
新智元报道
编辑:LRST
MMLU-CF 是一个无污染的多任务语言理解基准测试,旨在更公平、准确地评估大语言模型的能力。通过去污染规则和闭源测试集防止数据泄露,确保评估结果可靠。该基准包含 20,000 道题目,涵盖 14 个学科,验证集公开透明,测试集闭源防泄露。
近年来,随着大语言模型(LLM)的不断进步,如何准确评估其能力已经成为研究的热点问题。
诸如大规模多任务语言理解基准 MMLU(Massive Multitask Language Understanding),在评估大语言模型中起到重要作用。
然而,由于开放源代码和训练数据的多样性,现有基准测试难免存在数据污染问题,影响评估结果的可靠性。
为了提供更为准确、公平的评估,微软亚洲研究院推出了 MMLU-CF,它是基于公开数据源,经过去污染设计的大语言模型理解基准,并已在 Huggingface 上开放。
MMLU-CF 是一个「无污染」的、更具挑战性的多项选择题基准数据集。

论文链接:https://arxiv.org/pdf/2412.15194
代码链接:https://github.com/microsoft/MMLU-CF
数据连接:https://huggingface.co/datasets/microsoft/MMLU-CF
数据集包含 20,000 道题目,分为 10,000 道验证集题目和 10,000 道测试集题目,其中验证集开源,测试集闭源,涵盖健康、数学、物理、商业、化学、哲学、法律、工程等 14 个学科领域。
MMLU-CF 为大语言模型的评估提供了一个更加公平和可靠的基准,不仅帮助研究者准确理解模型的能力,也为未来模型优化提供了宝贵的数据支持。
MMLU-CF 的贡献
消除数据污染
传统基准测试可能存在数据污染,影响评估的公正性。MMLU-CF 通过引入三条去污染规则并扩展数据源,确保测试结果更可靠。
防止恶意数据泄露
研究人员将数据集分为验证集和测试集,确保测试集保持闭源,避免数据泄漏引发的不公正结果。同时,验证集开源以促进透明度,便于独立验证。
对比结果
评估结果显示,OpenAI o1 在 MMLU-CF 测试集上的5-shot 得分为 80.3%,显著低于其在 MMLU 上取得的 92.3% 得分,表明了 MMLU-CF 基准的严格性。
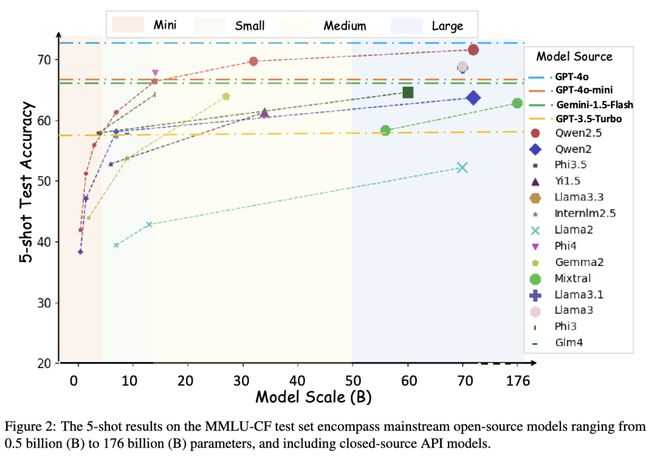
图 1 主流大模型在 MMLU-CF 的测试集的5-shot 得分表现
基准对比
