
新智元报道
编辑:桃子好困
ACL 首届博士论文奖公布了,UC 伯克利助理教授 Sewon Min 摘桂冠!开幕式上,组委会公开了今年参会背景,提交论文的中国作者占全世界一半。ACL,如今成了中国的顶会?
ACL 2025 在维也纳开幕了!
今年的 ACL,可谓是座无虚席,盛况空前。开幕式上,组委会公布了今年参会的具体情况。

值得一提的是,论文里的中国作者已经占据了半壁江山,比例超过 51%。
其中,第一作者有高达 51.3% 来自大陆,排在第二的美国仅为 14%。
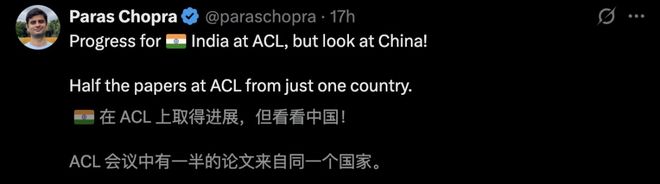

ACL 今年整体情况如下(主会议部分):
· 1,700 篇主会论文,1,400 篇 Findings 论文,108 篇产业论文
· 17 篇 CL(Computational Linguistics)论文,40 篇 TACL(Transactions of ACL)论文
· 2 场主旨演讲,1 场专家小组讨论
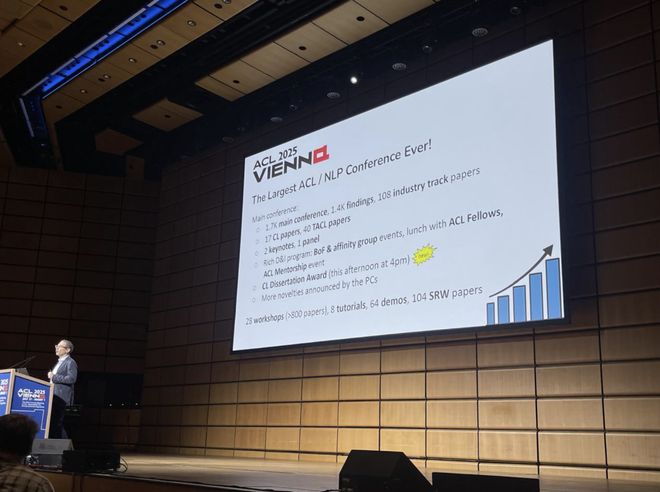
此外,顶会附属活动还包括:28 场 workshop(投稿超 800 篇),8 场教程(tutorial),64 演示(demo),104 篇学生研究工作(SRW)论文。
同在今天,首届 ACL「计算语言学博士论文奖」正式公布了。
来自 UC 伯克利 EECS 助理教授 Sewon Min,因论文 Rethinking Data Use in Large Language Models 斩获大奖。
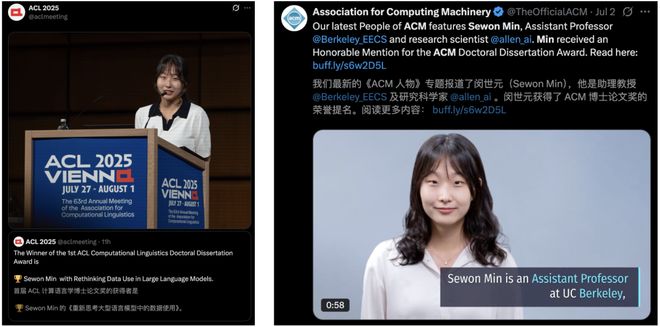
7 月初,她曾获得了 ACM 博士论文奖荣誉提名
ACL 成了中国顶会?
作为 NLP 领域A类顶会之一,ACL 每年汇聚了世界各地学者,今年是第 63 届年会。
回看过去十年,ACL 总论文提交量增长了 10 倍,过去 5 年增长了 4 倍。
今年,顶会共提交了 8360(8350)篇论文,其中主会录用率为 20.3%,共有 1699 篇论文。Findings 录用率为 16.7%,共有 1392 篇论文。
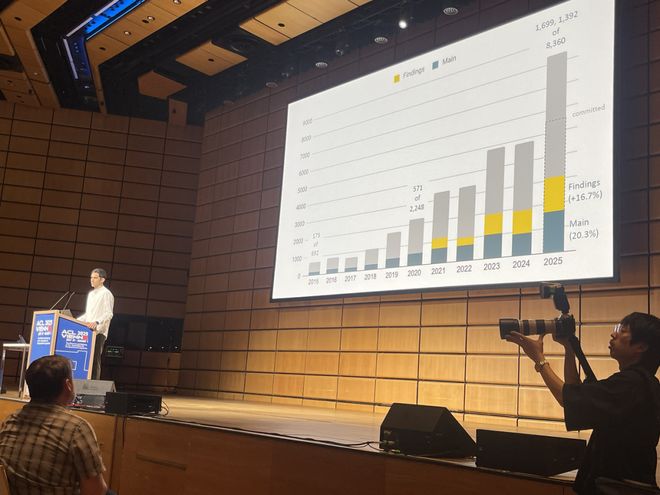
相较于去年,论文总提交数量上涨了 70%,审稿人共有 5903 人,上涨了 38%。
更有趣的是,ACL 桌拒比率比 24 年飙升 160%。

从提交论文研究的领域来看,NLP 应用(13.1%)位列第一,资源和评估占比 12.4%,还有多模态和语言 Grounding、语言建模等领域,成为了研究重点。
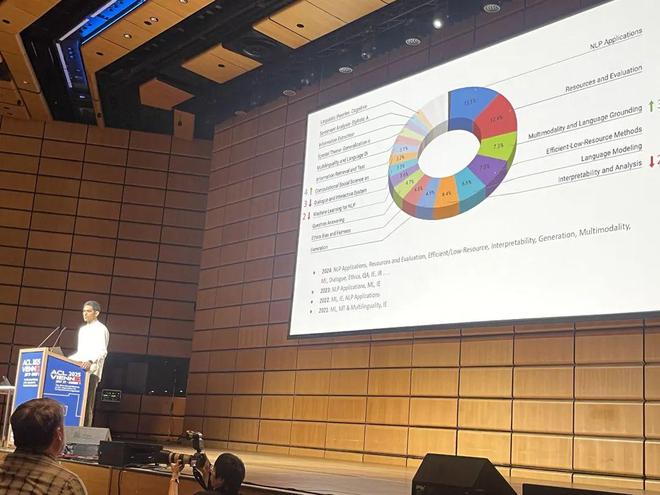
其他一些数据统计:
-
67% 的论文标题和摘要中有「LLM」一词,其中9% 提及了 GPT,8% 提及了 Llama,还有2% 论文提及了 DeepSeek、BERT、Gemini/Gemma。
-
50 位作者提交了超过 10 篇论文,23% 的作者提交了超 2 篇论文。
-
250 篇论文有超 10 位作者,仅一位作者论文有 20 篇。
-
65% 的论文标题里都有「:」!

目前,ACL 最佳论文奖暂未公布,今年首次公布了「计算语言学博士论文奖」。
ACL 首届博士论文奖
这篇获奖论文 Rethinking Data Use in Large Language Models,于 2024 年发表,全文长达 157 页,是华盛顿大学 Sewon Min 的博士毕业论文。
ACL 组委会点评,这篇论文为大模型的行为和能力提供了关键见解,特别是在上下文学习方面。
其研究结果,对当今 NLP 的核心产生了影响。

论文地址:https://www.sewonmin.com/assets/Sewon_Min_Thesis.pdf
总的来说,这篇研究核心,重点围绕 LLM 如何利用训练时使用的的大量文本语料库。
首先,作者揭示了这些模型在训练后学习新任务的内在机制——其所谓的上下文学习能力几乎完全取决于从训练数据中获取的知识。
接着,她又提出了一类新型非参数化语言模型。
它们将训练数据重新定位为可检索的信息数据库,从而显著提升准确性与可更新性。
在此过程中,作者还开发首批广泛应用的神经检索模型之一,以及将传统两阶段流程简化为单阶段的创新方法。
研究表明,非参数化模型为负责任的数据使用开辟了新途径。比如,通过对授权文本与受版权内容的分类差异化处理。
最后,Sewon Min 对下一代语言模型的发展方向作出展望,强调高效 Scaling、事实性增强、去中心化架构这三大核心目标。

7 月初,她的这篇论文,还获得了 ACM 博士论文荣誉提名。在接受 ACM 采访中,她首次畅谈了选择 LLM 领域原因,以及对当前 AI 领域的一些看法。
以下内容,为采访部分截取:
Q:你是如何决定将 LLM 作为研究方向的?
NLP 领域的研究者长期致力于构建「通用模型」——无需针对特定任务训练就能处理多种任务。
当大语言模型出现时,其技术路径是通过海量数据的自监督训练来构建巨型模型,从而消除对人类监督的依赖。
这似乎为实现该目标指明了一条道路。
这个理念简单得令人沮丧,却揭示了诸多关键要素:数据质量与规模的核心作用、对人类先验知识的最小化依赖、以及消除人工标注环节。以上是官方回答。
老实说,这个领域听起来就令人兴奋,而且研究过程充满乐趣。如今该领域能产生如此广泛而深远的影响,我感到非常幸运。
Q:你在近期演讲中提到,当前 LLM 生成人物传记时,事实错误率高达 42%。为何会出现这种情况?
我认为这与当前 LLM 基于记忆训练数据的底层机制有关。
对于知名人士,模型能生成准确传记,因为相关高频出现于训练数据中;但对于曝光不足的对象,模型往往无法准确回忆,转而生成看似合理实则错误的文本(即幻觉现象)。
这反映了此类模型数据学习机制的核心局限。
Q:你在「非参数化」大语言模型领域取得突破性成果。能否举例说明非参数化大语言模型与标准大语言模型在生成响应时的区别?
标准大语言模型常虚构事实。例如,当我询问无法联网的 ChatGPT「首尔有哪些米其林三星餐厅」时,它错误列举了二星餐厅 Gaon 和已歇业的 La Yeon,甚至编造营业时间——这反映出记忆知识的过时与缺失。
而非参数化大语言模型会从实时更新的数据存储中检索文档(如 2025 年提到首尔唯一三星餐厅 Mingles 的文章),并基于这些文档给出正确答案。
作者介绍

Sewon Min 是加州大学伯克利分校电子工程与计算机科学系的助理教授,同时也是艾伦人工智能研究所的研究科学家,并隶属于伯克利人工智能研究实验室和伯克利自然语言处理研究组。
她的研究方向是自然语言处理和机器学习,特别是在大语言模型领域——致力于深入理解并推动模型的发展,重点研究如何利用海量的文本语料库。
此前,她在华盛顿大学获得计算机科学与工程博士学位,在首尔大学获得计算机科学与工程学士学位。曾担任 Meta FAIR 的兼职访问研究员,并先后在谷歌研究院和 Salesforce 研究院实习。

参考资料:






