文|数据猿
"友商,你们拿什么和我比?"
"友商,你们拿什么和我比?"这不是哪家公司的狂妄宣言,而是当前 AI 战场最真实的写照。IDC 预测,2024 年,全球各组织将在人工智能上投入 2350 亿美元,2028 年这⼀数字将增长近三倍,超过 6300 亿美元。这预示着未来⼏年的复合年增长率(CAGR)将接近 30%。开源大模型以其开放、透明、可定制的特性,成为驱动 AI 加速创新进程的核心引擎,它们让全球的开发者和企业能够以前所未有的速度参与到 AI 的研发和应用中来。
不过我们也不能简单的认为就是各科技厂商之间的技术比拼,其背后更是各国较量科技实力的无声战场。还记不记得当时 DeepSeek 爆红引发的各种质疑,当时的外媒报道中充斥着大量对 DeepSeek 的质疑。今日头条的一篇文章中说"一个去年 7 月成立的公司,刚刚成立一年半,仅有 4 人缴纳社保,竟然能开发出全球顶尖的 AI 大模型,你们信吗?它就是——深度求索,开发了 DeepSeek 的公司。"
"大佬"的进阶之路
说一千道一万,回到日常生活,Meta 的 Llama 2 以开源之名横扫全球,Qwen 系列背靠阿里云势头迅猛,DeepSeek 以恐怖的技术指标席卷各大版面成功演绎什么叫"后来居上"。真正的实力面前,从来没有谦让,反而是对技术自信的张狂。很多用户可能会问,"这么多大模型公司,该怎么看谁更厉害呢?"今天,我们就来看看他们到底都看什么!先来整体梳理下这三家公司的发展脚步,大致如下图:
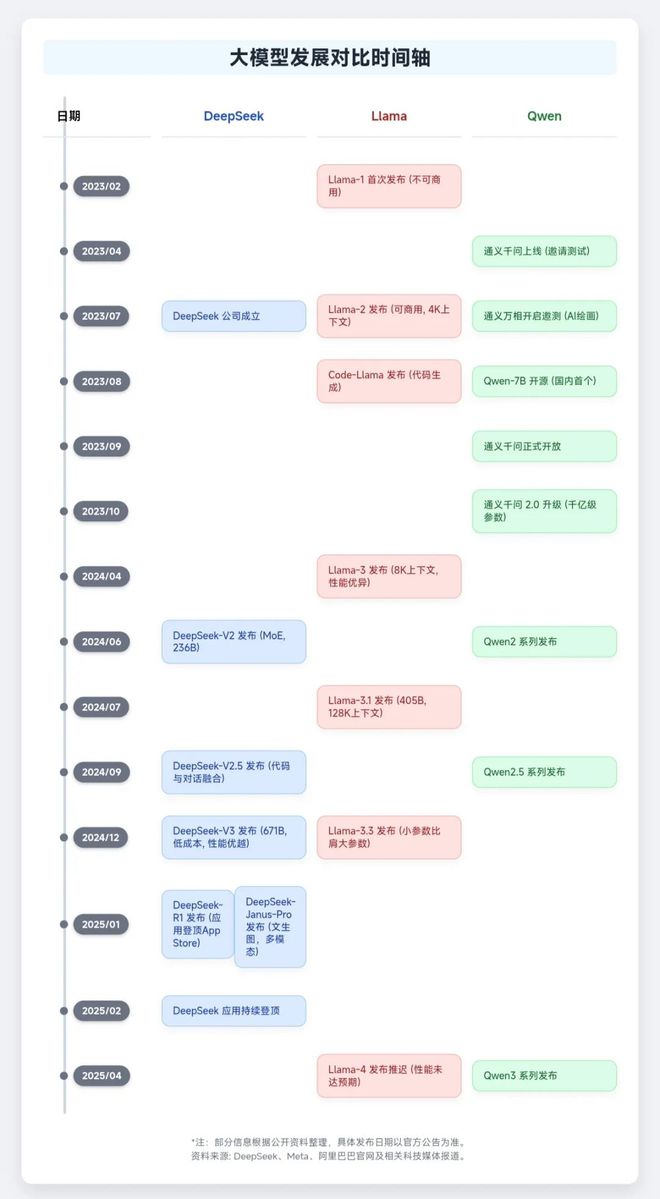
图:DeepSeek、Llama、Qwen 三家发展梳理图来源:数据猿经查找网络资料后制作
1. DeepSeek:后来居上,不是闹着玩的
DeepSeek 作为中国 AI 领域的新兴力量,在开源大模型赛道上展现出了令人瞩目的发展速度和技术实力,其发展时间线清晰且迭代迅速,在技术创新和市场响应上极具敏捷性。据大量新闻报道,今年 1 月 26 日晚,游戏科学创始人、CEO 冯骥发文,称"DeepSeek,可能是个国运级别的科技成果"。他还表示,如果有一个 AI 大模型做到了以下任何一条,都是超级了不起的突破,DeepSeek 全部同时做到了。
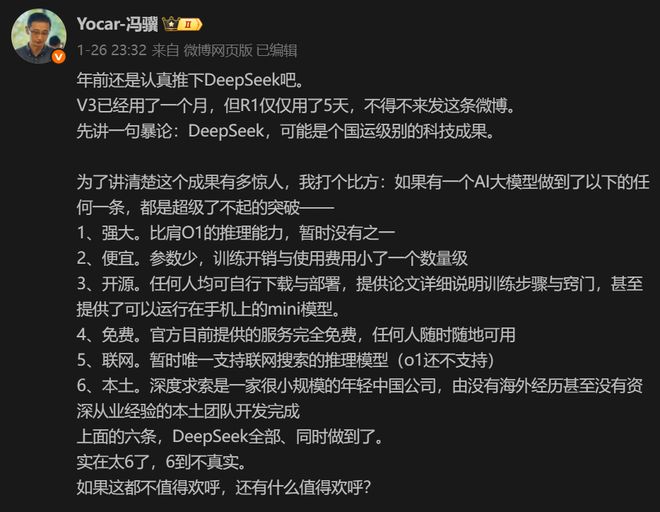
图:冯骥评 DeepSeek 来源:微博
DeepSeek 的旅程始于 2023 年,深度求索公司正式成立。随后,在短短一年多的时间里,系列模型经历了多次关键迭代。
·2023 年 7 月:DeepSeek 公司正式成立,标志着其在 AI 大模型赛道的布局。
·2024 年 1 月:DeepSeek 发布了首个通用语言模型 DeepSeek LLM,开启了技术追赶的序幕。
·2024 年 5 月:DeepSeek-V2 发布,总参数达 2360 亿,采用 MoE 架构优化,大幅降低成本并开源,迅速引发市场关注。
·2024 年 9 月:DeepSeek-V2.5 发布,融合代码生成与对话能力,拓展了多场景应用。
·2024 年 12 月:DeepSeek-V3 发布,总参数提升至 6710 亿,训练成本仅为 557.6 万美元,性能在多项评测中超越 Owen2.5-72B 和 LLaMA 3.1-405B。
·2025 年 1 月:DeepSeek-R1 发布,性能媲美 OpenAI,应用全球上线,全球和美国的日活跃用户数增长超 110%,登顶苹果应用商店免费下载排行榜。
·2025 年 1 月:DeepSeek-Janus-Pro 发布,支持文生图与多模态理解,挑战 OpenAI DALL·E和 Midjourney。
·2025 年 2 月:DeepSeek 应用持续登顶苹果中国和美国应用商店,在超过 140 个国家中排行第一位。
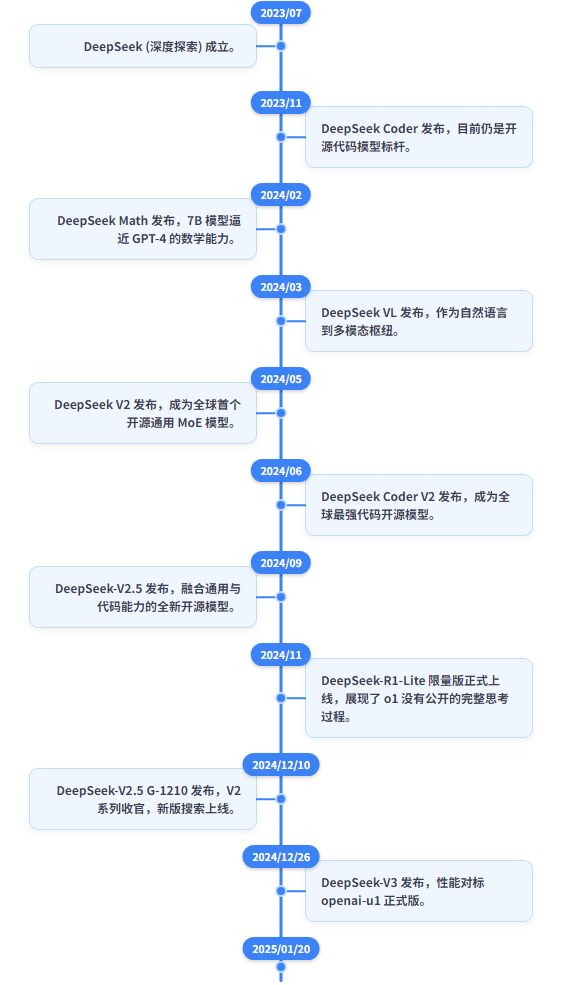
图:DeepSeek 模型迭代与发展历史沿革
来源:梳理网络信息及国信证券《电子 AI+ 系列专题报告(六)——DeepSeek 重塑开源大模型生态,AI 应用爆发持续推升算力需求》后制作
2. Llama:开源世界的"鲶鱼"
自 2023 年 2 月首次亮相以来,Meta 的 Llama 系列大语言模型(LLM)在 AI 领域掀起了巨大的波澜。从最初的 Llama-1 到如今即将发布的 Llama-4,这一系列模型不仅在技术上不断突破,更在开源社区和商业应用中展现出强大的影响力。
·2023 年 2 月 24 日:Meta 首次推出 Llama-1,包含 7B、13B、30B 和 65B 四个参数版本。Llama-1 凭借其出色的性能和开源特性,迅速成为开源社区的焦点。然而,由于开源协议限制,该版本不可免费商用。
·2023 年 7 月:Meta 发布 Llama-2,进一步扩充了模型规模至 70B,并引入了分组查询注意力机制(GQA),同时将上下文长度翻倍至 4096。Llama-2 不仅性能更强,还首次实现了免费可商用。
·2023 年 8 月:基于 Llama-2,Meta 发布了专注于代码生成的 Code-Llama,进一步拓展了 Llama 的应用场景。
·2024 年 4 月:Llama-3 正式发布,包含 8B 和 70B 两个版本,并支持 8K 长文本输入。该版本在多个基准测试中表现优异,超越了同期的多个先进模型。
·2024 年 7 月:Llama-3.1 发布,推出了 4050 亿参数的超大型模型,并将上下文长度提升至 128K tokens。
·2024 年 12 月:Llama-3.3 发布,仅 70 亿参数的模型在性能上比肩 Llama-3.1 的 4050 亿参数版本,同时大幅降低了推理和部署成本。
·2025 年 4 月:Llama-4 发布多次推迟,据新浪财经,关键原因是技术基准测试未达内部预期,如推理和数学任务有短板,模拟人类语音对话不及 OpenAI。
3. Qwen:阿里云的"生态王牌"
Qwen(通义千问)是阿里巴巴达摩院研发的大语言模型系列。其命名源自中文"通义千问",寓意着致力于通过技术回答人类的各种问题。
·2023 年 4 月:通义千问上线并邀请用户测试体验,是国内最早一批类 ChatGPT 大模型产品。
·2023 年 6 月:聚焦音视频内容的工作学习 AI 助手"通义听悟"上线。
·2023 年 7 月:AI 绘画创作大模型"通义万相"开启定向邀测。
·2023 年 8 月:通义千问 70 亿参数模型 Qwen-7B 开源,阿里巴巴成为国内首个开源自研大模型的大型科技企业。
·2023 年 9 月:通义千问正式向公众开放。