MMLU 与 MMLU-Pro基准测试主要关注任务的广度、推理能力和难度,但未考虑数据污染问题。
对于 MMLU-CF,研究人员在数据收集时应用了去污染规则,确保避免数据泄露,同时将测试集保持闭源,防止恶意泄露。
以下是几款主流模型在 MMLU 与 MMLU-CF 数据集上的表现与排名变化:
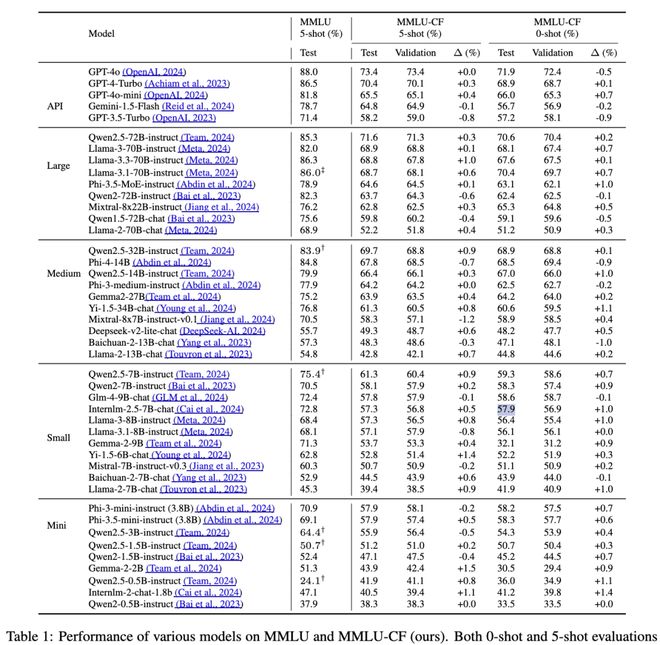
图 2 主流大模型在 MMLU-CF 和 MMLU 上的表现与排名
新的基准 MMLU-CF 扰乱了已评估的语言模型(LM)在 MMLU 上的性能排名。
排名前三的语言模型:OpenAI o1、Deepseek-R1 和 Deepseek-V3 ,保持了领先地位,排名没有任何变化。
有趣的是,在显著的排名变化(>=3 位)中,排名下降的往往比上升的更为显著。
平均而言,排名下降的语言模型下降了 5.14 位次,而排名上升的语言模型上升了 3.78 位次。
这种不对称性表明,性能大幅下降比上升更容易,这可能是由于预训练语料库中的数据污染造成的。
与规模较大的语言模型相比,规模较小的语言模型在新的 MMLU-CF 基准测试中似乎更具破坏性。
测试集与验证集的划分
在 MMLU-CF 中,研究人员将数据集划分为测试集和验证集,并通过计算「绝对分数差异」评估模型的泛化能力。统计结果显示,约 60% 的差异值小于 0.5,96% 的差异值低于 1.0,表明测试集和验证集的评估结果高度一致。

图 3 数据构建流程图
MMLU-CF 的数据构建包括以下几个步骤:
1. 题目收集:从广泛的开放互联网域收集问题,保证问题的多样性。
2. 题目清洗:确保收集到的问题质量高,适合用于评估。
3. 难度采样:确保问题的难度分布合理。
4. 大模型检查:使用 GPT-4o、Gemini、Claude 模型对数据的准确性和安全性进行检查。
5. 去污染处理:通过去污染处理,确保数据集的无污染性。
最终,MMLU-CF 数据集分别包含了 10,000 道测试集域验证集题目,同时测试集保持闭源,验证集则公开以保证透明性。
去污染处理规则
为了避免无意中的污染并评估模型的推理和理解能力,研究人员采用了三条去污染规则:
·规则1:改写问题,减少模型对已见数据的依赖。
·规则2:打乱选项,避免模型通过记忆选项顺序做出正确答案。
·规则3:随机替换选项,增加模型的推理难度。
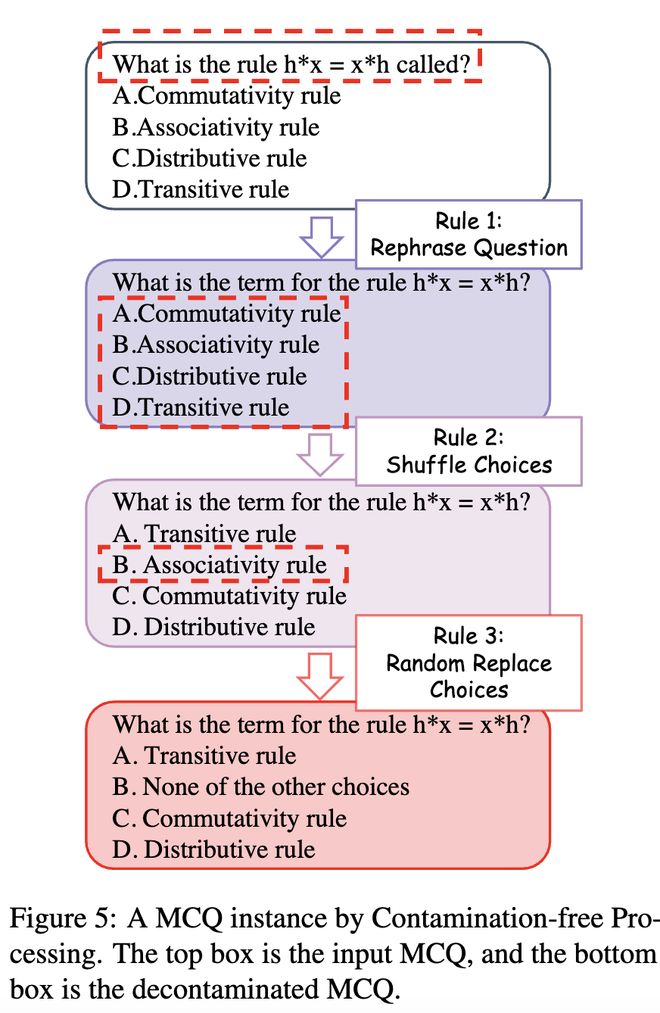
图 4 去污染示例
这些规则有效减少了恶意和无意的泄漏风险,确保了数据集的「无污染」性。
参考资料:






