不圆发自凹非寺
量子位 | 公众号 QbitAI
腾讯混元世界模型上新,综合能力问鼎 WorldScore 排行榜。

HunyuanWorld-Voyager(简称混元 Voyager),发布即开源。这距离 HunyuanWorld 1.0 Lite 版发布仅过两周。
官方介绍说,这是业界首个支持原生 3D 重建的超长漫游世界模型,能够生成长距离、世界一致的漫游场景,支持将视频直接导出为 3D 格式。
无论是真实街景:

还是像素游戏:
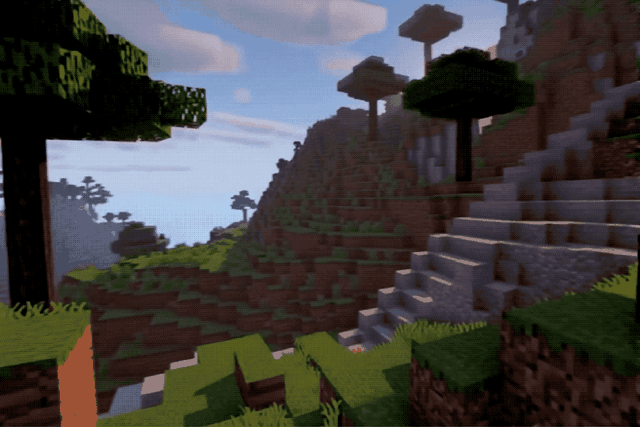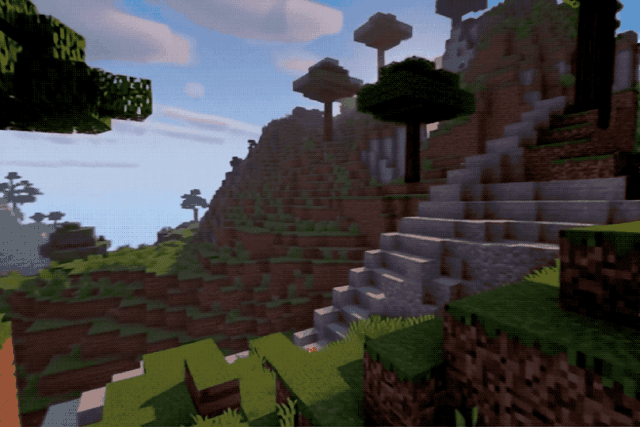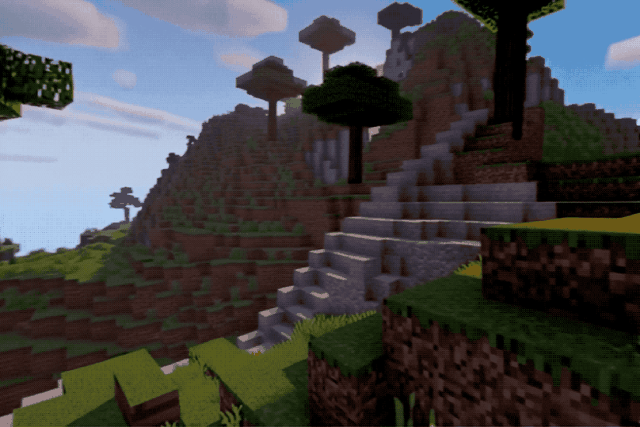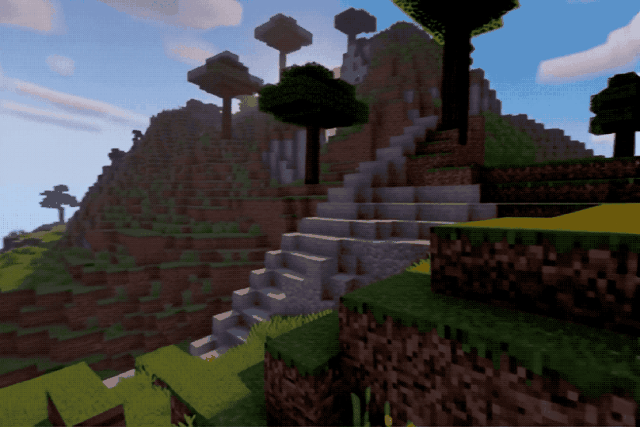
效果都相当不错,不说的话还以为是实拍或者录屏。
它和之前的模型相比有什么不同呢?一起来看一下。
一句话,一张图,一个场景
仔细看了看混元 Voyager 的介绍,这次上新的直观表现其实是多了一个「漫游场景」的功能。
比 360°全景图交互性更强,可以用鼠标和键盘在场景内活动,更好地感受和探索世界。

左边可以调整渲染画质和场视角:

录制 gif 图会压缩画质,实际体验相当清晰。
而且只需要一句话或一张图就可以生成这样的场景。
混元官方还给出了 Prompt 指引:

给出的示例效果也相当不错,体验感很好,甚至想戴个 VR 眼镜试试。
由于文件大小受限,压缩了很多次,截个屏给大家看看原本的画质:

对了,图生场景对图片的分辨率是有要求的,太大或者太小都会报错。


具体要求也给出来了,写得十分清楚:

除此之外,混元 Voyager3D 输入-3D 输出的特性,与此前已开源的混元世界模型 1.0 高度适配,可进一步扩展 1.0 模型的漫游范围,提升复杂场景的生成质量,并可对生成的场景做风格化控制和编辑。

同时混元 Voyager 还可支持视频场景重建、3D 物体纹理生成、视频风格定制化生成、视频深度估计等多种 3D 理解与生成应用,展现出空间智能的潜力。

将场景深度预测引入视频生成过程
混元 Voyager 为什么能够做到一键生成沉浸式漫游场景呢?这个问题涉及到它的模型框架。

混元 Voyager 框架创新性地将场景深度预测引入视频生成过程,首次通过空间与特征结合的方式,支持原生的 3D 记忆和场景重建,避免了传统后处理带来的延迟和精度损失。
同时,在输入端加入 3D 条件保证画面视角精准,输出端直接生成 3D 点云,适配多种应用场景。额外的深度信息还能支持视频场景重建、3D 物体纹理生成、风格化编辑和深度估计等功能。
用比较好理解的话来说,视频生成 +3D 建模——
基于相机可控的视频生成技术,从初始场景视图和用户指定相机轨迹中,合成可自由控制视角、空间连贯的 RGB-D 视频。

混元 Voyager 包含两个关键组件:
(1)世界一致的视频扩散:提出了一种统一的架构,能够基于现有世界观测,同时生成精确对齐的 RGB 视频与深度视频序列,并确保全局场景的一致性。
(2)长距离世界探索:提出了一种高效的世界缓存机制,该机制融合了点云剔除与自回归推理能力,可支持迭代式的场景扩展,并通过上下文感知的一致性技术实现平滑的视频采样。
为训练混元 Voyager 模型,腾讯混元团队还构建了一套可扩展的数据构建引擎——该引擎是一个自动化视频重建流水线,能够对任意输入视频自动估计相机位姿以及度量深度,从而无需依赖人工标注,即可实现大规模、多样化训练数据的构建。
基于此流水线,混元 Voyager 整合了真实世界采集与虚幻引擎渲染的视频资源,构建了一个包含超过10 万个视频片段的大规模数据集。
将基于 1.0 模型生成的初始 3D 点云缓存投影到目标相机视图,即可为扩散模型提供指导。
此外,生成的视频帧还会实时更新缓存,形成闭环系统,支持任意相机轨迹,同时维持几何一致性。这不仅扩展了漫游范围,还为 1.0 模型补充新视角内容,提升整体生成质量。

混元 Voyager 模型在斯坦福大学李飞飞团队发布的世界模型基准测试 WorldScore 上位居综合能力首位,超越现有开源方法。
这一结果表明,与基于 3D 的方法相比,混元 Voyager 在相机运动控制和空间一致性方面表现出优异竞争力。


在视频生成质量上,定性定量结果表明混元 Voyager 具备卓越的视频生成质量,能够生成高度逼真的视频序列。
特别在定性比较的最后一组样例中,只有混元 Voyager 有效保留了输入图像中产品的细节特征。相比之下,其他方法容易产生明显伪影。


场景重建方面,在使用 VGGT 进行后处理的情况下,混元 Voyager 的重建结果优于所有基线模型,表明其生成视频在几何一致性方面表现更为出色。
同时,若进一步使用生成的深度信息来初始化点云,重建效果更佳,这也进一步证明了所提出深度生成模块对于场景重建任务的有效性。
上图中的定性结果同样印证了这一结论。在最后一组样例中,混元 Voyager 能够较好地保留吊灯的细节特征,而其他方法难以重建出基本形状。
同时,在主观质量评价中,混元 Voyager 同样获得最高评分,进一步验证了所生成视频具备卓越的视觉真实性。
并且混元 Voyager 完全开源,相关技术报告已公开,源代码在 GitHub 和 Hugging Face 上免费开放。
模型部署的要求如下:

One More Thing
腾讯混元正在不断加速开源进展,除了包括混元 Voyager 在内的混元世界模型系列,还有 MoE 架构的代表性模型混元 large、混合推理模型 Hunyuan-A13B,以及多个面向端侧场景的小尺寸模型,最小仅 0.5B 参数。
最近还开源了翻译模型Hunyuan-MT-7B和翻译集成模型 Hunyuan-MT-Chimera-7B(奇美拉),前者在国际机器翻译比赛中拿下了 30 个第一名。

除腾讯以外的其它国内大厂也在猛猛开源。
阿里的 Qwen 自不用说,除此外,阿里前段时间还开源了视频生成模型 Wan2.2-S2V。
美团的第一个开源大模型 Longcat-Flash-Chat 最近也发布了,不知道大家有没有关注。
参考链接:https://mp.weixin.qq.com/s/vCkFWwV5vUQhjMRfMQB2XA
项目主页:https://3d-models.hunyuan.tencent.com/world/
模型:https://3d.hunyuan.tencent.com/sceneTo3D
GitHub:https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager






