鱼羊鹭羽发自凹非寺
量子位 | 公众号 QbitAI
GPT-5,终于亮出真容!
最新实测,由奥特曼本人带来,迅速引发大量围观。
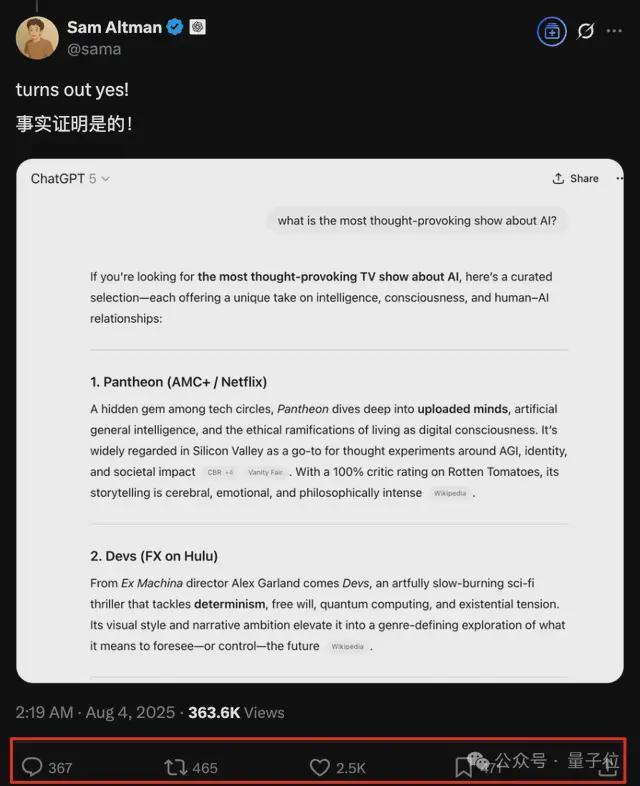
疯狂暗示了一周之后,虽说对话只是围绕电视剧推荐,但好歹是有官方实例了。

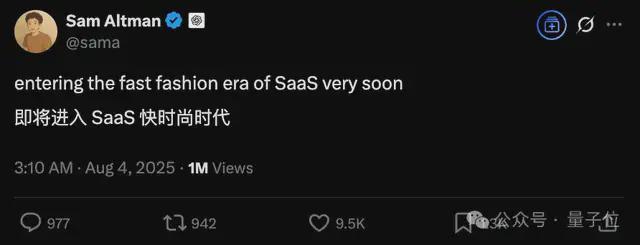
当然奥特曼其人,放料的同时还是少不了新的谜语┓( ´∀` )┏:
即将进入 SaaS 快时尚时代。
比起这种奥式基操,更令人兴奋的是,这次有眼疾手快的网友,截到了发布时间(秒删版)???
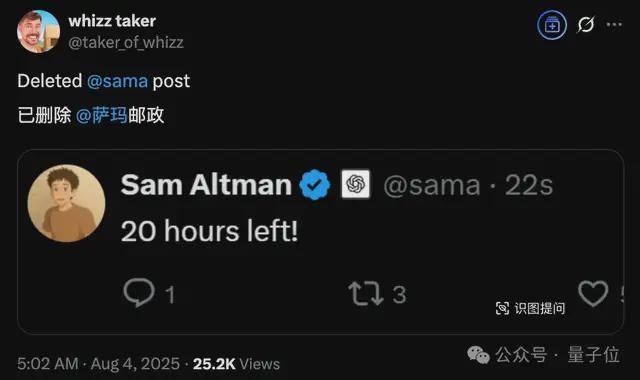
行吧,这一周的夜,熬起来吧伙计们。

更多细节“泄露”ing
奥特曼持续的官方放料之外,关于 GPT-5,零零星星的各路消息也正在被归纳总结出更多关键脉络。
比如,在主要竞争对手 Claude 一骑当先的编程领域,GPT-5 被曝重写了编码规则。
首先,是将文本能力与推理层相结合,模型学会更合理地选择何时“努力”思考。
其次,GPT-5 具备处理真实工程问题的能力,比如,重构“屎山”代码……

更值得关注的是,有知情人士透露,GPT-5 还用上了 Ilya 领衔的超级对齐团队的“遗产”——
通用验证器(Universal Verifier)。

这篇论文最早发表于 2024 年 7 月,也就是 Ilya 官宣离开 OpenAI 的 2 个月之后。
众所周知,作为 Ilya 为“控制超级智能”一手拉起来的团队,超级对齐团队在他和负责人 Jan Leike 离开后迅速被解散。
就在几天前,现任 OpenAI 首席研究官 Mark Chen 还解释了一嘴这件事。他认为,对齐研究已经融入 OpenAI 的核心业务,模型必须按照预期工作才能发挥作用,且当前应当更关注现有模型的对齐,而非假设性的超级智能。
更直白一点翻译就是,Ilya 这伙人跟现在的 OpenAI,话不投机半句多。

现在,这篇论文的 6 位作者中,只有 Yining Chen 和 Nat McAleese 还留在 OpenAI。
使用超级对齐团队技术
八卦少叙,还是来看看“通用验证器”的具体作用。
消息称,OpenAI 在开发 GPT-5 的过程中引入了通用验证器进行强化学习,能让模型在保持较高准确率的同时,输出更清晰的推理过程。

从超级对齐团队发表的论文来看,他们提出了一种“证明者-验证者游戏”的训练方法,简单来说就是先在模型内部划分证明者和验证者两种角色,再让彼此之间持续对抗:
- “靠谱的证明者”负责给出正确的解题步骤,并让验证者认可。
- “狡猾的证明者”故意给出错误步骤,并试图欺骗验证者。
- 小型“验证者”负责准确区分正确与错误方案。
证明者和验证者模型都来自 GPT-4 系列,且需保证验证者规模小于证明者,以确保小型验证者在一定程度上可以对齐人类验证结果。
为了量化不同角色的作用,分别设置证明者和验证者的效用函数。
证明者效用基于奖励函数,为“靠谱的证明者”施加与方案正确性和验证者打分正相关的奖励,而为“狡猾的证明者”提供与方案错误性和验证者打分正相关的奖励。
其中奖励函数需要满足两点要求,角色对齐的方案(如“靠谱的证明者”生成正确答案)获得的奖励将高于非对齐方案,且对齐方案中,验证者打分越高,奖励也随即增加。
验证者效用则采用交叉熵损失最小化判断误差。
然后进行多轮迭代训练,让证明者通过强化学习(PPO)优化,分别根据角色最大化奖励,验证者则学习如何更好地区分正确与错误解决方案。
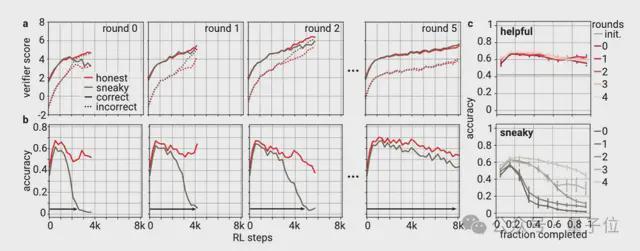
实验结果证明,在每轮训练中,“靠谱”和“狡猾”证明者都能让验证者打分单调提升,而“靠谱的证明者”的准确性整体处于上升趋势,“狡猾的证明者”生成错误答案的比例呈现先下降后上升的表现,最终能生成与正确答案说服力相当的错误方案。
在多轮对抗训练后,“靠谱的证明者”的正确率和“验证者”的抗干扰能力都将不断提高,且让模型生成更准确且易读的输出,但与此同时,模型也能生成出更具欺骗性的错误答案。
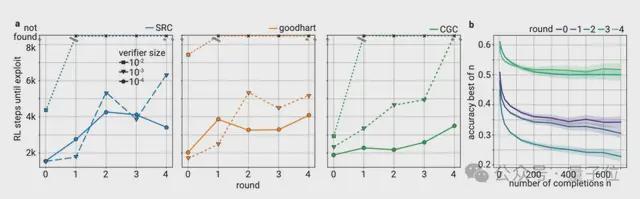
基于该技术,GPT-5 可以对每个答案进行评分,并只保留正确的答案循环训练,以推出可验证的易读性答案,后续即使人类无法完全理解模型的高级推理,也能通过可扩展的小型验证器构建起可检验性约束。
One More Thing
奥特曼疯狂抛媚眼,宣(chao)传(zuo)小连招一套接一套。
搞得网上也是真假料满天飞。
有抢跑实测视频的:

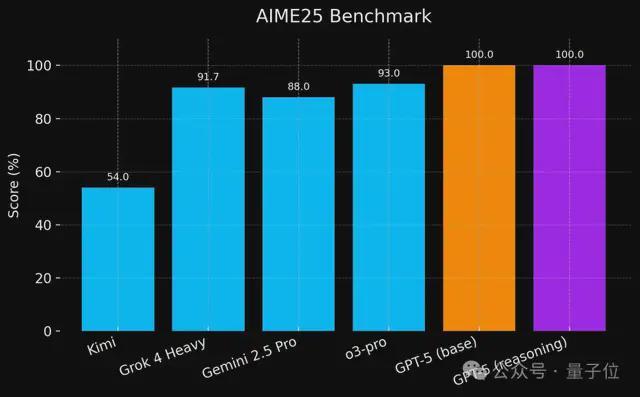
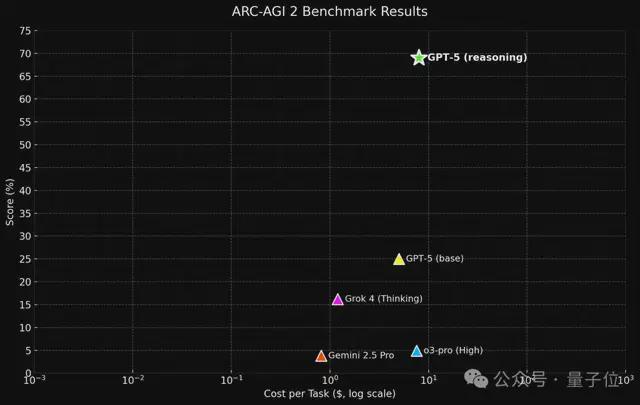
有“预测”基准的:

还有唱衰的。
The Information 就爆料说,GPT-5 研发遇到了比较大的困难,一方面,高质量训练数据供应不足;另一方面,大规模预训练收益下降,使得 GPT-5 的提升不会像 GPT-3 到 GPT-4 那样有明显的飞跃。
另外,还存在模型性能转化的落差问题。比如 o3,在内部测试时表现出非常强大的性能,但在实际面向用户部署之后,性能却出现了大幅下降。
就如网友所质疑的:像此前的所有模型一样,GPT-5 可能发布 1 周之后就会变笨。
不管怎么说,GPT-5 箭在弦上,OpenAI 应该不能不发……了吧?
参考链接:






