来源:新智元
Meta 超级实验室「Meta Superintelligence Labs,MSL」发了新论文!
如果你不断让大语言模型回答「把它改进一下」,会发生什么?
上周,MSL 的三位成员上传了一篇 ArXiv 论文,探索了如何利用强化学习(RL)高效地微调大语言模型。

传送门:https://www.arxiv.org/abs/2509.04575
在推理时,LLM 这次实现了迭代自我改进。
自我改进决策过程 +GRPO
训练具备迭代自我改进能力的模型,代价不菲。
最直接的做法是训练模型执行K步自我改进,但这会让每个训练回合的轨迹步数(rollout 步数)膨胀为原来的K倍。
他们提出了一种新的方法——探索迭代(Exploratory Iteration,ExIt)。
这是一个基于 RL 的自动课程学习方法。
通过「回收利用」大语言模型先前回合中生成的回答,新方法把这些回答作为新的起点,用于自我改进(self-improvement)或自我发散(self-divergence),从而逐步扩展和多样化训练分布。

探索迭代(ExIt)策略概览
DeepSeek 的强化学习微调方法 GRPO,性能强大,而且与之前的 PPO 方法相比减少了资源需求。
与 PPO 不同,GRPO 不使用学习到的价值函数来计算基线项,而是使用一组G条蒙特卡洛轨迹,估计每个初始提示m的基线。
在此过程中,「可学习性分数」在训练过程中自然产生。

在决定下一个训练任务时,ExIt 的课程机制会优先抽取那些在 GRPO 表现出更高回报方差的部分历史。

通过这种自举任务空间的自动课程,模型学会多步自我改进,但训练仅需单步任务。
为了抵消强化学习减少输出多样性的倾向,研究者直接纳入了寻求多样性的组件:发散改进(self-divergence)。
以概率p_div,自我迭代步成为自我发散步。
在这一步中,策略被提示在先前解决方案的基础上进行改进,同时显著偏离它(见下列提示)。

他们发现:
发散步能够从模型中诱导出有意义的不同响应,当整合到 ExIt 策略中时,可以增加任务空间的覆盖范围。
机器学习工程 MLE-Bench
比 GRPO 强 22%
在单轮(竞赛数学问题)和多轮(BFCLv3 多轮任务)场景中,以及 MLE-bench 中,研究者考察了 ExIt 的影响。

表1:在保留的任务实例上对 ExIt 及其消融实验和 GRPO 基线的评估。数学结果是对所有测试分割的平均值。所有结果都是在 3 次训练运行后经过 16 次改进步骤的性能的均值和标准差,以及从初始响应到经过K次自我改进步骤后的最终响应之间的净百分比改进(ΔK)
在 MLE-bench 中,大语言模型在搜索框架下运行,以产生针对真实 Kaggle 竞赛的解决方案。
在这些评估设置中,与 GRPO 相比,ExIt 产生的模型在推理时具有更强的自我改进能力。
值得注意:在测试时,ExIt 可进行超过训练典型深度的自我迭代;在 MLE-bench 上,对 GRPO 的相对提升约 22%(58.6vs48.0)。
尽管在 MLE-bench 上,这次研究者使用简单的贪心搜索框架评估了 ExIt,但这里的核心思想也可以应用于其他搜索框架。
实际上,其中许多都是 while 循环,在给定合适上下文的情况下,指示 LLM 对先前的解决方案进行自我改进。

作者进一步分析了不同方法在训练过程中所采样到的任务实例的多样性。
下图展示了各方法采样到的训练任务实例数量,相对于 GRPO 使用的基础训练集的比例。
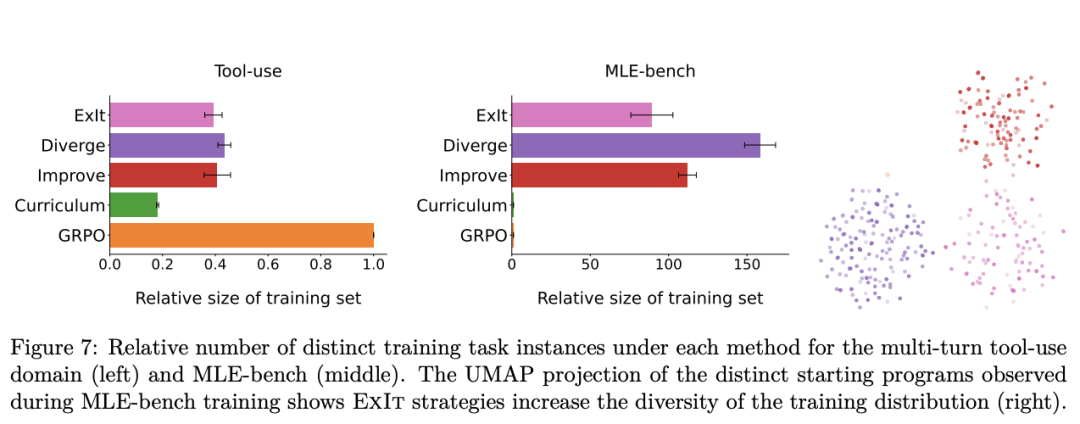
实验结果表明:
1. 仅使用课程学习的基线方法会显著减少训练中遇到的不同任务实例数量。这说明优先级采样会导致同一训练实例被大量重复,从而压缩了任务多样性。
2. 这种任务多样性的降低,可能正是该基线方法表现逊色于 ExIt 变体的原因。而在 ExIt 中,自我迭代步骤有效地恢复了相当一部分丢失的多样性。
3. 对于完整的 ExIt 方法,我们观察到在课程机制下提升的多样性,与其在测试集上性能的提升相对应。
此外,在 GRPO 的基础分布中,所有 MLE-bench 任务起始点相同(同一个空 Python 模板);但 ExIt 下起始代码多样性大幅增加。
上图的右侧的 UMAP 降维结果进一步凸显了 ExIt 变体与基础任务集之间的差异:
在嵌入空间中,基础任务集几乎只是单一的一个点,而 ExIt 所产生的任务实例分布则显著更为分散。
直接追求新颖性的 ExIt 变体,能够在发现的任务实例中实现更高的平均余弦距离与 L2 距离。
其中,完整的 ExIt 方法达到了最大化的平均两两距离,这说明它在任务空间探索中最具多样性。
作者简介
第一作者,Minqi Jiang 今年 1 月加入 Meta,担任高级研究科学家,构建超级智能体。

从泛化(generalization)、人机协同(human-AI coordination)与开放式学习(open-ended learning)三个视角,他研究「既有用、又符合人类价值」的智能体。
他在谷歌的 DeepMind 人研究科学家期间,在 Autonomous Assistants(自主助理)团队开始了这项研究。

他与 Meta 的渊源则更深。在 2023 年 9 月–2023 年 12 月,他担任了 Meta 的访问研究员(Visiting Researcher),之后加入谷歌,直到今年 1 月再次入职 Meta。
更早之前,他有多段创业和工作经历。

2008 年-2012 年,他就读于普林斯顿大学(Princeton University),获得了计算机科学、应用数学、创意写作学士学位。
2019 年–2023 年,他在伦敦大学学院(UCL)攻读计算机科学人工智能方向博士学位。
2023 年 1 月–2023 年 6 月,他还是牛津大学(University of Oxford)的访问研究员。






