
新智元报道
编辑:艾伦
在大模型走向深度研究的道路上,高质量数据一直是最大短板。近日,北京智源人工智能研究院发布首个面向深度研究的大规模开源数据集 InfoSeek,并提出了创新性的「扩散-回溯」数据合成方法。基于 5 万条自动生成的高难度训练样本,智源仅用 3B 参数规模的模型,就在 BrowseComp-Plus 基准上取得接近 Gemini 等商业模型的表现!
近日,北京智源人工智能研究院(简称「智源研究院」)发布开源数据集 InfoSeek,成为首个面向深度研究(Deep Research)场景的大规模开源数据集。
在这一工作中,智源研究团队揭示了深度研究问题与层级约束满足问题(Hierarchical Constraint Satisfaction Problem)之间的数学等价关系,并由此提出了基于「扩散-回溯」过程的数据合成方法,实现了深度研究训练数据的大规模自动扩增。
利用上述方法,研究团队总计合成了包含 5 万条训练样本的数据集 InfoSeek,并据此训练出参数规模仅 3B 的智能体模型。
在 BrowseComp-Plus 基准测试中,该模型取得了 16.5% 的准确率,性能已接近 Gemini、Sonnet 4.0 等领先商业模型,充分验证了该方法在深度研究任务上的有效性与潜力。
相关数据集与数据合成方法现已面向社区开放,为推动该领域研究提供了坚实基础。
资源链接:
数据集:
https://huggingface.co/datasets/Lk123/InfoSeek
代码仓库:
https://github.com/VectorSpaceLab/InfoSeek
技术报告:
https://arxiv.org/abs/2509.00375
简介
从撰写行业调研报告到梳理复杂的学术脉络,我们对大模型的期待早已超越了简单的问答。
由此,诞生了「深度研究」(Deep Research)问题。
与传统的 QA 任务不同,这类问题需要更高维度的推理和检索,往往需要重复多轮以下步骤:问题拆解、多元信息获取、结果整合。
然而,模型/智能体在这类任务上的表现尚不尽人意,其中一个关键的障碍是缺乏高质量训练数据。
现有数据集或难度较低,或结构单一,难以教会模型如何像人类专家一样,面对一个庞大而模糊的问题,层层深入,最终找到答案。
为弥补这一缺失,智源研究院推出了一个专为 Deep Research 构建的数据合成框架与首个开源数据集InfoSeek,为推动这一领域的更进一步发展提供了坚实基础。
传统 QA 大多为单一/多约束满足问题(Condition Satisfaction Problem),只需要使用一次或数次检索就能获得答案;
多跳问题(Multi-hop Problem)是 NLP 中一直较有挑战的一类任务,其具有的链式结构,需要依次解决多个单一约束满足问题并推理出最终答案。
如下图所示,基于这两类问题,智源研究院提出将深度研究问题定义为层级约束满足问题(Hierarchical Condition Satisfaction Problem),以涵盖深度研究所具有的多层级、多分枝的复杂结构。

图 1. 各类 QA 任务的定义与示例
基于这一定义,团队设计了能够自动化的智能体 pipeline。
通过「扩散」的方式,从一个根节点出发,构造出 HCSP 的树状结构,并通过「回溯」,从叶子节点倒推回根节点来确认每个 HCSP 的正确性和有效性。

图 2. InfoSeek 构造 HCSP 的智能体流程示意图
智源研究院将这一构造方法,和通过其构造的 50k 条高质量 QA 数据全部开源,并通过使用这一批数据来进行模型训练,在数个难度极高的 QA 基准上验证了 InfoSeek 的有效性。
数据集
智源研究院开源的 InfoSeek 数据集包含超过5 万条样本。其中数据主要集中在需要4–6 中间节点的问题上。为了验证其难度,研究人员使用 Qwen2.5-72B 模型并采用 CoT 进行测试,结果显示其整体失败率高达 91.6%。
值得一提的是,InfoSeek 的数据构造流程支持这一数据集的持续扩容。同时,可以进一步包含更多的中间节点来继续加大问题的难度。
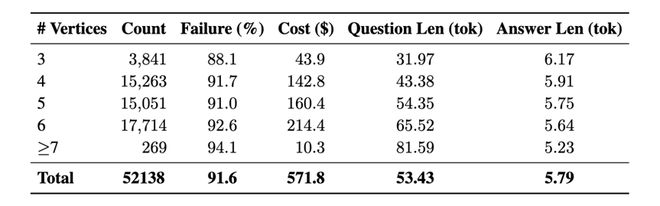
表格 1. InfoSeek 开源数据集统计信息
实验
基于 InfoSeek 训练的模型在 BrowseComp-Plus 上取得了非常突出的成绩。
与没有经过额外微调的 Qwen3,和在传统 QA 数据集 NQ、HotpotQA 上训练的 Search-R1 模型相比,基于 InfoSeek 训练的模型在面对 BrowseComp 中的困难问题时,能够通过大幅提高搜索次数,以检索需要的信息。
其带来的助力也直接体现在了正确率的提升上,16.5% 的准确率取得了当前开源模型的最佳效果,并且能够与 Gemini、Sonnet 4.0 等商业模型媲美。

图 3. 各模型在 BrowseComp-Plus 基准上的表现,基于 InfoSeek 训练的 3B 模型的表现与当前的主流商业模型媲美
同时,以 HotpotQA 等为代表的传统 QA 基准,通过高质量的多跳问题来评估模型进行多轮的推理和检索工具调用的能力。
智源研究院使用 InfoSeek 数据所训练的模型,在多个多跳 QA 的 benchmark 上取得了非常亮眼的表现,进一步验证了 InfoSeek 的有效性。

图 4. 各模型在多跳 QA 基准上的表现
总结
数据的质量决定了模型的高度。
InfoSeek 为开源社区提供了高质量的训练数据和数据合成框架,为未来 Deep Research 的发展提供助力。
智源研究院也会在这一领域持续深耕,未来期待与更多科研机构及产业伙伴合作,共同推动检索与人工智能的发展。
欢迎研究者与开发者关注并使用 InfoSeek 及后续系列工作,共建开放繁荣的开源生态。
https://huggingface.co/datasets/Lk123/InfoSeek