·2023 年 10 月:通义千问升级到 2.0 版本,参数规模达千亿级。
·2024 年 6 月:Qwen2 系列发布,包含 0.5B 到 72B 多个尺寸。
·2024 年 9 月:Qwen2.5 系列发布,涵盖 0.5B 到 72B 多个尺寸。
·2025 年 4 月:Qwen3 系列发布,包含 0.6B 到 235B 多个尺寸。
图:通义千问对话页面来源:阿里云
性能 PK
Llama 副总裁 Ahmad AI-Dahle 于今年 4 月 6 日在社交媒体平台X发布了一张测试图片,并配文"截至今天,Llama4 Maverick 提供了一流的性能与成本比,其实验性聊天版本在 LMArena 上的 ELO 得分为 1417。"这位副总裁还感慨道几年前的 Llama 还是一个研究项目,真是令人难以置信。
1、ELO 评分
让我们来看看他发的这张图表,该图展示了不同语言模型在 LMArena 平台上的 ELO 评分与成本之间的关系。ELO 评分是什么?它通常用于衡量棋手的水平,这里被用来衡量语言模型的性能,成本则是指运行这些模型所需的费用。图中的每个点代表一个特定的语言模型,横轴表示成本(从$0.00 到$100.00),纵轴表示 ELO 评分(从 1200 到 1425)。
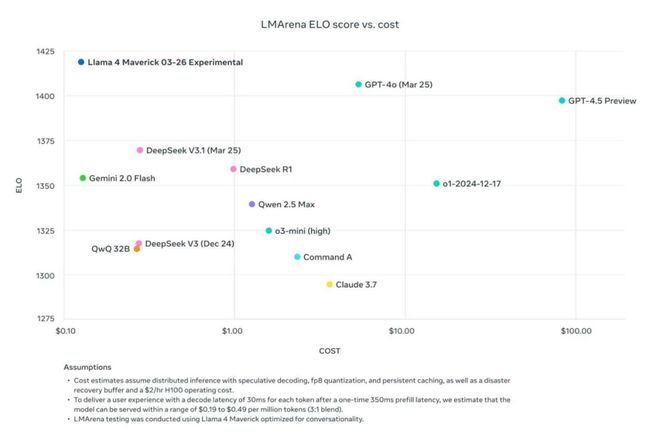
来源:Ahmad Al-Dahle 的X账号
我们可以从图片中看到 Llama 4 & Maverick 03-26 Experimental 和 GPT-4.0 (Mar 25) 位于图的右上角,表明它们具有较高的 ELO 评分和成本,意味着他们在性能上非常出色,但运行成本也相对较高;而 DeepSeek V3.1 (Mar 25) 和 DeepSeek RT 位于图的中间偏上位置,处于中等偏高的 ELO 评分和成本,因此,DeepSeek 可能在性能和成本之间的平衡比较好。最后,Qwen 2.5 Max 和 a3-mini (high)位于图的左下角,显示出较低的 ELO 评分和成本,意思是这类模型可能在性能上不如高成本模型,但运行成本较低,可能更适合预算有限的应用场景。不过,图中也列了一些可能会影响模型性能和成本的假设条件,如分布式推理、特定硬件配置、缓存等。以上测试结果也可能已经受环境影响得到优化。
