
来源:新智元
当全世界的目光还聚焦在大语言模型和 AI 智能体的竞赛时,英伟达已经将视线投向了更宏大战场——物理世界。
我们所熟知的人工智能,至今更多存在于数字世界中:生成文字、图片、代码,进行搜索和推荐。
然而,AI 的「终极形态」,必然要走向现实,与真实环境互动!
在「新智元十周年峰会」上,NVIDIA 工程和解决方案副总裁赖俊杰,向外界系统地揭示了公司的下一个十年战略核心:物理 AI (Physical AI)。

这不仅是继「生成式 AI」和「智能体 AI」之后的下一波浪潮,更是一个旨在彻底解放人类生产力,重塑未来生活方式的宏伟蓝图。
这,是一个要把真实地球装进 GPU 的时代!
英伟达为什么在今天把筹码压向现实世界?

黄仁勋(右)接受新智元创始人杨静采访并合影
当时,黄仁勋就看到了 AI 对 GPU 的强劲需求,并对 AI 做出判断:具有常识的机器会很快出现。

今年 7 月,黄仁勋再访北京,接受了国内外媒体采访。在现场,新智元有幸采访了黄仁勋。这次,黄仁勋改变了 9 年前对 AGI 的看法:
根据我所理解的 AGI 定义,目前已有很多很好的想法,可能会在不远的将来引向通用人工智能。

2025 年,黄仁勋和新智元创始人杨静女士合影(上方左);在新智元创始人杨静女士背后,黄仁勋在签名(上方右);黄仁勋签名(下方)
这也是新智元十周年峰会参会嘉宾的共同感受——
过去 10 年,是 AI 奇迹的 10 年。现在,人类前所未有地接近 AGI。
AI 在指数级发展,正如《2025 新智元 ASI 前沿趋势报告》所言:
过去 6 年,AI 智能体独立完成人类任务的时长能力,始终以约 7 个月翻一番的速度指数级增长。
最新的 GPT-5 模型,在软件工程任务上的「50% 成功率时间视域」,已达 2 小时 17 分钟。
到 2027 年末,AI 智能体将能独立执行需要人类耗时几天乃至数周的项目。届时,ASI 的曙光将冲破云霄,一个恢弘的智能新纪元将正式开启。
今年,OpenAI 已发布了三大智能体——Operator、Deep Research、Codex。
据称,DeepSeek 的下一个大动作也是高阶智能体,力争年底发布相关更新。
智能体让模型从会答变成会做,门槛是可靠性与工具链整合。
但英伟达的视野已经越过了智能体乃至 Agentic AI,他们开始布局下一波 AI 浪潮——物理 AI。

在「新智元十周年峰会」上,NVIDIA 工程和解决方案副总裁赖俊杰分享了对 AI 未来的行业判断。
算力大爆发
2012 年,AlexNet 横空出世。
之后,深度神经网络席卷学术界工业界,深度学习引爆 AI 研究范式转移:
无数研究者开始下定决心,全力投入到以深度神经网络为代表的深度学习技术。
很快,许多落地了一批场景与应用:语音、视觉、图像、搜索……
2013 年,赖俊杰加入英伟达。
他见证了 AI 史上这波浪潮,英伟达迎来新的算力需求大爆发。
之前,英伟达已经开发了 CUDA,但 GPU 等算力主要用于科学计算、生物、化学、天体物理等等任务。
一般的客户也就买几块、几十块 GPU;如果能买上几百块 GPU,那就是真正意义上是大客户。
但 2014 年,百度一家就买下了英伟达 1000 块 GPU。
第一次听到这个消息的时候,赖俊杰感到吃惊。
而现在,xAI 旗下的数据中心 Colossus 已配备了 20 万块 GPU。
只有如此的算力,才足够支持 GenAI 进入千家万户。
LLM 迎来了爆发,带来了很多生产力工具。
今天,大家已经非常习惯于用自然语言去跟数字世界的大模型进行交互,来生成图像、视频、文本等等。
对于游戏发烧级玩家而言,可能没有想到游戏渲染新技术 DLSS 也得益于 AI 的发展。
AI 改变了太多。
但到今天为止,大家接触最多的人工智能还只存在于数字世界中:各种各样的图像、语音搜索、广告推荐等等,
英伟达认为,「物理 AI」是继 Agentic AI 后的下一代 AI 浪潮。
赖俊杰重点分享了英伟达的物理 AI 战略构想。
AI 的下一代浪潮
机遇与挑战
回到物理 AI,它被视为接下来人工智能发展的重要方向。
所谓的物理 AI,就是与现实的物理世界交互的 AI。
物理 AI 意味着物理 AI 驱动的自主机器,可以与周遭的物理世界交互,理解真实世界,采取各种各样的行动。

不同的物理 AI 自主机器,大家的期望也有所不同。
比如,工业的机械臂,大家只是期望它在固定位置上,可以进行抓取和叉装这些精细的小动作。
而智能驾驶汽车,大家则希望它理解各种各样复杂的路况,并且需要掌握像转向、变道、加速、刹车等等技能。
最具挑战性的是人形机器人,我们对它的期望是
在基本所有人类涉足的复杂场景里,它都能做出各种各样复杂的动作。
物理 AI 要想取得成功的话,其实面临着非常大的挑战。
因为人工智能的模型和算法驱动机器,与现实的世界交互。
如果算法和模型没有经过充分验证,或者说它的安全措施不到位的话,就可能对我们周遭的物理环境,甚至是人本身产生伤害。
而要开发安全鲁棒的物理 AI ,另一大挑战是数据要求更高。
物理 AI 需要的高质量数据,以及在一些极端场景数据非常难以去采集。
极端场景稀缺——但恰是鲁棒性关键。
比如说车前突然出现了车辆或其他障碍物,类似于这样危险的数据的话还是比较稀少的。

此外,物理 AI 的测试与验证,成本体量非常的高,人力、物力等投入非常大。
而且物理 AI 需要的数据难以拓展,受到物理现实的直接制约。
比如说,现在是夏秋之交,想要测试冰雪环境下自动驾驶算法,很难甚至可以说基本不可能。
要实现安全可靠的 AI,不止需要传统 LLM 训练需要的算力平台集群之外,或者部署平台需要的一些计算平台。
我们还需要第三类计算的基础设施。
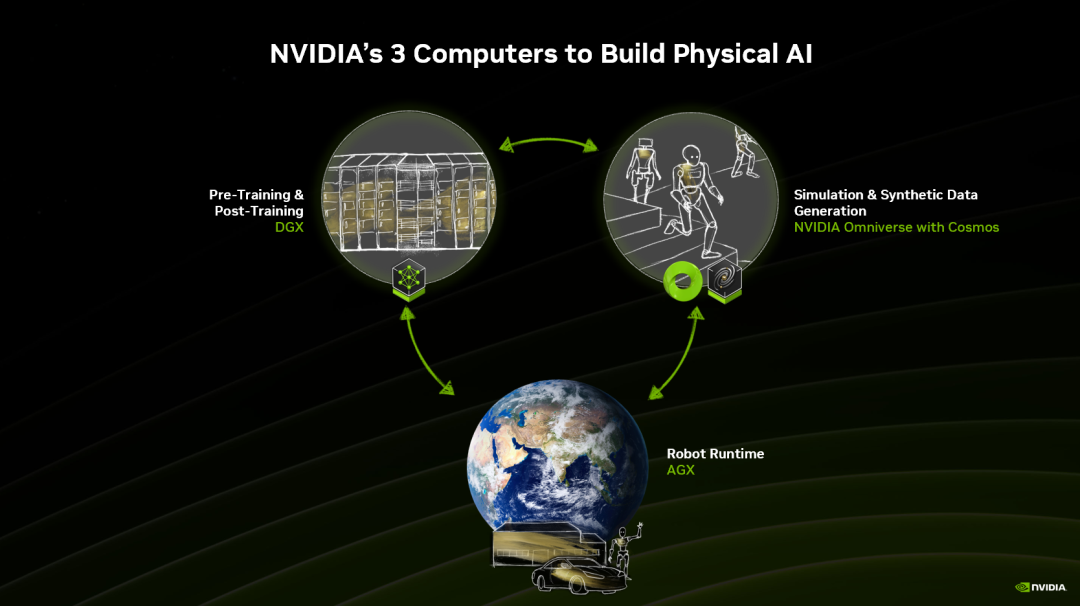
把地球装进 GPU
在第三类计算基础设施之内,实际上就是把现实的物理世界,非常逼真地还原到虚拟世界中。
然后,在这样的虚拟世界中,对物理 AI 算法进行测试、验证、仿真等等。
但为什么要在虚拟世界中做物理 AI?最大的好处是什么呢?
首先,它非常的容易扩展 scale。
现实测试从一台车拓展到 10 台车,拓展到 100 台车,不是特别容易,但是在数据中心里面放 1 台机器, 10 台机器、 100 台机器、 1,000 台机器,就相对容易拓展。
而且在虚拟世界中,更容易摆脱时空的限制。
比如,在虚拟世界中,夏天测试自动驾驶算法在冰雪环境下的表现就相对容易。
这就是英伟达对物理 AI 的核心思路想法。
为了应对物理 AI 各种各样的一些挑战,为了更好能够去测试、验证、训练模型,英伟达今年年初开源了 Cosmos 世界基础模型。

开源方案覆盖预训练、后训练、微调等全流程,而且可以免费商用;目前,已下载 200 多万次
加速物理 AI
英伟达开源三大模型
世界基础模型 Cosmos 包含三类模型:
Predict:未来世界状态的生成模型;
Transfer:照片真实集的增强模型;
Reason:针对物理世界的推理模型。
Predict 模型的输入是当前的世界状态,或者说可以认为是一个起始的图像帧,用文字的方式去描述希望接下来这个世界发生的事件。

许多自主机器人配备多相机;将相机位姿与位移等信息输入后,即可生成对应输出。
比如,相机控制,在虚拟世界中告诉模型你要向左向右,向前向后做移动,就可以在虚拟世界中产生这样一些视频图像。
很多自主机器尤其像智能驾驶汽车经常有多个传感器或者多个相机,Predict 模型支持同时生成六个不同位置的汽车上的相机所对应的视频。

第二类是 Transfer 模型。
它的输入有很多类,包括分割图,包括激光雷达的点云,或者说高清地图,还有表示各种各样物体移动信息的 bounding box,把这些综合上你的指令 prompt,输入 Transfer 模型,就可以生成下面右边的视频。

第一眼看过去,脑子里面有一个疑问,这些有什么用呢?
其中一类用法,把它当成生成式仿真工具,拿一段原始真实的视频,从中提取出它对应的世界状态。

比如说高清地图,还有 bounding box,把这些信息结合 prompt 输入进去,你可以得到从原始视频转换来不同条件所对应的视频,比如不同光照条件下、气候条件下,甚至包括火灾情况下的新的视频。
另外,值得一提,中间的这个视频也非常重要:对世界状态做一些编辑。
而上文提到过训练安全鲁棒的算法,其中一个挑战是极端情况的数据非常难得。
解决思路:人为注入极端要素(如突然有动物穿越车前),生成对应视频,用于验证算法的鲁棒性——
这正是高性能 Transfer 的价值。
接下来的一段视频,让大家更好地去理解一下现在它能达到的效果。
最后,推理模型 Cosmos Reason。
它的输入也是一段视频, 进入视觉编码器生成 token,再结合文字的 prompt 输入到大语言模型里面,进行思维链的计算,最后输出。

Cosmos Reason 应用领域非常多。
比如做质检的企业,拿它做视频的标注,或者视频的判断,包括对于模型做直接的微调之后,甚至可以直接去作为机器人 VLA(Vision Language Action)的模型。
有两个小的例子。
第一个让 Reason 模型对视频做精细的描述:
第二个问 Reason 模型,在视频里面工人是不是戴了硬质安全帽,是否与风力发电机保持安全连接等。
人工智能已经在数字世界取得非常大的成功,深刻地改变了日常的生活与工作的习惯,并正加速进入物理世界。
最后,赖俊杰再次强调:
为了能够训练与开发出来鲁棒的模型、算法,
为了能够让这些 AI 算法对真实的物理世界、对人类足够安全,
NVIDIA 开发开源了 Cosmos 世界基础模型。
展望未来十年,英伟达相信在物理世界,物理 AI 的应用必将取得非常实质性的进步,进一步解放人类的生产力。






