
新智元报道
编辑:KingHZ
AI 风起云涌,数据隐私如履薄冰。华南理工大学联手深圳北理莫斯科大学,推出 FedMSBA 与 FedMAR,筑成联邦学习的安全堡垒,守护个人隐私!
随着联邦学习在物联网(IoT)系统中的广泛应用,如何在保障数据隐私的同时有效抵御恶意攻击,已成为学界与产业界的共同难题。
针对这一问题,华南理工大学计算机学院与深圳北理莫斯科大学合作,提出了 FedMSBA 和 FedMAR 两种防御方法。
其中,FedMSBA 利用混合差分隐私机制,结合逐层感知方法,为参与方提供了更佳的理论隐私预算。
FedMAR 利用多阶段隐私聚合及更新回滚机制,为服务器提供了针对多种类型恶意用户的防御方法。
论文1:FedMSBA

论文1:IEEE TMC (2025)
论文题目:Privacy-Preserving Rényi Layer-wise Budget Allocation against Gradient Leakage for Federated Learning
第一作者:时乐宇;通讯作者:高英
论文链接:https://ieeexplore.ieee.org/document/11193723
梯度泄露敏感信息,怎么办?
尽管联邦学习不直接传输数据,以「数据可用不可见」的方式对参与方实现了一定程度的隐私保护,但参与方上传的模型梯度仍可能泄露敏感信息。
攻击者可通过梯度反演攻击,从梯度中重构出原始图像甚至文本数据。
传统的单一机制差分隐私防御方法虽然有效,但往往因噪声过大导致模型性能显著下降。
此外,若仅在参与方模型梯度输出中添加噪声,或仅以局部敏感度为依据来添加噪声,则攻击者可以通过去噪等方式逐步了解模型结构,并近似还原原始梯度更新。
由此,大家自然会想到一些问题:在保障同样隐私预算的前提下,如何尽可能减少向原始数据中添加噪声的总量?如何针对模型不同模块的敏感度,来进行分模块的隐私保护?
为了解决这些问题,研究者提出了一种基于Rényi 差分隐私(RDP)的逐层隐私预算自适应分配方法——FedMSBA(Federated Modified Sensitivity Budget Allocation)。
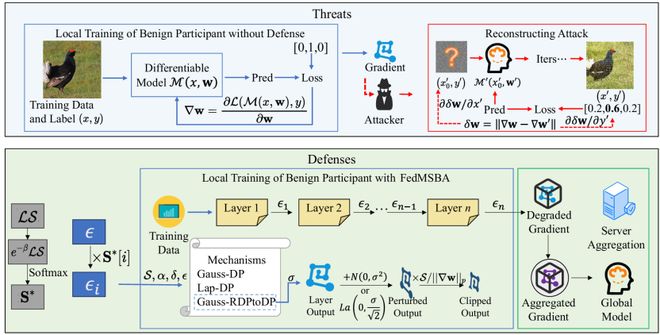
FedMSBA 方法介绍
FedMSBA 的核心理念包括:
1. 分层隐私预算分配:根据不同网络层对输入变化的敏感度,动态分配隐私预算
在参与方的本地模型中,每一层具有不同的局部敏感度,导致了其对攻击者扰动测试的反应大小不同。况且,在每轮本地训练过程中,由于输入不同,这些敏感度有可能发生变化。
因此,依据每层的局部敏感度,分配每层隐私预算,实现「高风险层强保护、低风险层弱扰动」。
2. Rényi 差分隐私:基于 RDP 的隐私计算框架,提供更紧的数学边界,实现更优的隐私-效用平衡
常见的差分隐私机制包括高斯机制和拉普拉斯机制,而 RDP 能够和一般差分隐私建立关系,因此研究者考虑运用在 RDP 来限制最终的隐私预算。
经计算,在一般(Simple)情况和由 RDP 转化为 DP(RDP to DP)情况下,高斯机制和拉普拉斯机制噪声标准差与隐私预算的关系如下:

由于拉普拉斯机制在 RDP to DP 情况不会优于普通拉普拉斯机制,因此研究者直接禁用这一选择。此外,研究者推导出了高斯机制在 RDP to DP 情况下的隐私预算及优于其他机制的条件:


3. 多机制自适应选择:结合高斯与拉普拉斯噪声机制,并根据场景自动选择最优扰动方式
4. 修正敏感度估计:通过蒙特卡洛采样估计局部敏感度,并使用 Softmax 归一化,防止攻击者推测模型结构
计算敏感度需要遍历整个数据集,这样将带来极大开销。为避免遍历整个训练数据集,研究者采用蒙特卡洛采样的方式来近似估算敏感度。
这样的估算会与真实值存在一定误差,然而研究者可以证明这样的误差是可控的。
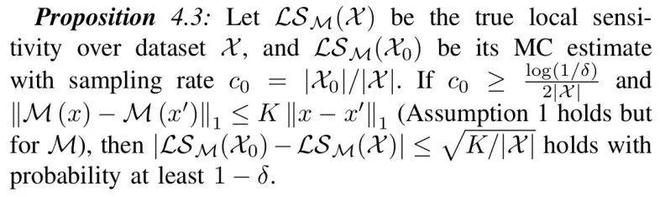
此外,研究者利用 Softmax 来修正敏感度:
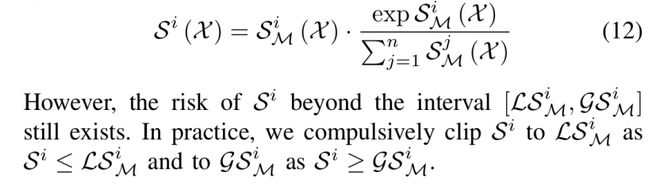
四大突破
FedMSBA 框架在以下几个方面实现了突破:
1. 逐层自适应分配机制:根据不同神经网络层的敏感性,动态分配隐私预算,实现「高风险层强保护、低风险层弱扰动」。
2. Rényi DP 紧致界理论:通过 RDP 的数学性质,在相同隐私预算下可显著减少噪声强度,提高模型可用性。

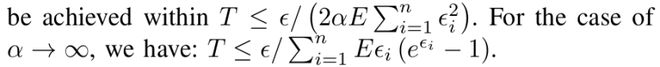
3. 多机制融合与敏感度修正:结合高斯与拉普拉斯机制,并提出改进的「修正敏感度」计算方法,有效抵御梯度泄露攻击。
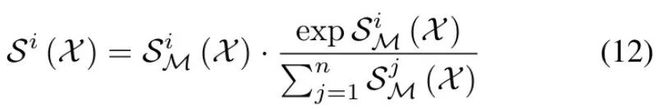
4. 理论完备与收敛保证:论文从隐私界、收敛性、估计误差等方面给出严格证明,确保在有限通信轮次内实现全局 DP 约束。
实验效果:隐私与性能兼得
研究团队在多个数据集(MNIST、Fashion-MNIST、CIFAR-10/100、ImageNet)上验证了 FedMSBA 的有效性:
-
防御效果显著:重构图像的 PSNR 显著降低,MSE 升高,视觉效果模糊难辨;
-
模型性能保持优异:在大多数任务中,测试精度仅轻微下降;
-
适应性强:无论是在 IID 还是 Non-IID 数据分布下,FedMSBA 均表现稳定;
-
资源友好:在边缘设备上运行时间与内存开销均控制在可接受范围内。
FedMSBA 是在联邦学习中参与方隐私保护方向上的一个进一步探索。它在一定程度上弥补了现有方法在理论隐私保障上的不足。
研究团队致力于构建一个联邦学习系统的通用隐私保护框架。
FedMSBA 为参与方提供了更高级别、更自适应的隐私保护,却没有考虑服务器的隐私保护问题。与参与方不同,服务器承担大量通信和计算任务,又无权直接访问训练数据。针对这些特性,研究团队为服务器端设计了另一个隐私保护措施 FedMAR,旨在进一步降低隐私计算开销及从恶意本地更新中及时恢复。
论文2:FedMAR