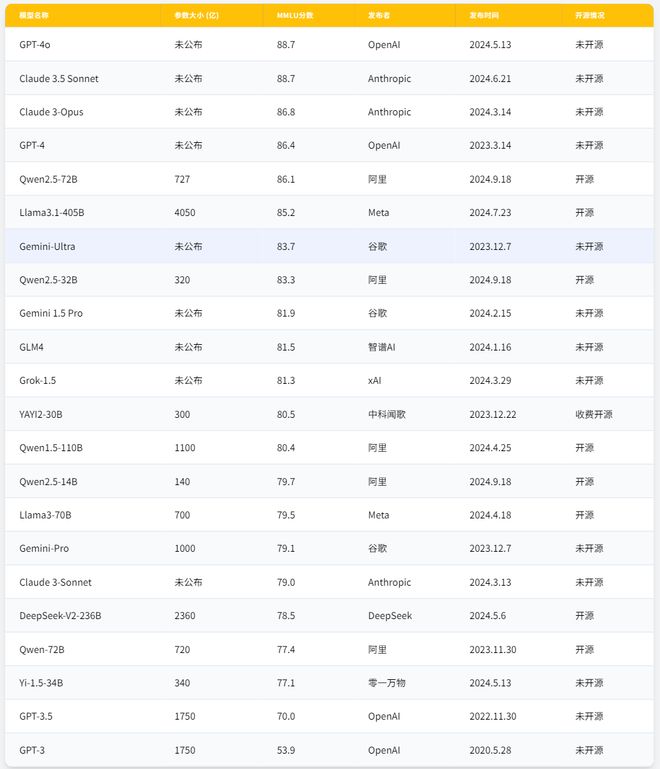
图:主流大模型信息对比来源:国信证券《电子 AI+ 系列专题报告(六)——DeepSeek 重塑开源大模型生态,AI 应用爆发持续推升算力需求》
2、MMUL/s分数
根据国信证券汇总报告中已测试过的 MMUL/s分数,这三大模型均在开源领域处于领先地位,且性能已能与部分闭源模型匹敌:
·Llama3-405B 达到了 85.2 分,性能卓越
·Qwen2-72B 更是达到了惊人的 86.1 分,在开源模型中处于顶尖水平
·DeepSeek-V2-236B 也取得了 78.8 分,在保持大规模的同时兼顾了效率
高 MMUL/s分数意味着模型在推理任务上具有更高的效率和更快的响应速度,对实际应用,尤其是需要低延迟和高并发的商业场景至关重要。
在 Meta-Llama 官网中,我们看到它根据一系列不同语言的通用基准评估了模型性能,测试了编码、推理、知识、视觉理解、多语言和长上下文
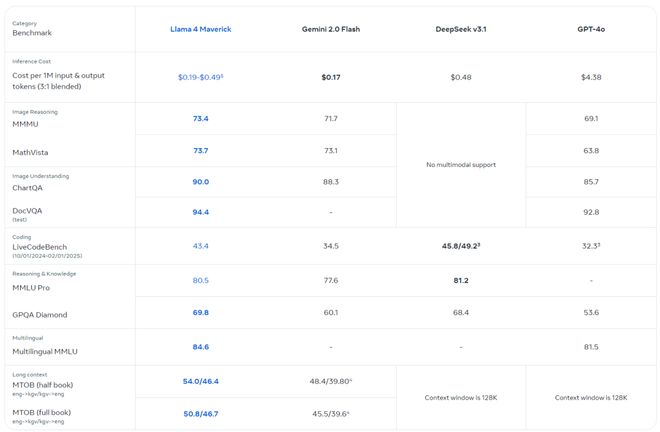
图:基准来源:Llama 官网
3、Artificial Analysis 发布的"AI 智能指数"
4 月 8 日,Artificial Analysis 更新了 AI 智能指数,该指数对目前领先的 AI 模型进行综合评估,结合了 MMLU-Pro、GPQA Diamond、Humanity's Last Exam 等七项严苛的基准测试。在此次的结果中,Llama 4 系列模型表现尤为抢眼,逼近榜首。
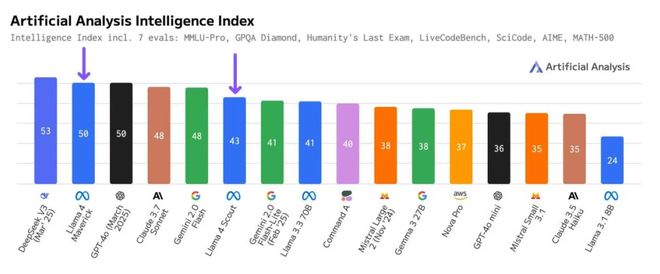
图:Artificial Analysis Intelligence Index 来源:Artificial Analysis 的X账号(4 月 8 日)
根据 Artificial Analysis 的最新数据,Meta 的 Llama 4 Scout 和 Llama 4 Maverick 模型在智能指数上取得了显著进步。Llama 4 Scout 指数从 36 跃升至 43,而 Llama 4 Maverick 则从 49 提升至 50。
值得注意的是,在最初的评估中,Artificial Analysis 发现他们测量的结果与 Meta 声称的 MMLU Pro 和 GPQA Diamond 分数存在差异。进一步实验审查后,他们调整了评估原则,允许 Llama 4 模型在回答多项选择题时,即使答案格式与预期不同(例如,以"最佳答案是 A"的形式),只要内容正确,也视为有效答案。尽量避免不公平地惩罚那些以不同风格呈现答案但内容正确的模型,进而更准确地反映 Llama 4 系列的实际能力,这也就促成了 Scout 和 Maverick 智能指数的大幅提升。
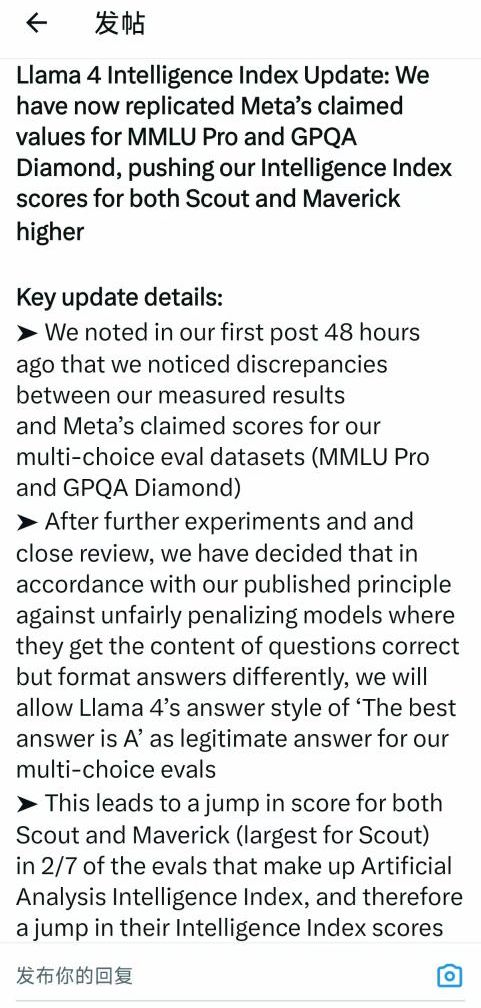
来源:Artificial Analysis 的X账号(4 月 8 日)
☆DeepSeek V3 仍领跑,但 Llama 4 Maverick 效率惊人
尽管 DeepSeek V3 (0324) 以 53 分的成绩仍保持微弱领先,但 Llama 4 Maverick(50 分)的表现同样令人印象深刻。Maverick 在参数效率上展现了巨大优势,即它仅使用了 DeepSeek V3 大约一半的活动参数(170 亿 vs370 亿),并且总参数量也只有 DeepSeek V3 的约 60%(4020 亿 vs6710 亿)。更难得的是,Maverick 还支持图像输入。Llama 4 Maverick 可以在更精简的体量下实现接近顶级性能的能力,对那些追求高效部署和资源优化的开发者来说,无疑是吸引力满满呀。【备注:Artificial Analysis 强调,所有测试均基于 Hugging Face 发布的 Llama 4 权重版本进行,并通过一系列第三方云服务提供商进行了测试,以确保评估的公正性和广泛性。他们特别指出,评估结果不基于 Meta 提供的实验性聊天调优模型(Llama-4-Maverick-03-26-Experimental),强化评估的独立性。
用户数据对比
DeepSeek 的全球表现令人惊艳,根据 aitools.xyz 在 2025 年 5 月发布的"最受欢迎 AI 工具"榜单,DeepSeek 成功位列全球第四名,月访问量达到 580,248 次,环比增长 1.32%。DeepSeek 的 Web 流量增长轨迹更是有说服力,2024 年全年 DeepSeek 的 Web 总访问量为 2140 万次,独立访问量 545 万次;至 2025 年 5 月,DeepSeek 的 Web 总访问量飙升至 4.261 亿次,独立访问量达到 7250 万次。惊人的数据表明 DeepSeek 在不到一年的时间里,其总访问量实现了近 20 倍的惊人增长,独立访问量也增长了约 13 倍。进一步看,DeepSeek 在全球开源大模型市场的应用份额不断扩大。
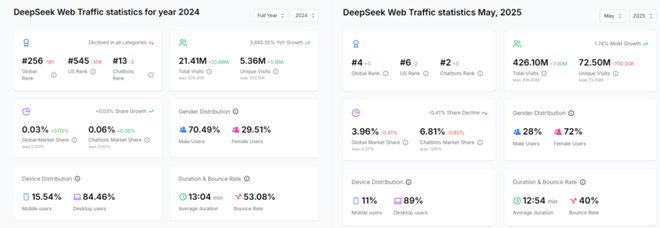
图:DeepSeek web 流量数据统计(左:2024 年全年,右:2025 年 5 月)来源:aitools.xyz
再来看 Llama,在今年 3 月时,副总裁 Ahmad AI-Dahle 发文祝贺 Llama 下载量超 10 亿次,根据相关数据,这比 2024 年 12 月初报告的 6.5 亿次下载量有了显著增长,在短短三个月内增长了约 53%。
它在 2024 年全球总访问量达到 233.02K,独立访问量为 165.72K,相较于此前分别增加了 120.59K 和 77.57K,实现了高达 107.26% 的同比增长,在大型语言模型市场份额上,从之前的基础增长了 0.12%,达到了 0.22%。2025 年 5 月,Llama 的 Web 流量轨迹出现了显著的下行趋势。该月总访问量降至 15.33K,独立访问量为 12.53K,相比此前分别减少了 7.66K 和 7.91K,月环比下降了 33.33%。这一骤降也反映在其市场地位上,大型语言模型的市场份额回落至 0.14%,下降了 0.09%。尽管全球排名略有改善(从 2779 上升至 2669),但美国排名和大型语言模型排名仍在持续下降,这可能预示着在关键市场和核心领域竞争的加剧。
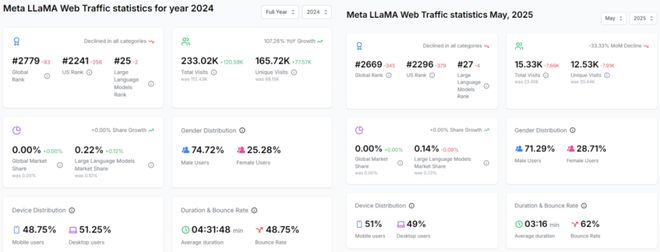
图:Meta Llama 流量数据统计(左:2024 年全年,右:2025 年 5 月)来源:aitools.xyz
此外,我们还对比了三家在 GitHub 上的星标数和 fork 数,这是 GitHub 上衡量项目受欢迎程度和参与度的两个重要指标。星标数代表了项目受到的关注程度,用户可以通过点击项目页面上的"Star"按钮来为项目添加星标。
来源:GitHub"Meta-Llama"
来源:GitHub"QwenLM"
来源:Github"DeepSeek-ai"
在关注者数量上,DeepSeek 以 78k 遥遥领先,显示出其在多模态理解领域的广泛影响力。Meta Llama 和 Qwen 虽然在关注者数量上不及 DeepSeek,但它们的项目同样在各自的领域内具有显著的影响力;在项目受欢迎程度上,DeepSeek 的 DeepSeek-V3 和 DeepSeek-R1 项目星标数远超其他两个组织,显示出其在社区中的极高人气。Meta Llama 的 llama 和 llama3 项目也表现出色,其在语言模型领域有强大的吸引力,Qwen 的星标数则相对较低;在项目多样性上,DeepSeek 的项目更侧重于多模态理解,Meta Llama 的项目集中在语言模型的开发和应用。而 Qwen 则在大语言模型和多模态模型方面有着更多的探索。
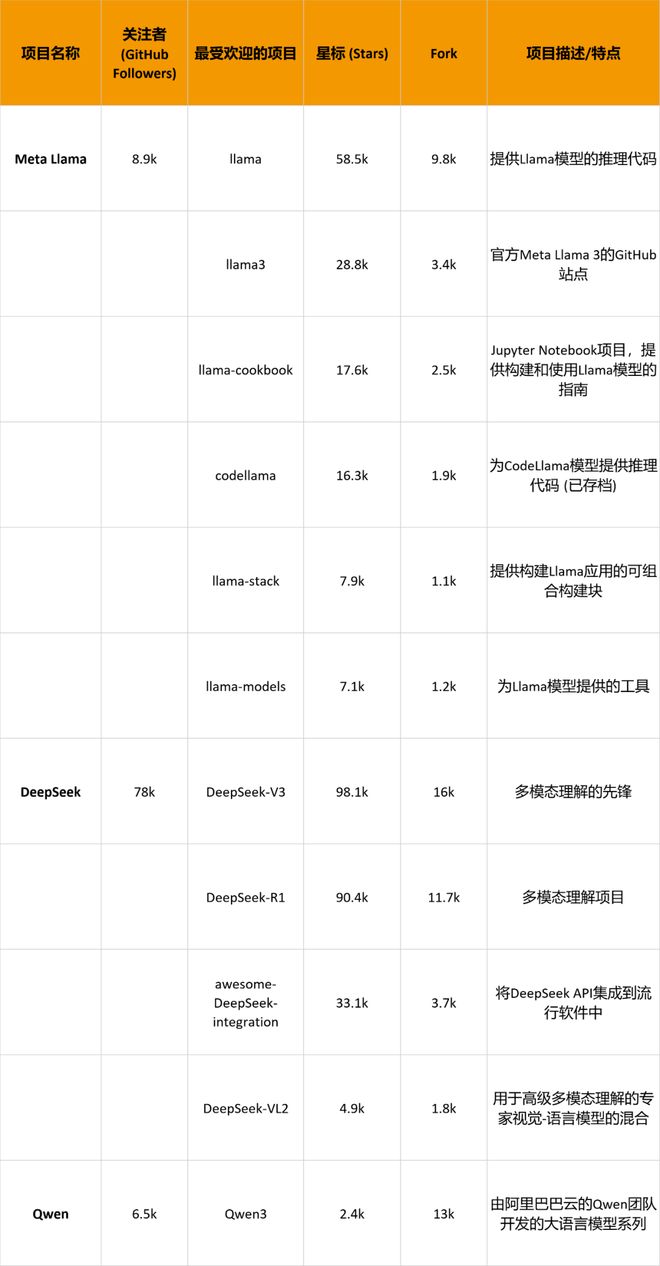
整体来看,DeepSeek、Qwen 和 Llama 在 GitHub 上的表现各有千秋,它们分别在多模态理解、大语言模型和语言模型领域展现了强大的技术实力和创新能力。Llama 的成功在于其极致的开放策略和强大的全球社区凝聚力;DeepSeek 则以其惊人的技术迭代速度和在全球用户侧的爆发式增长,迅速崛起为中国乃至全球开源大模型领域的一股重要力量;而 Qwen 则凭借阿里巴巴的强大生态支持和在国内市场的深厚根基,成为中国 AI 应用领域的核心引擎。随着技术的不断进步,我们可以预见这些模型持续赋能千行百业,但是不断优化模型架构、提升推理效率的同时,实在应当更加注重用户隐私和伦理问题。






