 新特性
6710 亿 MoE 参数
370 亿激活参数
基于 14.8 万亿高质量 token 训练

这不仅实现了模型规模的巨大飞跃,衍生的 R1 推理模型更让业界惊艳——
R1 可能是首个真正达到 GPT-4 水平,而且可自由下载使用的模型。
稀疏的不是能力,是让计算更精准地对焦。
此次突破掀起了 MoE 大模型的训练热潮,尤其在中国市场。值得注意的是,这些新模型普遍具备多模态、多语言能力,训练数据维度大幅拓展。
代表性模型巡礼:
1. Databricks DBRX(2024 年 3 月)
-
架构:1320 亿总参/360 亿激活/12 万亿 token 训练
-
创新点:采用 16 选 4 的细粒度专家系统(相较 Mixtral-8x7B 的 8 选 2 架构更精细)

2. Minimax-Text-01(2025 年 1 月)
-
架构:4560 亿总参/459 亿激活
-
特色:创新性融合注意力机制与 MoE 架构
-
质量控制:采用前代 60 亿参数 MoE 模型进行数据标注
3. Dots.llm1(2025 年 6 月)
-
亮点:128 选 6 超细粒度专家系统 +2 个常驻专家
-
成就:不使用合成数据即达到 Qwen2.5-72B 水平
-
技术:引入 QK-Norm 注意力层优化
4. 混元(2025 年 6 月)
-
突破:20 万亿 token 训练/256K 上下文窗口
-
架构:8 专家动态激活 +1 个常驻共享专家
5. 文心 4.5(2025 年 6 月)
-
规模:4240 亿总参/470 亿激活
-
特点:多模态基座模型
-
训练:基于「数万亿」token(具体数据未披露)
尾声
未来在哪里?
在很长一段时间内,市面上几乎没有与 GPT-3 规模相同的 LLM 可供使用。
由于缺乏可下载的同等级模型,人们很难复现 GPT-3 的性能。
而且坦率地说,人们当时并没有真正意识到:要想要达到 GPT-3 的表现,模型的规模必须接近 1750 亿参数。
当时能拿来用的,最多也只是 LLaMA 系列中参数不超过 700 亿的模型,大家也只能靠这些凑合着用。
而目前,网友 rain 所知的最新、最大的可用稠密基础模型有 4050 亿参数。在预训练中,它使用了更近时段的数据(包括人们讨论大语言模型、分享模型对话记录的内容),而且模型本身也经过「退火」(annealing)处理。
因此相比以往那些基础模型,它更像已经初步具备助手特性的系统。
最近一批稀疏专家模型(MoE)也有类似的问题,并且这些模型在训练数据中还融入了一些中文文化元素。
要怎么公平地比较稀疏模型(MoE)和致密模型,目前还没有明确标准。

也许大语言模型的一些高级能力,只有在模型足够深、结构足够密集时才会显现出来。而现有的自动评测指标,可能并不能很好地捕捉这些能力。所以现在很多人索性一头扎进了 MoE 模型的研发中。
一些新模型也在尝试采用新的网络架构(比如 RWKV、byte-latent、bitnet)或者使用合成数据生成的新方法。
不过,要打造一个优秀的文本生成引擎,目前还不清楚这些新技术到底有多大帮助。
网友 rain 说得直接:文本生成引擎才是一切的基础。
没有优秀的文本续写能力,后续的微调、角色扮演都只是空中楼阁。
在「助手化」狂潮之外,也许是时候重新思考——
我们真的理解基础模型的本质了吗?
参考资料:
https://gist.github.com/rain-1/cf0419958250d15893d8873682492c3e






