
新智元报道
编辑:Aeneas
AI 做奥数的神话,刚刚被戳破了!最新出炉的 2025 IMO 数学竞赛中,全球顶尖 AI 模型无一例外翻车了。即便是冠军 Gemini 也只拿下可怜的 31 分,连铜牌都摸不到。Grok-4 更是摆烂到底,连 DeepSeek-R1 都令人失望。看来,AI 想挑战人类奥数大神,还为时尚早。
如果你以为,如今的 LLM 已经无所不能,那刚刚出炉的 2025 大模型数学竞赛结果,恐怕要让你大跌眼镜了。
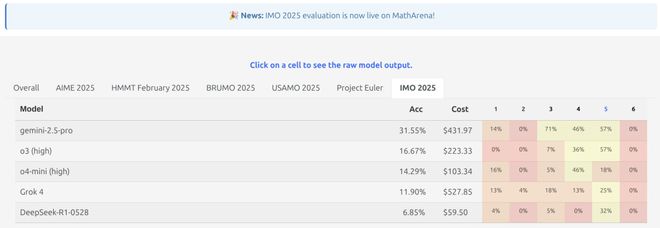
现在,各模型的分数已经在 MathArena 上发布。
怎么说呢,所有大模型都翻车了。
即使得分最高的冠军 Gemini,也只拿到了 31% 的分数。凭这个成绩,连拿铜牌都不大可能。
也就是说,AI 想超越目前顶级的人类数学选手,还差得远呢。

苏黎世联邦理工学院 SRI 实验室的博士生 Jasper Dekoninck,发了一篇博客记录此次大赛的详细过程。

大模型参加数学竞赛,全部翻车!
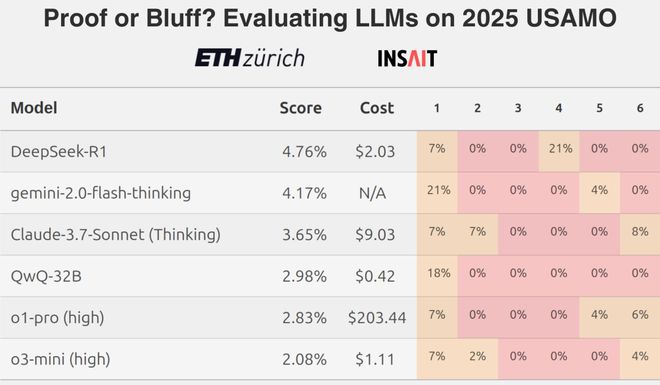
在今年 4 月,来自 ETH Zurich 等机构的 MathArena 团队,就曾推翻 AI 会做数学题这个神话。

而在这届 2025 国际数学奥林匹克(IMO)上,全球的 AI 顶流们又齐聚一堂了。
为了测验 AI 们的数学能力天花板,MathArena 项目组这次祭出了数学界的终极 boss——2025 年 IMO 真题。
国际学生奥林匹克竞赛(IMO)是全球 18 岁以下数学学生的顶尖赛事。参赛者都经过了大量训练,每道题都有数小时的解答时间。
IMO 真题是什么水平呢?它们能难倒全球数学能力最顶尖的高中生,甚至还能分分钟劝退无数大学数学教授。
在 2024 年,美国队的六名参赛者得分在 87-99% 之间。而陶哲轩在 13 岁时,就获得了 IMO 的金牌。

这次,组委会希望了解,这些大模型是否能达到拿到奥数奖牌的里程碑级别,比如铜牌(前 50%)、银牌(前 25%)甚至金牌(前8%)。
另外,为了防止「开卷作弊」这个问题,评测团队特意选了一个巧妙的时间:题目刚刚发布,他们就开始让 AI 们答题了,所以这些大模型不太可能在数据集中提前见过这些数学题。
可以说,这些基准测试是既未受污染,又是可解释的。
而 AI 们的所有答案,都是由两位奥数专家评委双盲评分的,标准的严苛程度堪比 IMO 官方。每道题满分 7 分。
此次的参赛选手,阵容也是空前豪华,堪称是 AI 界的梦之队。
· o3(OpenAI 扛把子)
· o4-mini(OpenAI 小钢炮)
· Gemini 2.5 Pro(谷歌第一大将)
· Grok-4(马斯克家的理工男)
· DeepSeek-R1(国产尖子生)
之所以选择这五位参赛选手,是因为它们此前都在 MathArena 中有出色的表现。
其中,每个模型都使用推荐的超参数运行,并且设置了 64000 的最大 token 限制。
Prompt 如下——
你的任务是为以下问题写出一个证明解决方案。你的证明将由人工评委根据准确性、全面性和清晰性进行评分。在撰写证明时,请遵循以下指南:
-你正在撰写一份证明,而不是证明大纲。每一步都应该仔细解释并记录。如果解释不充分,评委将认为你无法解释清楚,从而降低你的分数。
-你可以使用通用的定理和引理,但前提是它们必须是众所周知的。一个简单的判断标准是:如果该结果有名称,并且足够有名以至于有维基百科页面或类似的内容对其进行描述,则允许使用。任何来自论文的结果,如果它不会在高中或本科低年级数学课程中教授,则不应使用。任何此类结果的使用将立即导致你的成绩为零。
-在你的证明中不要跳过计算步骤。清楚地解释做了哪些变换,以及为什么在计算的每一步中这些变换是被允许的。
-你应该使用正确的 LaTeX 符号来编写公式和数学符号。你应当将这些公式包含在适当的符号中(行内公式使用 "\\(" 和 "\\)",块状公式使用 "\\[" 和 "\\]"),以增强证明的清晰度。不要使用任何 Unicode 字符。
-你的证明应该是自包含的。
-如果你对某个具体步骤不确定,或者不知道如何证明一个中间结果,请明确说明。指出你的不确定性比做出错误的陈述或主张要好得多。
为了公平,项目组这次采取了一种「best of 32」的策略。
也就是,每道题都会跑出 32 个不同答案,然后让 AI 自己当裁判,通过一轮轮 PK 选出最强解法后,才会送去给人类评审打分。这样,模型在推理时,就会尽可能多地扩展计算资源。
因此,这次比赛可以说不仅是卷得离谱,烧钱也烧得令人心疼——
比如,Grok-4 的单题评测成本就高达 20 美元,所以 24 题的总成本,就超过了 480 刀!
所以,大模型们的表现如何?
金银铜,全军覆没
Gemini 2.5 Pro,全场最高分
Gemini 2.5 Pro 在满分 42 分的考卷中,拿到了 13 分,约等于 31%。
这个分数,连铜牌的门槛都没摸到。
而即使是作为表现最好的 AI,Gemini 也依然有不少毛病。
比如,遇到不会做的题时,它会编出一些看起来似乎很权威的假定理,比如「根据史密斯-约翰逊超平方引理可得」。
但实际上,这个定理根本就不存在!


此前 Gemini 2.5 Pro 的答题情况
Grok-4:翻车最严重,基本没救了
而最近因为 AI 女友事件大出风头的 Grok-4,则严重翻车了。
它的表现堪称灾难:它给出的绝大多数答案只有最终结果,完全不解释,整个就是一副「我懒得证明,我就是知道」的摆烂态度。
而显著落后的一个选手除了 Grok-4,还有 DeepSeek-R1。
这两个 AI 在此次奥数中的成绩,相较于它们在 MathArena 基准测试中的早期成绩,退步明显。

此前 Grok 3 mini 的答题情况
AI解题的独特姿势:做不出来,我就跳过
在这个过程中,研究者们还发现了 AI 做数学题的一个有趣现象。
通常,在人类选手参加 IMO 比赛时,他们要么一题全部做对,要么干脆拿 0 分,拿 3 分、4 分这样的中等分数,其实是很少见的。
不过大模型可就完全不一样了,它们特别擅长考个「及格边缘线」。
也就是说,它们时常能捕捉到正确的解题思路,方向是对的,但是一到最关键的地方就会掉链子,逻辑跳跃严重。
尤其是到了该证明的关键一步,它们就不证明了。而这恰恰是人类选手最不容易出错的地方。
对此,评审组的感受是:AI 现在已经能抓住「人类感」的思路,但是在细节能力上,还是差点火候。
而如果 AI 们能把这些逻辑问题给搞定,未来它们的成绩说不定还真能冲上领奖台。

此前 DeepSeek-R1 的答题情况
2025 IMO 真题
我们来看看,今年几道 IMO 真题长什么样子。
问题1:

问题2:
问题3:

问题4:

问题5:

问题6:

AI 离成为奥数大师,究竟还有多远?
也许你会有疑问,自己平时测这些大模型的时候,做数学题并没有这么强啊。
原因当然就在于,这次大模型们的「Best-of-32」大法了,如果不是用了这个策略,很多模型的得分连 10 分都没有。
这也就揭示出这样一个现实:想要让模型发挥得好,就得拼资源、拼算力、拼试错次数。
如果只是普通用户随便跑一遍模型,根本不可能达到这种效果。
总之,这场「AI 数学奥赛」,已经暴露出了很多关键问题。比如想法没问题,但存在逻辑链的短板;会判断解法质量,但还得靠大量计算。
或许再过几年,某个 AI 真的能打出满分 42 的神级操作,但显然,今天的 AI 还达不到这个成就。
目前来说,人类数学选手们还是安全的,还可以放心睡个好觉。
参考资料:






