
智东西
编译陈骏达
编辑李水青
全网首份 GPT-5 聊天记录曝光了!
智东西 8 月 4 日报道,今天,OpenAI 首席执行官 Sam Altman 在X平台上发出了 GPT-5 的对话记录,提前剧透了 GPT-5 的使用体验。
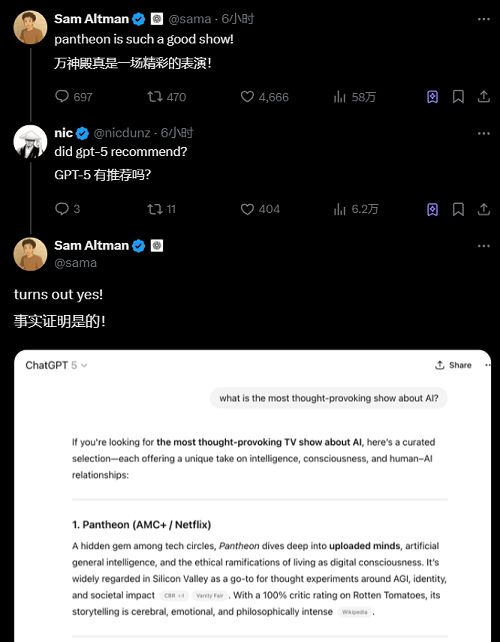
对话中,Altman 让 GPT-5 给他推荐几部以 AI 为主题、最引人深思的电视剧,GPT-5 向 Altman 发送了一部片单,位列第一的正是 Altman 发文推荐的美剧《万神殿(Pantheon)》。

Altman 还发推称,软件即服务(SaaS)行业将很快进入“快时尚”时代,这或许意味着,即将发布的 GPT-5 会给软件开发流程带来深刻影响,显著提升软件的迭代速度,并降低开发成本。

不过,不少网友们对 GPT-5 的这一表现并不买账。可以看到,GPT-5 在其回答中使用了大量破折号,这是广受用户诟病的“AI 味儿”的来源之一。
此外,GPT-5 并没有进行推理,这导致其反思能力有限,推荐的第二部剧便偏离了一开始的要求,与 AI 无关,反倒是和量子计算扯上了关系。
在评论区中,一条获得 2 万多阅读量的帖子,或许反映了网友们的集体心声:“GPT-5 看上去也和 GPT-4o 没什么区别啊。”

这位发帖的网友还进一步吐槽,GPT-5 的用词毫无必要的夸张、花哨,语言怪癖和 GPT-4o 一模一样。
Altman 近期已在多个场合高调宣传了 GPT-5 的能力,称“GPT-5 在几乎每个方面都比我们聪明”。网友清一色的质疑,反映出已曝出的 GPT-5 表现与用户预期之间的明显差距。
近日,外媒 The Information 曝光了 GPT-5“难产”背后的诸多细节,揭示了 OpenAI 在技术突破、团队管理及与合作方博弈中所面临的重重挑战。
事实上,GPT-5 的发布已经严重延期。原本这一模型早在数月前便应该发布,却因能力提升有限,而被迫降档为 GPT-4.5。研究人员发现,适用于较小模型的微调技术,并不适用于超大规模模型;此外,在将推理模型转化为适合聊天、API 使用的“学生模型”时,其性能出现明显下降。
据知情人士透露,OpenAI 下一代旗舰模型 GPT-5 在编程和数学任务方面相较现有模型有所提升,GPT-5 生成的代码更注重用户体验和美观性;在支持 AI 智能体执行复杂任务时也更加高效,所需的人工干预更少。
不过,也有知情人士认为,其进步幅度难以与 GPT-3 到 GPT-4 那样的代际飞跃相提并论。
一、GPT-5 研发进展不及预期,推理模型实际应用后“降智”明显
GPT-5 的问题,从 2024 年底便开始酝酿。
OpenAI 彼时正开发一款内部代号为“Orion”的模型,原本计划将其作为 GPT-5 发布。据参与者透露,Orion 原本被寄予厚望,目标是大幅超越 2024 年 5 月发布的 GPT-4o。
但 Orion 未能实现预期性能,OpenAI 最终于 2025 年 2 月将其作为 GPT-4.5 发布。除了 150 美元/百万输出 tokens 的惊人定价,这一模型并未给用户带来深刻的印象。今年 7 月,OpenAI 决定将 GPT-4.5 的 API 服务下线,原因是成本过高。这一模型,也成为 OpenAI 史上最短命的模型之一。
部分失败原因在于预训练阶段的局限性。在这个阶段,模型会处理来自网络和其它来源的数据,从而学习概念之间的关联。研究人员发现,高质量网页数据的供给正在枯竭,而且,他们对小规模模型的调优手段在模型变大后不再奏效。
据参与 OpenAI 研发的知情人士透露,截至今年 6 月,OpenAI 还没有开发出一款能被称之为“GPT-5”的模型。
OpenAI 的另一大挑战,源自于推理模型范式在实际应用中出现的意外情况。
去年秋天,OpenAI 推出了第一个推理模型 o1,这次发布使 OpenAI 在 AI 领域重新获得海量关注,也为后续发展能够处理复杂任务的 AI 智能体奠定了基础。
到 2024 年底,OpenAI 又基于 GPT-4o 打造了下一代推理模型 o3,与 o1 属于同一语言模型家族。但知情人士称,o3 的“教师模型(teacher model)”在科学和其他专业领域的理解能力,比 o1 的教师模型有显著的飞跃。
这些提升一部分来自于 OpenAI 给 o3 教师模型配置了更多的 GPU 服务器,从而提供了更强的算力来理解复杂概念;另一部分则源于让模型具备搜索网络和访问代码库的能力。
OpenAI 在全球范围内广泛宣传这些推理模型在测试中的强大表现,社交媒体上一片沸腾。但现实很快泼了冷水。
据两位参与开发的人士透露,当 OpenAI 研究人员将 o3 的教师模型转化为聊天版本(学生模型),以便 ChatGPT 用户能与其交互时,其性能大幅下降,与 o1 相比没有明显进步,最初公布的性能提升几乎消失了,通过 API 接口供企业使用的版本也存在同样问题。
一位人士认为,这是因为这些推理模型理解概念的方式与人类语言有差异。
当被强制用自然语言回答问题时,这种“天才级模型”会被“压缩”到一个更低的表达水平,失去了原有的推理深度。这种差异也体现在推理模型“思考”过程中的乱码输出上。
另一位参与者表示,OpenAI 在模型对话能力训练方面投入不足,也导致沟通效果不佳。
尽管存在性能退化,OpenAI 今年发布的 o3 推理模型仍然帮助了核聚变和病原体检测等科学研究者提出新的假设与实验设计。
不过,大语言模型和聊天型推理模型的发展,未能达到 OpenAI 高层和研究员的预期。o系列模型也在 ChatGPT 产品线中引发用户的困惑,Altman 因此告诉员工,公司将回归 GPT 命名体系。
二、研发通用验证器,OpenAI 称有望实现 GPT-8
推理模型范式受阻后,OpenAI 的研究人员采用了一些业内常见的办法,来维持模型的性能提升。
OpenAI 一直在开发被称为“通用验证器”的工具,据知情人士称,这项技术可自动化验证模型在强化学习过程中的回答质量。
通用验证器的核心是让一个模型来检查并评分另一个模型的答案,前者会借助多个来源来查证答案的正确性。
日前,OpenAI 资深研究员 Alexander Wei 在X上发文称,OpenAI 在 IMO 竞赛中取得所谓的“金牌”成绩模型,使用的正是“通用型”的强化学习,这或许意味着,其验证手段可应用于一些没有标准答案、评判标准主观的任务领域。
通用验证器的进展正在帮助 OpenAI 开发 GPT-5,不仅在编程等可验证性强的任务中有所提升,也在创意写作等主观性强的领域展现出进步。
整个行业,包括 xAI 和谷歌,也都在强化学习上加大投入。负责 OpenAI 强化学习系统的 Tworek 公开向外界表态,OpenAI 模型背后的强化学习系统实际上就是 AGI 的核心。
这些新进展也解释了为何 OpenAI 高管近期在与部分投资人会面时宣称,有信心做到“GPT-8”。
尽管 GPT-5 距离 AGI 还有明显差距,但它在编程和推理之外,也具备一些更具吸引力的新特性。据微软内部测试反馈,GPT-5 在不显著增加计算资源消耗的前提下,生成的代码和文本质量都有提升。
一位微软员工称,这是因为 GPT-5 相比以往的模型更擅长判断不同任务所需的算力强度,从而实现更高效的资源分配。
自动化编程已经成为 OpenAI 重点攻克的方向。部分原因在于竞争对手 Anthropic 去年在向开发者和工具(如 Cursor)提供代码生成模型方面取得了先机。
OpenAI 内部也认为,自动化编程不仅对公司未来业务至关重要,更是推动 AI 研究工作自动化的关键。
三、Meta 挖人引发团队动荡,还有员工拒绝与微软分享新技术
Altman 此前曾公开表态:凭借现有的技术路径,OpenAI 有望实现具有人类智能水平的 AI,也就是通用人工智能(AGI)。
不过,在实现 AGI 的路上,技术并不是唯一的挑战。作为当前最受瞩目的 AI 创企,OpenAI 时时刻刻面临着竞争对手的挖角。
最近,Meta 挖走了十多位 OpenAI 研究员,其中包括参与了 OpenAI 近期核心技术进展的人员。Meta 给这些研究员开出了“顶级球星”水平的薪酬方案,部分人员的甚至拿到了十几亿美元的薪酬包。
这波离职和随之而来的人员重组给 OpenAI 的高级员工带来了压力。上周,OpenAI 研究副总裁 Jerry Tworek 就在公司内部 Slack 中向研究负责人 Mark Chen 表达对团队调整的不满,称自己需要请一周假来重新评估,但最终并未休假。
此外,还有部分高级研究人员抵制将其技术发明交给微软,尽管根据 OpenAI 与微软的协议,微软可以在 2030 年之前,使用 OpenAI 的技术。
OpenAI 与其最大外部股东微软之间财务关系紧密,但围绕合作协议条款一直存在摩擦,双方均试图在 OpenAI 重组营利部门、为未来上市铺路的过程中争取更多让步。
据两位接触过谈判的人士透露,双方的谈判正在朝积极方向推进。一些要点仍在讨论中,但也有内容趋于明朗,例如微软预计将在 OpenAI 的营利实体中获得约 33% 的股权。
结语:OpenAI 的优势,还能持续多久?
当 GPT-5 正式发布时,它将承载外界极高的期望。上周,Altman 在一档播客节目中谈及 GPT-5 的能力时表示,他曾提出一个连自己都听不懂的问题,而 GPT-5 却能轻松作答。
然而,过去一年中,OpenAI 在模型性能上的进展放缓,加之宣传与实际能力之间屡次出现明显落差,也引发了外界的质疑:OpenAI 能否在 AI 能力上继续领先谷歌、Anthropic 等闭源竞争对手,以及 DeepSeek、Qwen、Kimi 等头部开源模型?






