鹭羽发自凹非寺
量子位 | 公众号 QbitAI
无需谷歌“钞能力”,两位清华校友强强联合,直接让基础模型 Gemini 2.5 Pro 轻松达到 IMO 金牌水平。
只需提示词改动……

该发现来自两位清华校友杨林和黄溢辰,他们共同设计了一套自我迭代验证流程和提示词优化,就成功让 Gemini 2.5 Pro 完成了今年 IMO 题目的解答。
他们还刚刚更新了代码,直接利用通用提示词就能实现模型推理增强。

好家伙,原来我们都被 LLM 骗了,基础大模型早就弯道超车,具备超强的解决复杂数学推理问题的能力。
只不过,直接用效果并不好。
就像 MathArena 也用 Gemini 2.5 Pro 跑了本次 IMO 题目,结果只有13 分,远低于 IMO 铜牌门槛(19/42)。

但只要加一点点提示词魔法和迭代验证,就能实现1+1>2。
这一点也受到了陶哲轩的认可:
我认同严格验证是在复杂数学任务中取得出色表现的关键。
具体是怎么做到的?我们接着往下看。
通用提示词+迭代验证
首先为什么最近 AI 模型都喜欢参加 IMO 测试呢?
其实是因为相较于面向中小学水平题目的传统数学基准 GSM8K、MATH 等,IMO 可以更为充分地考验模型的抽象思维和多步骤逻辑推理能力,堪称检验 LLM 推理能力的“试金石”。
不过前几年模型结果都不尽如人意,要么是无法理解题目要求,要么是“偏科”某一类问题。
直到今年才首次有官方认可的金牌 AI 出现,谷歌和 OpenAI 均完成了 5 道题,其中谷歌 Gemini 模型搭载了新的 Deep Think 模式,OpenAI 的模型据悉也是在通用强化学习和计算扩展方面实现了技术突破。
但现在,研究团队只用提示词设计,就达成了上述效果。
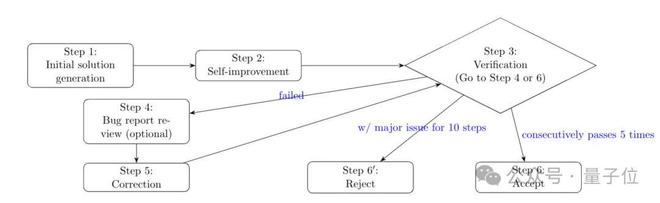
关键在于,他们设计了一套自我验证流程,依次可分为六个步骤:
- 初始解决方案生成:模型首先根据提示词生成初步解答,要求每一步逻辑推理清晰、解释明确。
- 自我改进:模型对初始答案进行回顾和优化,弥补初始生成中因思维预算有限导致的不足。
- 验证解决方案并生成错误报告:在验证器中根据提示词验证解答,生成包含关键错误(如逻辑谬误或事实错误)和不完整论证在内的问题报告。
- 审查错误报告(可选):对问题报告进行复核,删除误报的问题,提升报告可靠性。
- 基于错误报告纠正或改进解决方案:根据问题报告改进解答,修正后返回验证步骤。
- 接受或拒绝解决方案:若解答连续 5 次都通过验证,则接受该回答;若连续迭代 10 次,都存在重大问题,则拒绝此答案。
具体来说,整个过程是由 Gemini 2.5 Pro 构成的求解器(solver)和验证器(verifier)执行,采用差异化提示词以达到不同作用。
其中求解器主要负责生成和改进答案,在提示词设计上将严谨性设为首要目标,确保结果可严格验证。
但由于 Gemini 2.5 Pro 的最大思考 tokens 为 32768,在初始生成答案时无法独立完成负责的 IMO 问题,所以通过步骤 2 中的自我改进,额外注入 32768 tokens,让模型回顾并优化初始解答,提升整体质量。
然后使用验证器模拟 IMO 评分专家,进行迭代改进,并决定是否接受改进后的解决方案。
验证器会逐一检查解答并找出存在的问题,将问题分为关键错误和论证缺口两类,其中关键错误是指明显错误或存在清晰逻辑谬误的内容,会严重破坏证明的逻辑链条,引向错误答案。
论证缺口包含主要缺口和次要缺口,主要缺口可能会导致整个证明失败,而次要缺口可能会产生正确结论,但论证仍然是不完整的。
当发现问题后,验证器随即会输出一份错误报告,为模型改进解决方案提供有用信息,在步骤 4 中对验证器的误判进行改正,然后模型根据报告尝试改进答案。
由于验证器可能出错,所以需要足够次数的重复迭代,降低误判影响,最终如果答案能通过验证则接受,如果始终存在关键错误或主要论证缺口,则拒绝。

具体实验过程中,研究团队选择刚刚发布的 IMO 2025 题目,因为发布时间较短,可以有效避免训练数据污染,确保评估的真实性。
另外在参数设置上,选择较低的温度值0. 1,因为较高的温度可能会导致更多的随机错误,并使用 Gemini 2.5 Pro 的推理 token 上限,同时排除其它模型、代码干扰。
关键提示词中,初始生成的提示词要求有充分理由支撑答案,如果不能找到完整解决方案,不能进行编造,且所有数学内容用 TeX 格式呈现。

输出格式需严格按照总结到详细解决方案的顺序,其中总结包括结论和方法概述,详细解决方案中需要呈现完整、逐步的数学证明,在最终输出前还要仔细检查以符合所有指令。
在验证提示词里,唯一任务就是找出并报告解决方案里的所有问题,并不尝试纠正漏洞,需生成详细验证日志并将问题进行分类,输出格式包括总结和详细验证日志,总结又包括最终判定和发现列表。