论文2:IEEE IoT (2025)
论文题目:FedMAR: A Privacy-Preserving and Robust Server-Side Multi-Stage Federated Learning
第一作者:时乐宇;通讯作者:高英
论文链接:https://ieeexplore.ieee.org/document/11129099
服务器端如何保护隐私?
联邦学习在实际部署中常面临多种安全与隐私威胁,如数据投毒、模型中毒、梯度泄露和搭便车攻击等。
这些攻击不仅影响模型性能,也可能引发错误决策。值得注意的是,真实物联网环境中这些威胁往往交织出现,而非孤立发生。现有防御方法大多针对单一攻击类型设计,在复合攻击场景下容易失效。
针对上述问题,研究团队考虑了下列攻击同时存在的一类 IoT 环境:
1. 恶意参与方可能通过数据投毒攻击(Data Poisoning Attack)或标签翻转攻击(Label Flipping Attack)干扰训练过程,使得全局模型精度下降甚至失效。在这里,研究者将数据投毒攻击和标签反转攻击视作同一类型;
2. 部分参与方可能实施搭便车攻击(Free-rider Attack),即不上传有价值的更新,却依赖服务器下发的全局模型牟利;
3. 梯度泄漏攻击(Gradient Leakage Attack) 等隐私威胁也可能导致训练数据被逆向重建。
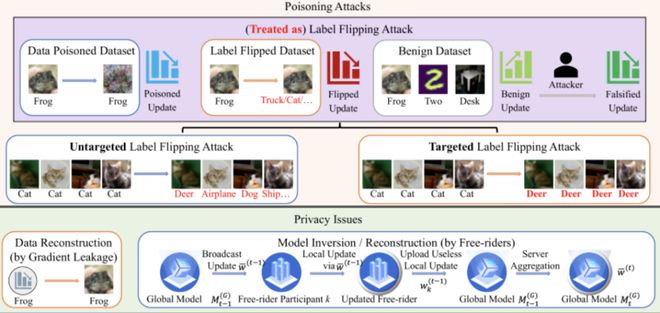
针对上述问题,研究者提出了一种适用于物联网环境的多阶段自适应鲁棒聚合联邦学习防御框架——FedMAR(Federated Multi-stage Asynchronous Roll-back),相关成果已被 IEEE Internet of Things Journal 录用。
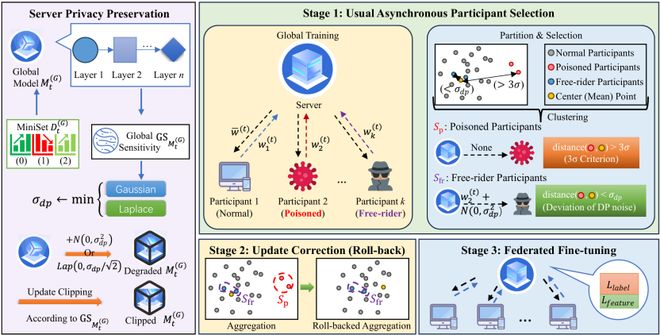
FedMAR 方法介绍
FedMAR 的核心理念是:
1. 多阶段聚合与回滚机制:在服务器端动态检测异常更新,并通过「回滚」操作削弱其影响,从而保证全局模型的鲁棒性。
研究者通过各个参与方之间的「距离」来区分正常参与方与被投毒的参与方,这个「距离」可以用参与方所上传的更新来进行计算。
在完成中心点计算后,研究者可以利用3σ准则来完成被投毒参与的甄别。
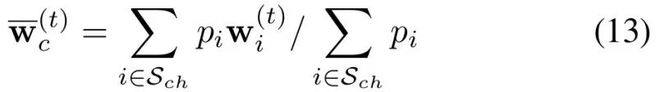
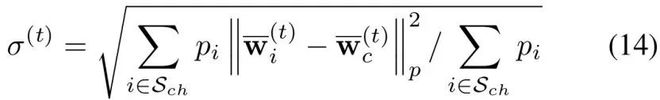
经过推导,可以利用如下策略将一个参与方的更新从全局更新中完全剔除,即本文中的「回滚」策略:
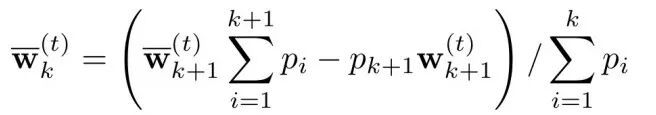
2. 基于Rényi 差分隐私(RDP)的隐私保护:与传统差分隐私相比,RDP 能够在相同预算下添加更小幅度的噪声,既提升了隐私保障,也避免了过度牺牲模型性能。
3. 搭便车攻击检测机制:通过引入聚合中心点与噪声偏差标准,FedMAR 可以有效识上传几乎无效参数却想获取全局模型的攻击者。
3σ准则能够甄别被投毒的参与方,但却对实施「搭便车攻击」的参与方无能为力。
然而,搭便车攻击的参与方为了掩藏自己不提供任何有效更新的事实,通常会令自身提供的更新尽可能与聚合后的「中心点」接近。因此,距离中心点太近的参与方极有可能是在进行搭便车攻击的。
4. 鲁棒与隐私的动态平衡:FedMAR 框架尝试在提升鲁棒性的同时兼顾隐私保护,以应对物联网中的复杂环境。
突破与创新
FedMAR 框架在以下几个方面实现了突破:
1. 鲁棒聚合策略:通过多方自适应加权机制,能够自动识别并削弱恶意客户端的影响,从而提升全局模型的鲁棒性。
2. 隐私保护:结合 RDP,在降低注入噪声强度的同时,提供了更紧的隐私保障。
3. 理论与实验并重:提供了严谨的安全性分析,并在多个真实数据集(如 CIFAR-10、MNIST 等)上进行了实验验证。
理论亮点
1. RDP 机制的优化与界定:给出了噪声标准差与隐私预算的解析关系,并通过近似推导解决了 Laplace 机制在机器计算中易出现溢出的难题。
这一部分工作使得在相同隐私预算下,可以自适应地选择更优的噪声机制,从而实现理论与实际的双重优化。

2. 鲁棒性与隐私保护的统一框架:研究者并没有将「安全鲁棒性」和「隐私保护」分开处理,而是建立了一个可平衡两者的统一理论框架。
在这个框架中,鲁棒性部分通过「3σ准则+回滚机制」给出了形式化定义,隐私部分通过 RDP 给出了数学化约束,最终实现了鲁棒性与隐私性的动态平衡。
实验亮点
-
在面对多种投毒攻击场景时,FedMAR 能够有效保持模型精度,相比传统方法取得了一定的提升。
-
在隐私预算有限的情况下,FedMAR 也能够减少精度损失。
-
在非良性参与方识别任务中,FedMAR 的检测准确率、召回率和 F1-score 上表现稳定。
FedMAR 是在联邦学习安全与隐私保护方向上的一个阶段性尝试。它在一定程度上弥补了现有方法在复合攻击环境中的不足。
未来,研究者还将继续探索如何进一步降低算法开销、提升跨设备兼容性,以推动联邦学习在真实物联网场景中的稳健落地。
参考资料:






