闻乐鹭羽发自凹非寺
量子位 | 公众号 QbitAI
刚刚,0 产出估值就已冲破 120 亿美元的 Thinking Machines,终于发布首篇研究博客。
创始人、OpenAI 前 CTO Mira Murati 亲自宣发,翁荔等一众公司大佬纷纷转推:

研究主题是“Defeating Nondeterminism in LLM Inference”,克服大语言模型推理中的不确定性。
主要讨论的内容就是,为什么大模型每次的推理结果总是难以复现?根源在于批次不变性。

不鸣则已,一鸣就是万字长文,并且,Thinking Machines 还致敬了一波“连接主义”——
Mira 和她的同事们认为,科学因分享而更加卓越。他们将保持对研究成果的分享,并与研究社区保持频繁、开放的联系。
而翁荔在转发推文中,还透露了 Thinking Machines 的第一代旗舰产品名为Connection Machine。

(CloseAI 膝盖又中了一枪)
击败 LLM 推理中的非确定性
众所周知,LLM 推理中,想要获取可复现结果相当困难,比如说多次向 ChatGPT 提出相同问题,但结果很有可能不同。
即使将采样温度降至0,原则上 LLM 会选择概率最高的 token 输出,但实际中此时不确定性仍然存在。
过去普遍认为这是因为浮点非结合性和并发执行之间的某种组合导致,即 GPU 在执行浮点数运算时会出现非结合性,比如(a+b) +c 不一定等于a+ (b+c),然后在并行操作中则根据执行顺序的不同,产生不同的结果。
但其实这个说法并不完整,如果在 GPU 上对同一数据重复运行相同的矩阵乘法,却可以始终获得确定的同一结果。

于是 Thinking Machine 深入研究后发现,其实罪魁祸首应该是批次不变性。
首先浮点数计算存在数值差异的原因确实是浮点数非结合性。
因为浮点数本身在编码中,是通过 “尾数×10^指数” 的形式表示,精度有限,所以当两个不同指数的浮点数相加时,就必须调整指数并舍弃部分精度,从而导致一部分信息丢失,所以后续的相加顺序不同才会产生不同的结果,使其不满足结合律。
但浮点数为什么会以不同顺序相加呢?
究其根源,是因为现在的 LLM 推理缺乏批次不变性,单个请求的输出受到同一批次中请求数量的影响。
主要问题是:
- 实际部署中,服务器会随着负载动态调整大模型推理批次的大小,而现有的内核会因批次的变化而改变矩阵乘法、RMSNorm 等关键操作的计算顺序或策略;
- 浮点运算的非结合性使不同计算顺序产生微小偏差,这种偏差在 Transformer 多层迭代中被放大,最终导致相同输入正在不同批次下输出不同,破坏了推理的一致性。
要解决这一问题,那就需要让 RMSNorm、矩阵乘法、注意力机制分别具备批次不变性。

在RMSNorm中,重点就是要固定好每个批次元素的归约顺序而不受批次大小影响,则需要为每个内核分配一个批处理元素,让每次归约操作都能在单个核心中完成。
当批大小增大时,核心就会依次处理多个批次元素,而保持归约策略不变;当批大小较小时,则可以自动忽略一些并行性优化措施,虽然效率可能会随之降低,但能保障批次不变性。
而矩阵乘法在实际中也与批大小有关,所以可以通过将输出张量拆分为 2D 块,然后为每个块分配不同的核心。
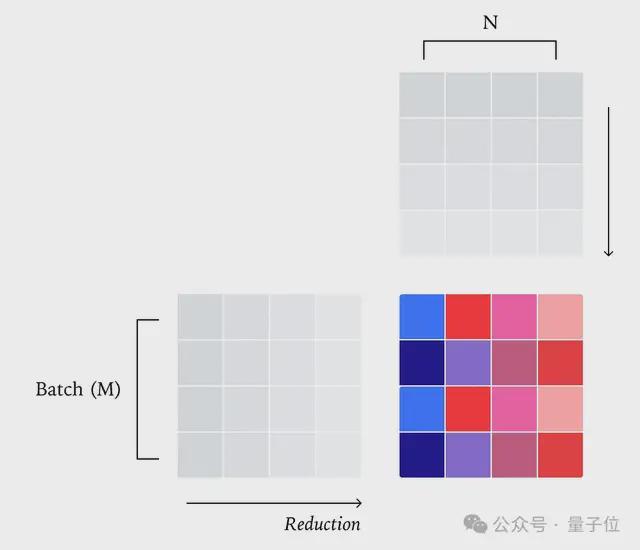
其中每个核心计算都属于该块的点积,再在该核心中执行归约操作。
但要注重在批维度(M和N)过小时,可能会被迫沿着归约维度(K)进行分割,也就是Split-K 矩阵乘法,这样做同样会影响归约顺序,另外不同的张量核心指令也会导致结果变化。
所以更简单的方法是为所有输入形状编译统一的内核配置,避免因批大小变化切换并行策略或张量核心指令。
尽管相较于CuBLAS,这样做可能会损失约 20% 的性能,但是可接受的。

而注意力机制则更加特殊,首先它需要更多的归约维度,需要沿着特征维度和序列维度双重归约,一些像分块预填充(chunked prefill)、前缀缓存(prefix caching)等推理优化也会改变序列处理方式。
所以在注意力内核执行前,首先要更新 KV 缓存和页表,确保无论序列是否拆分处理(预填充或解码阶段),KV 的存储布局始终一致,从而保障归约顺序不变。

沿着 KV 维度拆分时,也不同于常规策略按照所需并行度均匀拆分 KV 维度,拆分数量随批大小变化,而是固定每个拆分块的大小(如固定为 256),拆分数量随 KV 长度自适应,确保归约顺序不依赖批大小。
研究人员也对此进行了三种不同的实验验证,分别是推理确定性验证、性能验证和真实在线策略强化学习应用验证。
首先使用Qwen/Qwen3-235B-A22B-Instruct-2507 模型,在相同条件下,判断 1000 个长度为 1000 token 的结果差异情况。
结果发现未使用批次不变性内核时,共生成 80 个不同结果,前 102 个 token 完全一致,但到第 103 个 token 则开始分化。
如果使用批次不变性内核,则1000 个结果完全相同,实现了确定性推理。

而在性能上,统一使用单 GPU 部署Qwen-3-8B模型的 API 服务器,并处理相同问题。
结果发现,确定性推理虽存在性能损失,但性能在可接受范围之内,仍然具备实际应用价值。
由于训练与推理的数值差异会导致在线策略 RL 变为离线策略 RL,一般需要引入重要性加权等离线校正项才能稳定训练。

所以通过比对校正前后的数据可以发现,缺乏重要性加权校正时,模型奖励将会在训练中途崩溃,KL 散度也会大幅飙升,而校正后,训练变得稳定,KL 散度可以维持在 0.001 左右,偶有波动情况出现。
确定性推理则全程保持稳定,KL 散度始终为0,实现了真正的在线策略 RL,无需离线校正。
大佬云集的 Thinking Machine
再来说说 Thinking Machine 这支AI 梦之队。
虽然尚未有具体模型产品产出,但是人才和资本都非常豪华,小扎只能干看着,挖也挖不到。
掌舵人 Mira Murati 在 2016 年加入 OpenAI,一路晋升至 CTO,主导打造了 GPT-3、GPT-4 等一系列关键技术开发。

联合创始人及首席科学家 John Schulman 是 PPO 算法的开发者,在强化学习领域举足轻重,还主导了 ChatGPT 的研发工作。

Thinking Machine 的 CTO 则是前 OpenAI 副总裁 Barret Zoph,主导了 ChatGPT 的后训练。

联创 Andrew Tulloch 曾经在 Meta 待了 11 年,后来进入 OpenAI,参与了 OpenAI GPT-4o 到o系列,和 Mira Murati 创办 Thinking Machine 后,面对小扎 6 年 15 亿美元的天价薪酬,也丝毫不动摇

此外,公司还聘请了 GPT 的开山一作 Alec Radford、OpenAI 前首席研究官 Bob McGrew 担任技术顾问。

△左 Alec Radford 右 Bob McGrew
更有北大校友、前 OpenAI 安全团队负责人翁荔加盟,可以说,这支团队约三分之二成员都来自 OpenAI。

前段时间,还有蛛丝马迹表明清华姚班校友陈丹琦也加入了这支团队。
融资方面,今年 6 月,Thinking Machines 完成了 20 亿美元的种子轮投资,由 a16z 领投,英伟达、Accel、ServiceNow、CISCO、AMD、Jane Street 等各领域知名机构纷纷跟投。
以有史以来最大规模的种子轮融资刷新了 AI 圈的融资纪录。(虽然传闻中该公司的融资目标只有 10 亿美元)
这轮融资完成后,这家没模型没产品的初创公司估值也达到了 120 亿美元。
这次新研究发布后,翁荔还透露了第一个 Thinking Machines 产品名为Connection Machine,连接主义。
连接主义缘起于上世纪 60 年代,McCulloch 和 Pitts 提出了人工神经元模型,如今的深度学习可以被视为连接主义的直接延续,当下人工智能中的“神经网络”就是连接主义的实现形式。

这下网友可坐不住了:先把公司 Logo 发出来。

参考链接:
[1]https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/