最终,模型实现为 IMO 的 6 道题目中的 5 道生成了完整且数学严谨的解决方案,其中前两道题目各生成了有提示和无提示的两种解决方案。
第一题提示使用数学归纳法,第二题提示使用解析几何完成,通过对比可得,详细的提示词可以减少计算搜索空间、提高效率,但并不会额外赋予模型新的能力。
在未能解决的第六题上,研究人员发现模型是在其中一个有关证明时出现核心错误,从而导致后续证明无效。
实验结果证明,结构化迭代流程将是 LLM 的潜在能力转化为严谨数学证明的关键,可突破单次生成中例如有限推理预算和初始答案错误等局限性。
另外研究人员预计,如果混合使用多种模型,例如 Grok 4、OpenAI-o 系列,以及类似 Grok 4 heavy 的多智能体系统,可能会产生更强的数学能力。
清华校友强强联合
本次研究的两位作者——黄溢辰和杨林,他们是清华大学数学物理基础科学实验班的本科同学,毕业后又分别前往海外高校深造。

黄溢辰在加州大学伯克利分校取得物理学博士学位后,曾在微软担任 AI 研究员,后在加州理工学院担任博士后,师从凝聚态物理领域大拿陈谐教授。
陈谐教授本科同样毕业于清华大学,并在 2012 年获得麻省理工学院理论物理博士,目前是加州理工学院的 Eddleman 理论物理学教授。
主要研究的是量子凝聚态系统中的新型相和相变,包括强关联系统中的拓扑序、多体系统动力学、张量网络表示以及量子信息应用等。
曾在 2017 年斩获斯隆奖,后又因其对物质拓扑态及相互关系的卓越贡献,荣获2020 年物理学新视野奖,该奖项隶属于科学突破奖的子奖项,要知道科学突破奖也被誉为当代科学界的“奥斯卡奖”。
后续黄溢辰又接着在麻省理工学院理论物理中心和哈佛大学物理系继续从事博士后研究,主要研究方向是量子物理学,包括量子信息学、 凝聚态理论和机器学习。

另一位作者杨林,目前是加州大学洛杉矶分校的副教授,任职于电气与计算机工程系以及计算机科学系。

此前,他曾获得约翰霍普金斯大学的计算机科学和物理与天文学双博士学位,又曾在普林斯顿大学从事博士后研究,师从王梦迪教授。
王梦迪 14 岁就考入清华,23 岁就从麻省理工学院博士毕业,其导师还是美国国家工程院院士 Dimitri P. Bertsekas,年仅 29 岁就成为普林斯顿大学终身教授。
研究领域主要涉及生成式人工智能、强化学习、大语言模型等,2024 年还曾获得控制领域最高奖项 Donald P. Eckman 奖(每年仅颁发给一位获奖者)。
而杨林教授的研究重点则是强化学习理论与应用、机器学习和优化理论、大数据处理和算法设计等,他曾在 ICML 和 NeurIPS 等顶级机器学习会议上发表过多篇论文,还曾获得亚马逊教授奖、西蒙斯学者奖等。
有限的资源下,学术界也能比肩大厂
对于本次研究的相关细节,量子位也和杨林教授深入聊了聊。
首先是为什么会优先选择 Gemini 2.5 Pro 作为研究对象,杨林教授表示:
实验开始时 Gemini 相对比较方便,可调的参数较多。
而当谈及 Gemini 2.5 Pro 在解决前 5 道问题所涉及的计算资源和耗时,杨林教授也是坦然回应道:
具体资源我们没有仔细统计,但大致估算下,第一步大概需要 60000token,之后的每次验证,如果通过则 15000token,如果需要修改则需要 30000token。
每次由于随机性都会有所差异,不同题目需要的 tokens 数在 300k 到 5000k 都是有可能的,比如运气不好的时候,一道题目就做了 8 次独立实验。而计算时间则取决于谷歌服务器的空闲度,最快 10 分钟左右就能解出一道题。
关于使用提示前后模型的差异,杨林教授也表示:
当使用提示后,模型基本一次独立实验(Agent 输出失败或成功算一次独立实验)就能解决题目,但不使用模型的思维会发散,之前提及的 8 次独立实验就是在没有使用提示的情况下出现的。
至于没有成功解决的第六题,杨林教授认为主要问题还是出在验证器上:
当求解器输出假阳性答案时,验证器没能很好地区分一些细节。
目前团队已经进行了手动验证,自我检查了证明的所有细节,但缺乏官方评分,杨林教授也希望如果组委会有兴趣,他们很乐意参与 IMO 官方评分,进一步验证解答。
未来他们也将会通过使用更多训练数据进行预训练和微调,以提升基础模型的能力。
之后杨林教授也分享了一些本次研究中他所收获的心得体会:
有时候基础模型的能力需要用其它方法释放,如果未来模型训练达到瓶颈,那么 Agent 方法可能是破局的关键。而本次研究也让我们看到,学术界利用有限的资源,也能做出与大厂同等重要的成果。
他也希望 AI 在未来能在数学研究中扮演更为重要的角色,尤其是在一些长期悬而未决的问题上。
最后也帮读者朋友们向教授询问了一些与 AI 共存的建议,杨林教授相当谦虚地表示:
同学们比我年轻,对 AI 的使用可能比我更加自然,所以我提不出什么建议。但就我自身而言,我希望在使用 AI 的同时,也能提高自身的知识水平。
简而言之就是,使用并向它学习。
论文链接:https://www.alphaxiv.org/abs/2507.15855v2
参考链接:
[1]https://x.com/ns123abc/status/1948223115437154372






