
新智元报道
编辑:Aeneas KingHZ
Transformer 杀手来了?KAIST、谷歌 DeepMind 等机构刚刚发布的 MoR 架构,推理速度翻倍、内存减半,直接重塑了 LLM 的性能边界,全面碾压了传统的 Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
就在刚刚,KAIST、Mila 和谷歌 DeepMind 团队等放出重磅炸弹——
一个名为 Mixture-of-Recursions 的全新 LLM 模型架构。
这个崭新的架构,被业内认为有潜力成为 Transformer 杀手!
它的推理速度提升 2 倍,训练 FLOP 减少,KV 缓存内存直接减半。
最终,在 135M 到 1.7B 的参数规模下,MoR 直接划出了一个新的帕累托前沿:相同的训练 FLOPs,但困惑度更低、小样本准确率更高,并且吞吐量提升超过 2 倍。
全面碾压传统的 Transformer!

论文链接:https://arxiv.org/abs/2507.10524
其实,学界很早就发现,Transformer 复杂度太高,算力需求惊人。
比如最近 CMU 大牛、Mamba 架构作者 Albert Gu 就表示,Transformer 模型能力的局限太大,所谓 token 就是胡扯。

而谷歌产品负责人 Logan Kilpatrick 公开指出了注意力机制的缺陷——不可能实现无限上下文,还强调必须要在核心架构层进行全面创新。
今天谷歌 DeepMind 的这项研究,和这些大牛的观点不谋而合了。
对此,网友们纷纷表示实在炸裂。
有人预测,潜在空间推理可能会带来下一个重大突破。
显然,对于代码、数学、逻辑这类分层分解问题的任务,MoR 都是一个改变游戏规则的重磅炸弹。

甚至还有人评论道:看起来像是 Hinton 的胶囊网络重生了。

谷歌 DeepMind 放大招
递归魔法让 LLM 瘦身还提速
LLM 发展到如今,接下来该怎样做?靠堆参数、加层数,让它更聪明吗?
这项研究告诉我们:真正的高手,从来都不是靠堆料,而是靠设计的艺术。
这次他们做出的 MoR 全新架构,直译出来是「递归混合体」,直接让 LLM 推理速度噌噌翻倍!
所以,MoR 究竟做了什么?
简而言之,它做了以下两点。
1. 不对所有 token 一视同仁
LLM 在处理文本时,会把句子拆成一个个 token,不过,像「的」「是」「在」这种词,并不需要多高深的推理,只需要一次前向传播就够了。而复杂的 token,则需多次经过同一层栈。
MoR 的聪明之处就在于,因 token 而异。
MoR 的秘密武器是小型路由器,会为每个 token 的隐藏状态打分,仅高分 token 的会继续循环,其余的则提前退出。
2. 循环复用:一个模块搞定全部
传统 Transformer 的思路就是不断「堆层」,堆得越高,处理能力越强。但这样的代价,就是内存和算力:模型会越来越慢,越来越贵。
而 MoR 则反其道而行之,专门设计了共享块,每个 token 最多循环 4 次,只要路由器说「完成」,就提前跳出循环。
总之,如果说 Transformer 是一个庞大的工厂流水线,那 MoR 就更像一支高效的特种部队。未来的 AI,恐怕不会再比拼谁更重,而是谁更会分工调度、节省力气。
而谷歌 DeepMind,已经敏锐地把握到了这一点,给我们演示了这一趋势的早期范本。
真自适应计算
只靠 Scaling law,把语言模型做大,确实能让它能力暴涨,但训练、部署所需的算力和成本也跟着暴涨。
现在常见的「瘦身」招数,要么是把参数共享(省显存),要么是按需计算(省算力)。
但目前仍缺乏一种能将两者有机融合的架构。
「递归混合」(Mixture-of-Recursions, MoR),充分发挥了递归 Transformer 的潜力(见图1),成功融合了两者。
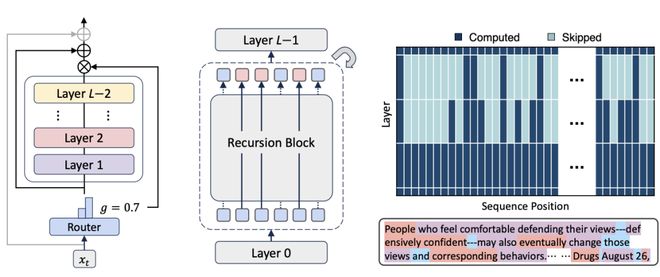
图1:递归混合(Mixture-of-Recursions,MoR)概览
(左)每个递归步骤包含固定层堆栈和决定 token 是否继续递归的路由器(中间灰框区域)。
(中)完整模型结构,其中共享递归步骤根据路由决策对每个 token 最多应用次。
(右)展示 token 级递归深度的路由模式示例,颜色越深表示该 token 在递归块中的计算越活跃。底部数字以不同颜色标注各文本 token 的递归步数:1 步、2 步和 3 步 。
在统一的架构中,MoR 同时实现了三种效率优化:
通过共享权重压缩参数量;通过动态路由减少冗余计算;通过智能缓存减少内存开销。
递归混合架构
在预训练和推理过程中,MoR 为每个 token 动态调整递归步骤,依赖两大组件:
路由机制和 KV 缓存策略。
路由机制:专家选择 vs.token 选择
受 top-k 门控机制的启发,研究人员提出了专家选择路由(Expert-choice routing)(见图 2a)。
在这种模式下,递归深度可看作「专家」,每轮递归时这些专家会挑选它们认为最值得处理的 top-k 个 token。

为了让递归更具一致性,团队还引入了分层筛选机制(hierarchical filtering):只有在第r层中被选中的 token,才有资格参与第r+1 层的评估。
这一设计模拟了早退出机制,让模型在训练初期就能自动「筛选」出需要深度处理的 token,把算力集中到最困难的 token 上。
与前者不同,token 选择路由(token-choice routing)(见图 2b),在一开始就决定了每个 token 要走多少次递归流程。
具体来说,根据第 1 层的隐藏状态,模型会计算每个专家的打分(如通过 softmax 或 sigmoid)。
假设有个专家,每个专家对应一次递归,那么模型将 token 分配给得分最高的专家。 token 将被送入前i层递归,每层都按顺序进行处理。
在这种方式中,token 在进入网络时就确定好递归深度,同时避免了每一层的重新选择,提升了推理效率。
表 2 左比较了两种方法:
expert-choice 路由的优点在于,它可以实现理想的计算负载均衡。然而,它容易信息泄露。
相比之下,token-choice 路由天然不会泄露信息。但这种方式负载分配不均。

表2:路由策略与键值缓存策略的比较。(左)两种路由策略总结:专家选择与令牌选择;(右)缓存策略相对于普通 Transformer 的相对成本效率
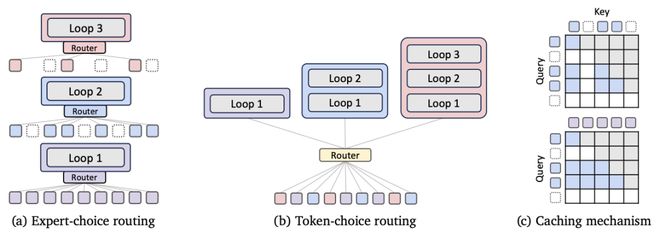
图2:混合递归(MoR)的架构组件。(a)专家选择路由;(b) token 自主选择路由;(c) KV 缓存策略
KV 缓存策略:按递归层缓存 vs. 跨层共享
针对 MoR 模型,研究人员提出了两种 KV 缓存策略:按递归层缓存和跨递归共享。
1. 按递归层缓存(见图 2c 上)是「选择性缓存」:只有被路由到某一递归层的 Token,才会在该层生成并存储它的 KV 对。
注意力计算仅在当前递归层的缓存内进行,这种设计有助于实现局部化计算,显著提升了内存使用效率,并减少I/O负担。
2. 跨递归共享(见图 2c):只在第一个递归层生成并缓存 KV 对,然后在之后所有层中重复使用。这种机制下,每一层参与注意力计算的 Query 数量可能会减少。
也就是说,所有 Token 无论在后续层是否继续参与计算,都可以完整地访问历史上下文,无需重新计算。
表 2 右对比了两种缓存策略:
-
按递归层缓存:KV 内存与I/O负担,被压缩为原来的一半左右。
-
跨递归共享:只能线性压缩注意力计算量,而且 KV 的读写次数较高,可能会成为性能瓶颈。
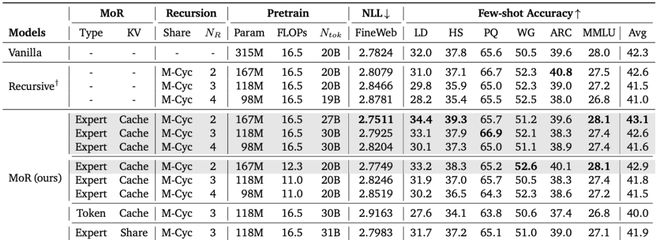
表3:在等计算量与等 token 数条件下,MoR、递归 Transformer、普通 Transformer 的比较
实验
研究者从零开始预训练模型,采用基于 Llama 的 Transformer 架构,参考了 SmolLM 开源模型的配置,在 FineWeb-Edu 的验证集和六个 few-shot 基准测试集上进行了评估。
主要结果
在相同训练计算预算下,MoR 以更少参数优于基线模型
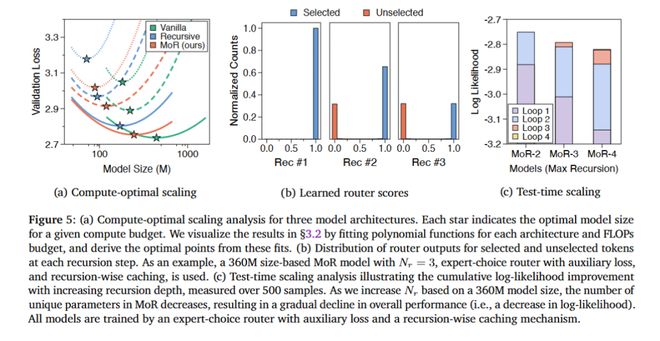
在相同的训练预算(16.5e18 FLOPs)下,研究者将 MoR 模型与标准 Transformer 和递归 Transformer 进行了对比。
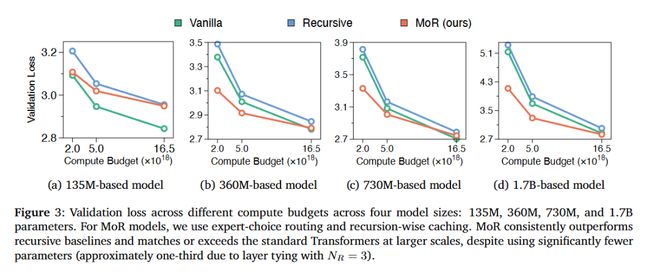
在四种模型规模(135M、360M、730M 和 1.7B 参数)下,不同计算预算对应的验证损失对如图
如表 3 所示,MoR 模型采用专家选择路由和两次递归(Nr=2),不仅在验证损失上更低,在 few-shot 平均准确率上也优于标准基线。
这得益于 MoR 更高的计算效率,使其在相同 FLOPs 预算下能处理更多的训练 token。
在相同数据量下,MoR 用更少计算量仍优于基线模型
为了隔离架构差异的影响,研究者在固定训练 token 数量(20B)的前提下进行分析。
结果证实,在少了 25% 训练 FLOPs 的情况下,MoR 模型(=2)仍然实现了更低的验证损失和更高的准确率,超越了标准和递归基线。
与标准基线相比,MoR 模型的训练时间减少了 19%,峰值内存使用量降低了 25%。
这就要归功于专门设计的分层过滤机制和按递归进行的注意力机制。
此外,MoR 的性能也会受路由与缓存策略的影响。
IsoFLOP 分析
评估一种新模型架构设计的核心标准之一,是其在模型规模和计算量增长时,性能是否能持续提升。
因此,研究团队全面对比了 MoR 与标准 Transformer(Vanilla)和递归 Transformer。
实验设置
实验的模型规模有四种:135M、360M、730M 和 1.7B 参数。
对于递归 Transformer 和 MoR 配置,递归次数统一设为3。
在三个不同的计算预算下,进行预训练:2e18、5e18 和 16.5e18 FLOPs。
MoR架构:可扩展且参数高效
如图 3 所示,在所有参数规模和算预算力下,MoR 始终优于递归基线模型。
尽管在最小规模(135M)时,MoR 表现略逊于标准 Transformer,但随着模型规模扩大,这一差距迅速缩小。
当参数规模超过 360M 时,MoR 不仅能够与标准 Transformer 持平,甚至在低计算量和中等计算预算下,表现更加优越。
总体而言,这些结果表明,MoR 具备良好可扩展性和高参数效率,可替代旧架构。
推理吞吐量评估
通过参数共享,MoR 能利用连续深度批处理技术,在推理阶段显著提升了吞吐量。
这种机制在解码过程中,旧序列完成后立刻填入新 tokens,持续保持了 GPU 的高利用率。
实验设置
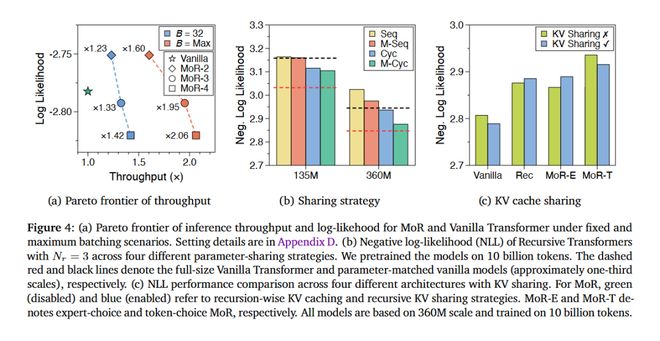
在 360M 参数规模下,在不同递归深度(2、3 和4)下,团队测试了 MoR 模型。
利用深度批处理,MoR 显著提升推理吞吐量
如图 4a 所示,在两种设置下,MoR 变体的推理吞吐量都超过了普通 Transformer。
递归深度越高,越多 tokens 会提早退出,从而减少 KV 缓存的使用,进一步大幅提升了推理速度。例如,在最大批设置(=Max)下,MoR-4 速度可提升2. 06 倍。
实验表明,结合深度批处理机制与提前退出策略,可大幅加速 MoR 模型在实际的推理速度。
消融实验等更多内容和细节,请参阅原文。
参考资料:
https://arxiv.org/abs/2507.10524
https://x.com/rohanpaul_ai/status/1945342236310561091
https://www.rohan-paul.com/p/landmark-research-from-google-deepmind






