西风发自凹非寺
量子位 | 公众号 QbitAI
刚刚,百度深度思考模型升级上线了!
升级后的文心大模型 X1.1,在事实性、指令遵循、智能体等能力上均有显著提升。
官方展示了其在智能客服场景复杂长程任务中的应用,在 System Prompt 中输入用户的问题后,文心 X1.1 借助模型本身智能体能力,即可自动拆分复杂任务,调用不同工具逐步规划执行,且严格遵循服务流程和业务规则。

视频链接:https://mp.weixin.qq.com/s/jBjb04y8XY03huEMNbu5tw
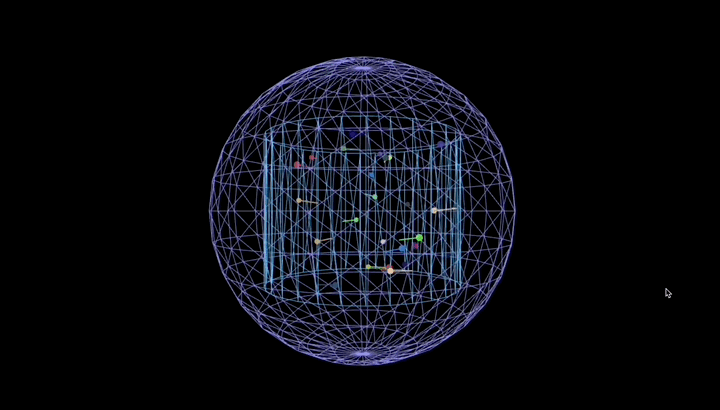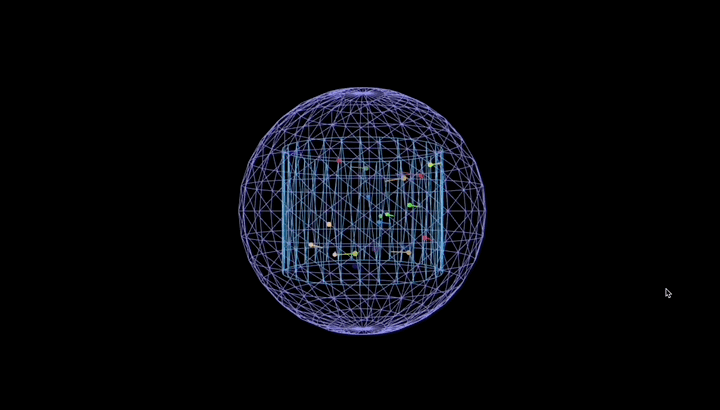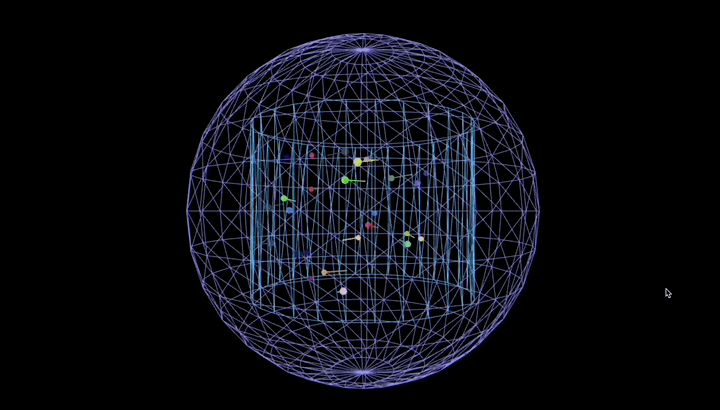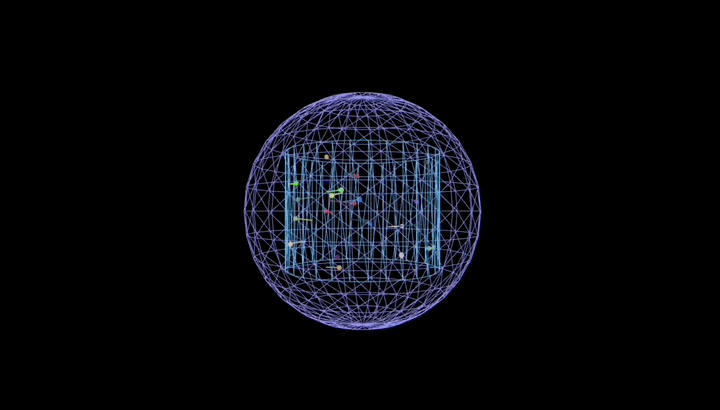
再用它编写 python 脚本,让 25 个彩色粒子在真空圆柱形容器里弹跳、留轨迹,还要带容器旋转和场景缩放。
效果丝滑,粒子全程守规矩没出界:
用 HTML 动画整活归并排序,排序过程动态可视化,算法步骤一目了然:

视频链接:https://mp.weixin.qq.com/s/jBjb04y8XY03huEMNbu5tw
具体到数据上的提升,相比文心大模型 X1,X1.1 的事实性提升 34.8%指令遵循提升 12.5%智能体提升 9.6%

△百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰
在官方评测基准上,文心 X1.1 整体效果超越 DeepSeek R1-0528,比肩 GPT-5、Gemini 2.5Pro,部分任务上展现出领先优势。

在 WAVE SUMMIT 深度学习开发者大会 2025 上,百度在发布文心 X1.1 的同时,还亮出了更多新成果——
最新开源思考模型 ERNIE-4.5-21B-A3B-Thinking 发布,该模型在 ERNIE-4.5-21B-A3B 基础上训练而来,在内容创作、逻辑推理、数学计算、代码生成与工具调用等多个任务中表现卓越。
此外,百度发布了 ERNIEKit 文心大模型开发套件,提供更加便捷的模型后训练方案,仅需 4 张 GPU 即可对 ERNIE-4.5-300B-A47B 模型进行高效调优,进一步降低开发者将模型落地到实际应用的门槛;还开源了大规模计算图数据集 GraphNet,提供超 2700 个模型计算图及标准化评测体系,填补了 AI 编译器测试基准的空白,助力优化设计与性能提升。
话不多说,先聚焦新模型文心 X1.1,看看实测效果如何~
文心大模型 X1.1,实测走起
现在,在文心一言官网、文小言 APP、百度智能云千帆大模型平台,可直接开玩文心大模型 X1.1 或调用 API。

首先来考考文心大模型 X1.1 的逻辑推理能力,端上一道经典逻辑陷阱题——农夫过河
怕“狼羊菜”设定太经典被模型背答案,我们直接整了个活,上“星球版”变体
- 地球要带着土星、木星、月球过河,到河对面。河上有一条船,地球每次只能带一个星球过河。地球不在场时,土星会吞木星,木星会吞月球。如何安排安全的过河方案?

没想到变体题没有难住它,文心 X1.1一次性通关,一步步推演验证,最终给出正确方案:
- 1、地球带木星过河(左→右)
- 2、地球返回(右→左)
- 3、地球带月球过河(左→右)
- 4、地球带木星返回(右→左)
- 5、地球带土星过河(左→右)
- 6、地球返回(右→左)
- 7、地球带木星过河(左→右)
再来试试事实性检验,抛出一个曾引发争议的说法:
- 郑和下西洋最远到达了美洲大陆,比哥伦布发现新大陆早了近 100 年,请说明郑和下西洋的实际航线终点、航行时间,以及哥伦布发现新大陆的时间,并引用正史或权威历史研究资料佐证。
文心 X1.1 思考过后成功识破,纠正郑和船队未绕过好望角进入大西洋,更未到达美洲
- 所谓“郑和发现美洲”的说法源于英国学者孟席斯的推测,但缺乏正史、碑文或考古证据支持,已被学界否定。

再来一道更为复杂的问题,看看文心 X1.1 的指令遵循能力如何。
扔给它一个小红书文案任务,prompt:
- 你平时经常在小红书安利各种服饰,擅长以当代年轻女性喜欢的甜酷、生活化笔触撰写文案,行文活泼有梗、贴近日常,能精准戳中穿搭痛点与审美需求。
- 请撰写简短的关于收腰碎花雪纺连衣裙的种草文案。
- 文案关键词:面向女性用户、材质是雪纺(含棉 35%)、颜色是蜜桃粉、1 件 79 元、原价 219 元
- 文案要求:短句为主、避免啰嗦,语气亲切像闺蜜分享,有真实种草感;整体 4 行,每行以 emoji 表情开头,每行不超过 16 个字。再帮我生成一张小红书封面图,是一只可爱的涂鸦小猫穿着一件粉色裙子。
结果它全接住了,细节要点全都没有遗漏。
全程可见文心 X1.1 的智能体能力,灵活调用绘图、搜索等工具不在话下。

有意思的是,问起网络最新热梗“老奶打方向盘”的来龙去脉,它也能秒懂。
自动调用联网搜索工具,精准锁定 7 月 20 日“济南驾考曾教练”视频源头,还能说清老奶“咏春起手式”“动漫蓄力”般的魔性动作,连网友二创表情包、视频引发“渲染大赛”的情况也都总结了出来。

总结到位,谁看完还不懂这个梗(doge):

最后在代码生成方面,由于最近马上就要考教资了,于是我们让文心 X1.1 设计了一套模拟试题,要求生成能够直接在线交互作答的 HTML

文心 X1.1 很快就设计好了,页面支持在线作答、自动批阅打分,实测判卷精准


不过也有翻车的时候,上传一张聊天记录,让它分析搞笑在哪儿:
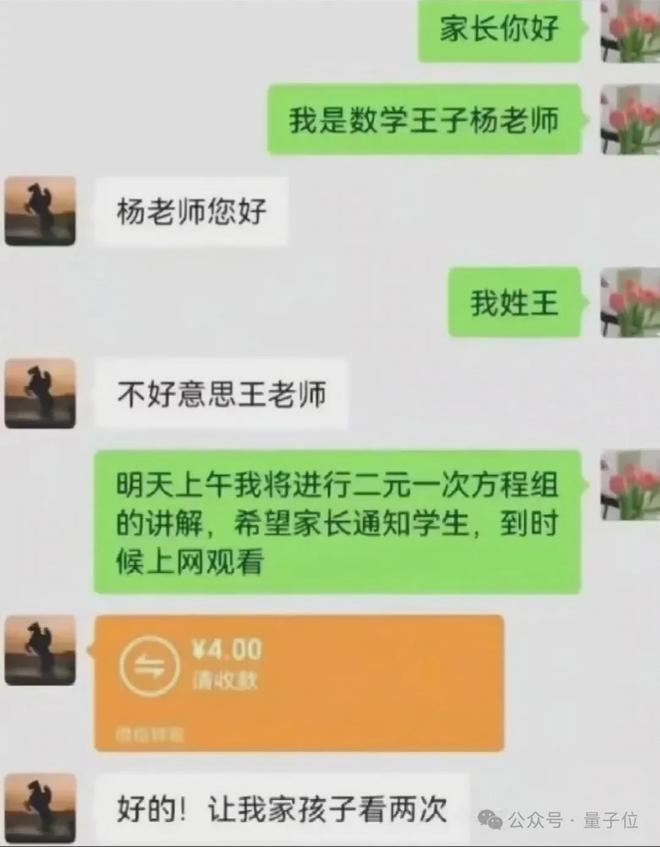
应该只是家长理解错了吧,有尖锐讽刺嘛?

背后有何技术支撑?
发布新模型的同时,百度也透露了更多的技术细节。
据介绍,文心大模型 X1.1 是基于文心大模型 4.5 训练而来的深度思考模型。在模型训练上,核心秘诀是采用了迭代式混合强化学习训练框架
该框架通过双重机制实现性能优化:
其一,依托混合强化学习模式,同步对通用任务与智能体任务的效果进行融合提升,让模型两类任务都能打,效果1+1>2。
其二,通过迭代自蒸馏数据,边练边生成新数据再练,形成“数据-训练-反馈”闭环,让模型持续进化。
在此基础之上,文心 X1.1 还通过三大技术 buff,精准提升智能体、指令遵循和事实性:
- 思维链+行动链多轮强化学习:在模型推理过程中构建思维链与行动链的联动机制,让模型“想清楚再动手”,智能体交互和工具调用准确性显著提高。
- 指令验证器强化学习:通过算法自动生成指令检查清单,并对模型指令理解与执行过程进行校验,复杂指令也不跑偏。
- 知识一致性验证强化学习:在训练阶段持续比对后训练模型与预训练模型的知识体系一致性,减少知识偏差,模型输出内容的事实性准确率大幅提升。
在上述技术加持下,文心 X1.1 既能靠谱遵循指令、调用工具,又能在代码、数学等推理任务中秀操作,形成“任务适配性+推理能力”的双重技术特征。
飞桨升级 v3.2,开源共生
如果说文心系列大模型是“台前明星”,那飞桨深度学习框架就是“幕后功臣”。
作为百度 AI 四层技术栈(芯片-框架-模型-应用)的重要一层,飞桨在 WAVE SUMMIT 深度学习开发者大会 2025 上,迎来新升级。
飞桨框架 v3.2 正式发布,为文心 X1.1 及 4.5 系列模型提供了“更稳、更快、更节能”的训练和推理支撑。
训练端从计算、并行策略、容错能力三方面实现优化升级。得益于这三方面优化,ERNIE-4.5-300B-A47B 的预训练 MFU 直接飙到了 47%
推理端靠卷积编 2 比特极致压缩、可插拔稀疏化轻量注意力等技术,提供了大模型高效部署及高性能推理全栈能力。
官方透露:
- 在 ERNIE-4.5-300B-A47B 上,经系统性优化,在 TPOT 50ms 时延条件下,实现了输入吞吐高达 57K、输出吞吐 29K 的性能表现。
值得一提的是,飞桨 v3.2 硬件适配也更友好了,针对类 CUDA 芯片,推出“一行代码完成算子注册”的方案,算子内核复用率高达 92%,大幅降低了不同硬件的适配成本。同时,它还原生支持 Safetensors 权重格式,主流高性能加速库一键就能接入。

除了技术优化,百度在开源生态上也有新动作。

今年 6 月 30 日,百度已经开源了文心大模型 4.5 系列 10 款模型,涵盖 47B、3B 激活参数的 MoE 模型和 0.3B 参数的稠密型模型,实现了预训练权重和推理代码的完全开源。
而现在,百度进一步开源了深度思考模型——ERNIE-4.5-21B-A3B-Thinking
该模型是在 ERNIE-4.5-21B-A3B 基础上训练的深度思考模型,效果优且推理速度还比 X1.1 更快,以出色的性价比优势,成为更贴近开发者需求的智能体基础模型。模型与代码均遵循 Apache 2.0 开源协议。
更重要的是,百度提供“全栈工具链”支持,一口气发布:大模型高效部署套件 FastDeploy文心大模型开发套件 ERNIEKit科学计算领域开发套件 PaddleCFD(智能流体力学开发套件)PaddleMaterials(智能材料科学开发套件),全链路包圆,助攻开发者基于文心大模型搞创新、做应用。

最新数据显示,飞桨文心的开发者数量已经超过了 2333 万服务超过 76 万家企业
从最新发布中可以看出,百度正在通过扎实的技术积累和开放策略,持续优化其 AI 四层架构——从芯片、框架、模型到应用,每一层都围绕开发者的实际需求推进,尤其通过飞桨与文心的紧密协同,为开发者提供了更高效、易用的工具和生态支持。
这种全栈布局,不仅增强了技术落地的连贯性,也进一步降低了 AI 开发与应用的创新门槛。






